上一篇
hive数据仓库规划
Hive数据仓库规划需明确需求,设计分层架构(ODS/DW/DM),优化存储格式(ORC/Parquet),强化元数据管理,严格权限控制,并针对性能瓶颈进行SQL调优与
Hive数据仓库规划详解
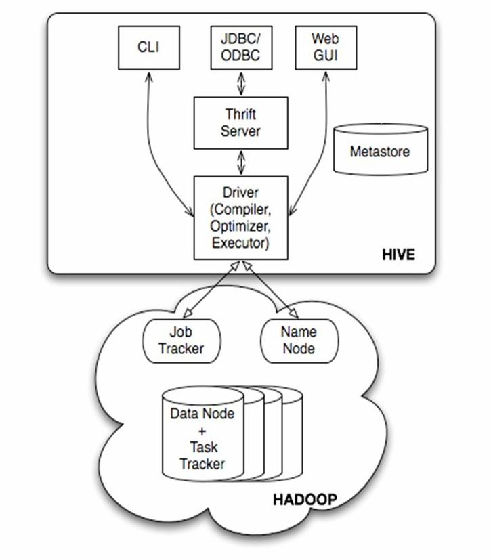
Hive作为大数据生态中的核心组件,其数据仓库规划直接影响数据存储效率、查询性能及业务支撑能力,以下从架构设计、数据建模、存储管理、性能优化等维度展开详细分析。
Hive数据仓库架构设计
Hive数据仓库通常采用分层架构,以满足不同业务场景需求并提升可维护性,典型分层如下:
| 层级 | 功能描述 | 数据特征 |
|---|---|---|
| 操作数据层(ODS) | 存储原始业务数据,保留数据原始面貌,支持快速加载和恢复。 | 数据未经清洗,可能存在冗余和异常 |
| 公共维度模型层(CDM) | 构建通用维度和事实表,供上层应用共享,避免重复加工。 | 高度规范化,包含核心业务指标和维度属性 |
| 应用数据层(ADS) | 面向具体业务需求设计的数据集,如报表、分析主题等,数据轻量化且贴近业务逻辑。 | 数据聚合度高,支持快速查询 |
示例场景:
假设业务方需要分析用户行为日志,数据流转路径为:
- ODS层:直接加载日志文件(如JSON、CSV格式),保留原始字段。
- CDM层:基于ODS数据清洗后生成
user_dim(用户维度表)、event_fact(事件事实表)。 - ADS层:通过SQL聚合生成
user_active_summary(用户活跃度汇总表),供BI工具调用。
数据建模方法论
Hive数据仓库建模需平衡灵活性、性能和业务需求,常用方法包括:
维度建模(推荐)
- 适用场景:以分析查询为主,需快速响应的业务(如OLAP)。
- 核心概念:
- 事实表:存储业务事件量化数据(如订单金额、点击次数)。
- 维度表:存储事实表关联的上下文信息(如时间、地区、用户属性)。
- 优势:星型/雪花模型结构简单,JOIN操作高效,易于扩展。
范式建模(谨慎使用)

- 适用场景:需保证数据一致性且更新频繁的场景(如交易系统)。
- 风险:过度范式化会导致查询时多表JOIN,降低Hive查询性能。
最佳实践:
- 事实表设计时,优先选择“宽表”策略,将常用维度直接冗余存储(如订单表中包含
user_id而非关联用户表)。 - 维度表字段需包含完整生命周期信息(如
start_date和end_date),支持时间范围查询。
存储管理与分区策略
Hive存储格式和分区策略直接影响IO性能和查询效率:
| 配置项 | 建议方案 | 理由 |
|---|---|---|
| 文件格式 | ORC/Parquet(列式存储) | 压缩效率高,支持列式裁剪(减少IO) |
| 分区字段 | 时间(如dt)、业务类型(如biz_type) | 按需过滤数据,避免全表扫描 |
| Bucket(桶)分配 | 对高频查询字段(如user_id)哈希分桶 | 提升JOIN和GROUP BY性能 |
示例:
CREATE TABLE event_fact ( event_id BIGINT, user_id BIGINT, event_time TIMESTAMP, ... ) PARTITIONED BY (dt STRING) -按日期分区 CLUSTERED BY (user_id) INTO 16 BUCKETS; -按用户ID分桶
性能优化关键措施
SQL执行优化
- 避免全表扫描:利用分区裁剪(
WHERE dt='2023-10-01')和列式存储裁剪(仅SELECT需要的列)。 - 复杂逻辑前置:在ETL阶段完成数据清洗,减少Hive SQL中的
CASE、DECODE等运算。
- 避免全表扫描:利用分区裁剪(
资源配置调优
- 调整
mapreduce.job.reduces:根据数据量动态设置Reducer数量(如SET mapreduce.job.reduces=10;)。 - 启用并行执行:设置
set hive.exec.parallel=true;以加速多作业执行。
- 调整
数据倾斜处理
- 现象:某Reducer处理数据量远大于其他节点,导致任务卡顿。
- 解决方案:
- 预处理阶段打散倾斜键(如对
user_id添加随机前缀)。 - 调整Hive参数:
set hive.groupby.skewindata=true;启用Map端聚合。
- 预处理阶段打散倾斜键(如对
安全与权限管理
鉴权机制
- 启用Kerberos认证,确保Hive服务间通信安全。
- 使用Hive的
GRANT语句精细化权限控制(如GRANT SELECT ON TABLE sales_fact TO ROLE analyst;)。
数据脱敏
在ETL过程中对敏感字段(如手机号、身份证号)进行加密或掩码处理。
监控与维护
元数据管理
- 定期执行
MSCK REPAIR TABLE修复分区元数据,避免查询时漏扫新分区。 - 使用
ANALYZE TABLE命令收集统计信息,优化查询计划。
- 定期执行
数据质量检查
- 通过断言(
ASSERT)或自定义UDF校验数据完整性(如检查时间字段格式)。 - 建立数据血缘追踪体系,记录ETL任务依赖关系。
- 通过断言(
FAQs
Q1:Hive分区过多会导致什么问题?如何解决?
A1:分区过多会导致NameNode压力增大、查询扫描路径变长,解决方案包括:
- 合并历史分区(如将
dt粒度从天调整为周)。 - 使用动态分区但限制单次创建数量(
set hive.exec.dynamic.partition=nonstrict;)。
Q2:如何优化Hive小文件过多导致的性能问题?
A2:小文件过多会占用大量HDFS Block并降低并行度,优化方法:
- ETL阶段合并小文件(
SET hive.merge.mapfiles=true;+SET hive.merge.mapredfiles=true;)。 - 调整
mapreduce.input.fileinputformat.split.minsize参数(如设置为256MB)。