上一篇
分布式数据库好不好
分布式数据库具有高可用性、可扩展性和容错性,适合大数据与高并发场景;但架构复杂,需处理数据一致性,运维成本较高,综合来看,其优势显著,适用于
全面解析与深度探讨
分布式数据库是一种通过将数据分散存储在多个物理节点上,并通过网络进行协同管理的数据库系统,随着互联网技术的发展和数据量的爆炸式增长,分布式数据库逐渐成为企业级应用的主流选择,但其是否“好”需要结合具体场景、技术需求和业务目标来综合评估,以下从多个维度分析分布式数据库的优劣势、适用场景及潜在挑战。
分布式数据库的核心优势
| 优势 | 详细说明 |
|---|---|
| 高可用性 | 数据自动冗余存储,节点故障时可快速切换,避免单点故障导致的服务中断。 |
| 横向扩展能力 | 通过增加节点实现性能和容量的线性扩展,支持海量数据处理(如PB级数据)。 |
| 地理分布支持 | 数据可部署在不同地域,满足全球化的业务需求,降低延迟并提升用户体验。 |
| 容灾能力强 | 多副本机制和自动故障转移,确保极端情况下(如机房宕机)的数据安全和服务连续性。 |
| 成本优化 | 利用廉价硬件集群替代高端服务器,分摊存储和计算压力,长期运维成本更低。 |
典型场景:
- 互联网巨头(如电商、社交平台)需要处理高并发请求和海量数据。
- 金融、电信等行业对高可用性和容灾有严格要求的业务。
- 全球化企业需要低延迟访问不同区域的数据。
