上一篇
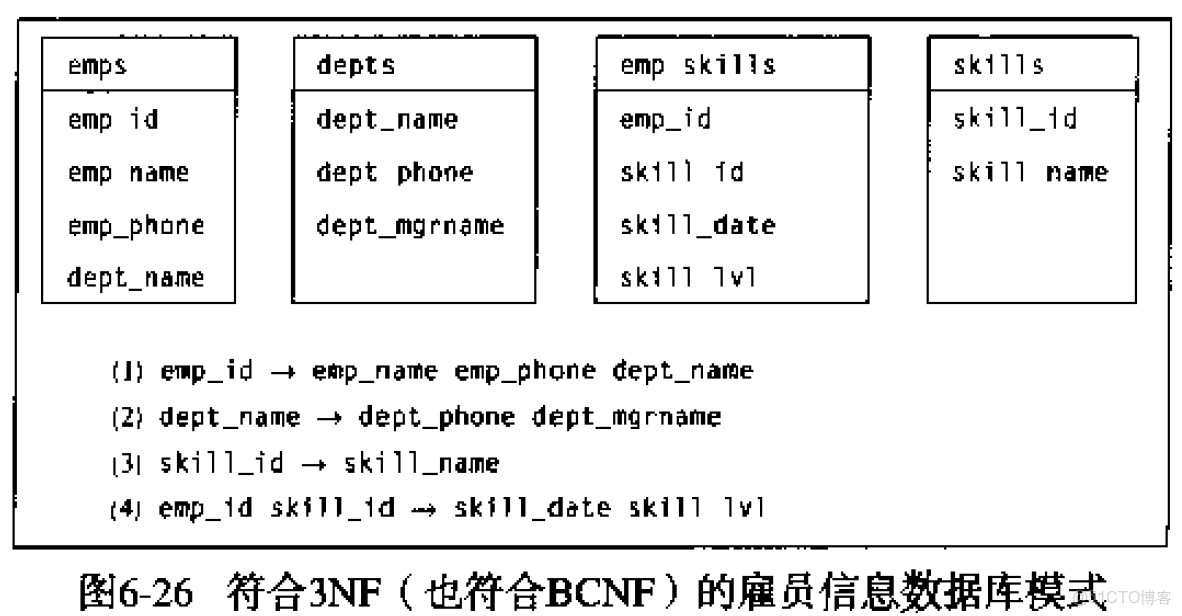
分布式数据库数据表
分布式数据库数据表通过分片存储实现水平扩展,采用多副本机制保障高可用,支持哈希/范围等分区策略,结合CAP理论权衡一致性与分区容忍,最终一致模型适应分布式场景,提升系统吞吐量与容灾
分布式数据库数据表核心解析
分布式数据库数据表特性
分布式数据库通过将数据分散存储在多个物理节点上实现横向扩展,其数据表设计与传统单机数据库存在显著差异,以下是关键特性对比:
| 特性 | 传统数据库 | 分布式数据库 |
|---|---|---|
| 数据存储 | 单一节点集中存储 | 多节点分片存储 |
| 扩展方式 | 纵向扩展(硬件升级) | 横向扩展(增加节点) |
| 事务管理 | 单节点ACID事务 | 分布式事务(BASE理论) |
| 查询路由 | 单一路径 | 需计算数据分片位置 |
| 故障恢复 | 依赖备份还原 | 自动故障转移+数据副本 |
数据分片策略
数据分片是分布式数据库的核心设计,常见策略包括:
哈希分片
- 原理:使用哈希函数对分片键取模
- 示例:
user_id % 4将数据分配到4个节点 - 优势:均匀分布,避免热点
- 缺陷:范围查询效率低,分片键不可修改
范围分片
- 原理:按时间/数值区间划分
- 示例:按日期分片:2023-01,223-02…
- 优势:支持高效范围查询
- 风险:数据热点(如最新数据集中访问)
列表分片
- 原理:预定义枚举值分配
- 示例:地区分片:北京→节点A,上海→节点B
- 适用场景:维度固定且变化少的业务
复合分片
- 策略组合:哈希+范围(如先按地区列表分片,再按用户ID哈希)
- 优势:兼顾多种查询模式
- 复杂度:管理成本较高
数据一致性保障机制
在CAP定理约束下,分布式数据库需要权衡:
强一致性方案
- 2PC协议:牺牲可用性保证一致性(如XA事务)
- Paxos算法:多数派共识机制(如etcd/ZooKeeper)
- 适用场景:金融交易等严一致性需求
最终一致性方案
- 数据版本控制:记录多版本数据
- 冲突检测:乐观锁/向量时钟
- 典型应用:社交媒体点赞、日志收集系统
一致性级别对比

| 级别 | 描述 | 适用场景 |
|---|---|---|
| 强一致性 | 所有节点实时同步 | 金融交易 |
| 读写一致性 | 读操作能看到最新写 | 订单系统 |
| 会话一致性 | 单次会话内保证一致 | 购物车结算 |
| 最终一致性 | 允许短暂不一致,最终收敛 | 日志分析 |
数据冗余与副本管理
为保证高可用,分布式数据库普遍采用数据副本机制:
副本类型
- 主从副本:1主+N从(MySQL集群)
- 多主副本:所有副本均可写(Cassandra)
- Paxos副本:多数派写入(CockroachDB)
副本一致性协议