分布式数据库的潜在劣势
| 劣势 | 详细说明 |
|---|---|
| 复杂度高 | 架构设计、数据分片、负载均衡等需要专业技术,运维门槛显著高于传统数据库。 |
| 一致性挑战 | 分布式系统中存在CAP定理的权衡(如强一致性可能牺牲可用性),需根据业务取舍。 |
| 网络依赖性强 | 节点间通信依赖网络稳定性,高延迟或抖动可能影响性能(如跨地域部署)。 |
| 成本初期投入高 | 硬件采购、软件授权、运维团队建设等前期成本较高,中小企业可能难以承受。 |
| 事务管理复杂 | 分布式事务(如两阶段提交)可能降低性能,需权衡事务一致性与系统吞吐量。 |
典型问题案例:
- 某电商平台在促销活动中因分片策略不合理导致部分节点过载,出现服务卡顿。
- 跨国企业因网络延迟导致跨区域数据同步时间过长,影响实时分析结果。
与传统数据库的对比
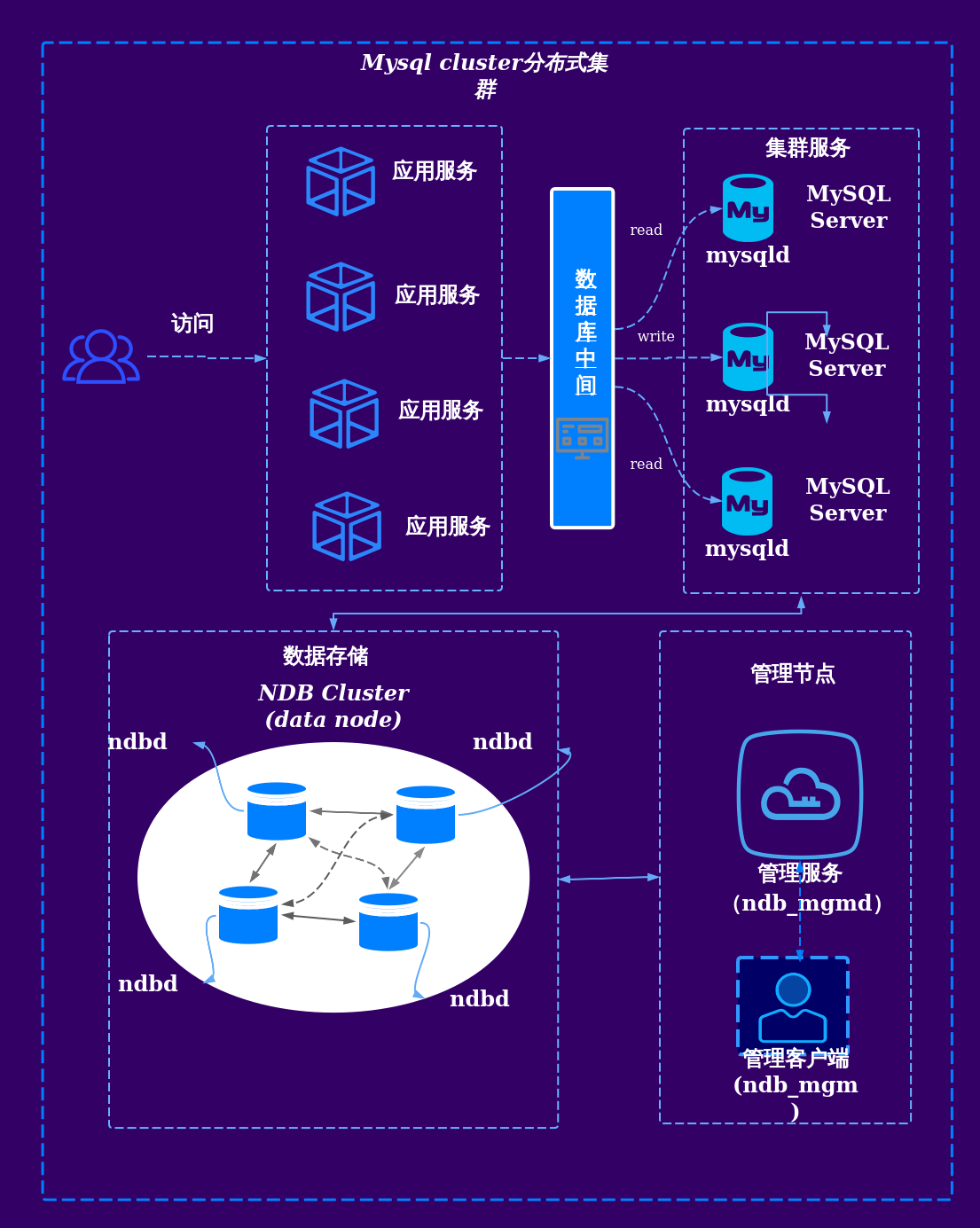
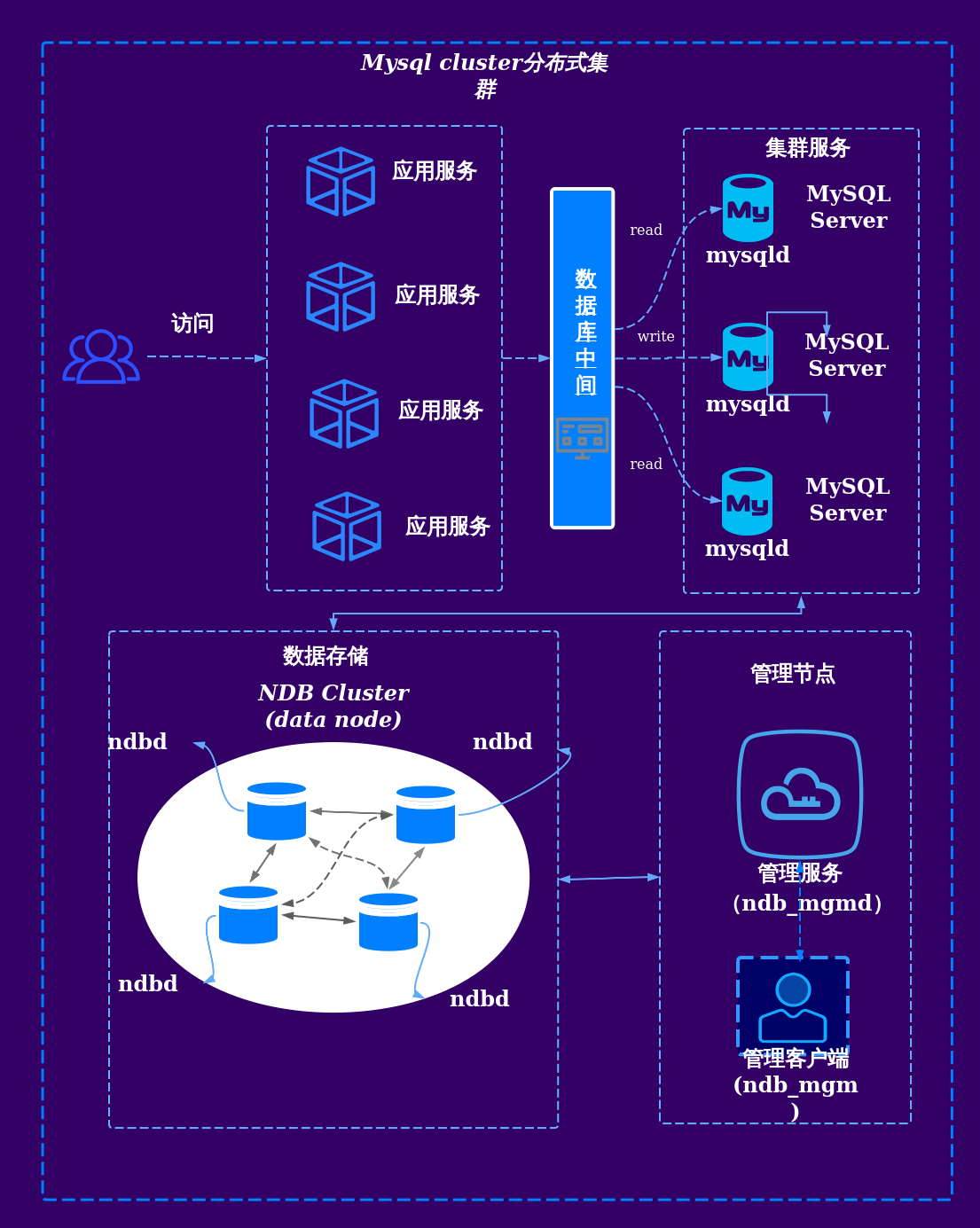
| 维度 | 传统数据库(如MySQL、Oracle) | 分布式数据库(如TiDB、CockroachDB) |
|---|---|---|
| 架构 | 单节点或主从架构,扩展依赖手动分库分表。 | 多节点集群,自动分片和负载均衡。 |
| 扩展性 | 垂直扩展(硬件升级),扩展成本高且上限明显。 | 水平扩展(加节点),扩展灵活且成本可控。 |
| 可用性 | 依赖主备切换,RTO/RPO较高。 | 多副本自动切换,RTO/RPO接近零。 |
| 一致性 | 天然支持ACID事务,强一致性。 | 需通过协议(如Paxos/Raft)实现最终一致。 |
| 适用场景 | 中小型业务、低并发、对延迟敏感的场景。 | 大规模高并发、全球化部署、高可用需求场景。 |
适用场景与不适用场景
适合使用分布式数据库的场景:

- 数据量巨大:如日志分析、用户行为追踪等EB级数据存储需求。
- 高并发访问:瞬秒、抢购等瞬时峰值流量场景。
- 全球化业务:需要低延迟访问不同区域数据(如CDN节点数据同步)。
- 高可用要求:金融交易、电信计费等不能容忍长时间停机的业务。
不适合使用分布式数据库的场景:
- 小规模数据:如创业公司初期数据量小、并发低,传统数据库更简单高效。
- 强一致性事务:对每笔交易强一致性要求极高的场景(如银行核心账务系统)。
- 预算有限:中小企业可能难以承担分布式数据库的硬件和运维成本。
核心挑战与解决方案
数据分片策略:
- 问题:分片规则不合理可能导致数据热点或倾斜。
- 方案:采用哈希分片、范围分片或混合策略,结合动态迁移工具(如TiDB的Region调度)。
一致性保障:
- 问题:CAP定理下需在一致性、可用性、分区容忍中权衡。