- 同步复制:性能损耗但强一致(写入延迟↑)
- 异步复制:高性能但存在数据丢失风险
- 半同步复制:折衷方案(等待多数节点确认)
副本选择策略
- 就近访问:优先选择同机房副本
- 负载均衡:轮询或权重分配
- 故障转移:主节点故障时自动切换
分片键设计原则
分片键选择直接影响系统性能:
理想分片键特征
- 高基数(减少热点)
- 业务查询高频字段
- 数据均匀分布
- 不可变/极少变更
反模式案例
- 使用UUID:随机分布导致范围查询失效
- 使用时间戳:热点写入(新数据集中)
- 使用可变字段:如用户状态(VIP/普通)
复合分片键设计
- 示例:电商订单表
(order_type, user_id) - 优势:兼顾查询模式和数据分布
- 注意:需评估组合字段的基数
全局索引与跨节点查询
分布式环境下索引实现面临挑战:
本地索引
- 每个分片独立创建索引
- 查询需路由到各分片执行
- 问题:跨分片JOIN性能差
全局二级索引
- 维护独立索引表
- 记录(主键,索引键)映射关系
- 代价:额外存储空间和同步开销
查询优化策略
- 预计算聚合:提前生成统计结果
- 数据预聚合:物化视图技术
- 查询拆分:并行执行子查询
典型应用场景设计
电商订单系统
- 分片键:
user_id(哈希分片) - 副本策略:3副本(跨AZ部署)
- 索引优化:
order_time建立本地索引 - 热点处理:新用户引导至冷分片
社交网络Feed流
- 分片键:
fanout_key(用户关注列表哈希) - 数据副本:5个跨区域副本
- 索引设计:
create_time范围索引 - 一致性:最终一致性(内容传播延迟<500ms)
常见问题与解决方案
数据倾斜问题
- 现象:部分分片负载过高
- 解决:
- 动态分片调整(在线rebalance)
- 虚拟分片(每个物理分片包含多个逻辑分片)
- 热点数据单独处理(如缓存层)
跨节点事务处理
- 挑战:2PC协议性能瓶颈
- 方案:
- 分阶段提交(TCC模式)
- 补偿机制(最终一致性)
- 事务拆分(避免跨分片)
数据迁移影响
- 风险:迁移期间读写冲突
- 策略:
- 双写模式(新旧分片同步)
- 灰度迁移(逐步切换流量)
- 版本控制(记录迁移状态)
FAQs
Q1:如何选择分布式数据库的分片键?
A:应遵循三个原则:①高频查询字段优先;②确保数据均匀分布;③选择不可变或极少变更的字段,例如电商系统可选user_id,社交系统可选fanout_key,IoT场景可选device_id,避免使用会频繁变化的字段(如用户状态),且需评估字段基数(建议>1000)。
Q2:如何处理跨分片的联表查询?
A:推荐以下方案:①业务层拆分查询,分别获取数据后合并;②利用全局二级索引预先构建关联数据;③采用计算下推策略,让各分片并行处理局部数据;④重新设计数据模型,通过冗余存储避免联表,例如订单-用户信息可通过数据预热到同一