- 方案:根据业务选择合适协议(如Base理论、Raft算法),或采用分层架构(如本地强一致+全局最终一致)。
运维复杂度:
- 问题:集群监控、故障排查、性能调优难度大。
- 方案:使用云厂商托管服务(如AWS Aurora)、自动化运维工具(如Prometheus+Grafana监控)。
分布式数据库的“好”与“坏”
分布式数据库并非万能,但其在高可用、扩展性和容灾方面的优势,使其成为大型互联网企业和全球化业务的最优解,其复杂度、成本和一致性挑战也决定了它并不适合所有场景,企业需根据自身业务规模、技术能力和长期规划,在传统数据库与分布式数据库之间做出理性选择。
FAQs
Q1:分布式数据库和集中式数据库的主要区别是什么?
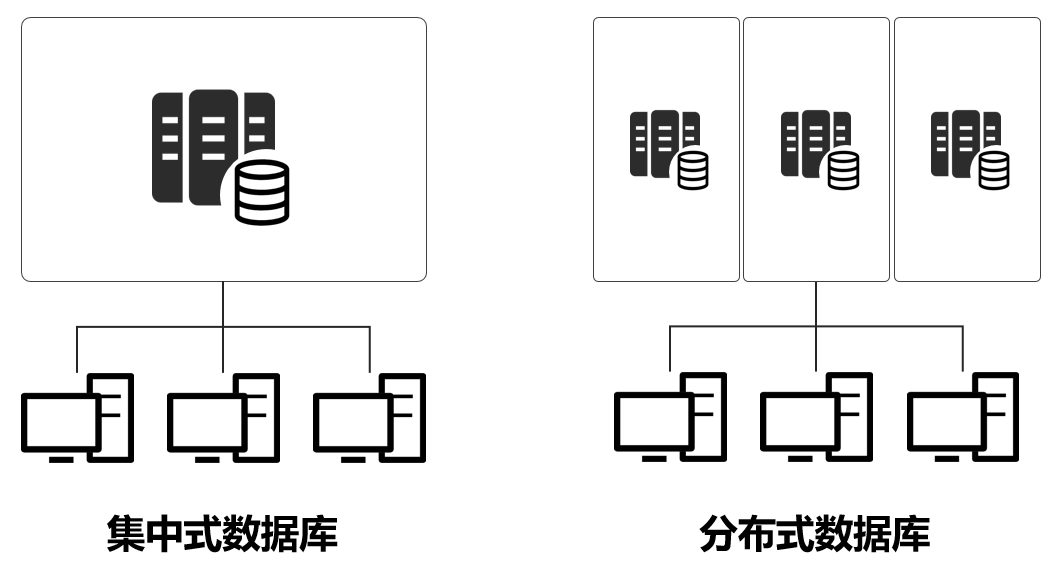
A:集中式数据库依赖单节点或主从架构,扩展性差且存在单点故障风险;分布式数据库通过多节点协同,支持水平扩展、自动容灾和地理分布,但复杂度更高。
Q2:如何选择适合的分布式数据库产品?
A:需考虑以下因素:
- 业务规模:数据量、并发量是否达到分布式阈值。
- 一致性需求:是否需要强一致性(如金融)或可接受最终一致(如日志)。
- 成本预算:硬件、软件授权和运维投入是否可控。
- 生态支持:是否兼容现有技术栈(如MySQL语法、Kubernetes集成)。
推荐通过PoC(概念验证)测试实际场景表现,再