上一篇
分布式数据库数据同步方法
分布式数据库数据同步方法包括主从/多主复制、基于日志(如WAL)同步、时间戳向量、CRDT及共识算法(如Raft),通过事务一致性协议保障
分布式数据库数据同步方法详解
在分布式数据库系统中,数据同步是确保多个节点间数据一致性的核心技术,随着业务规模的扩大和高可用性需求的增长,如何高效、可靠地实现数据同步成为关键挑战,以下是主流的数据同步方法及其特点分析。
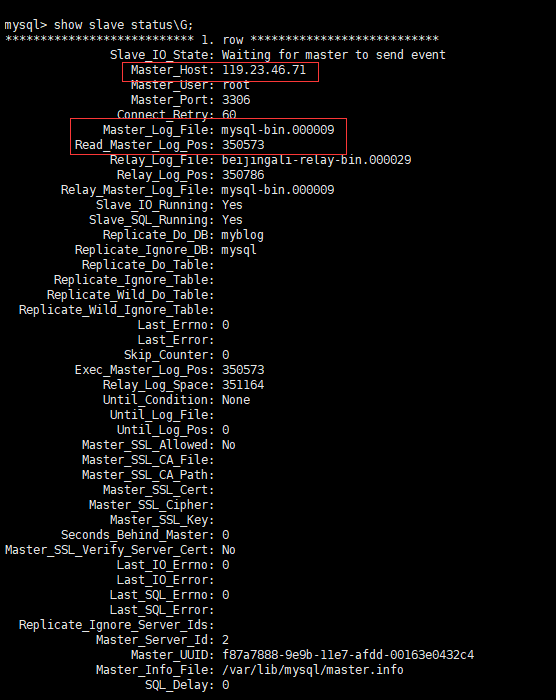
主从复制(Master-Slave Replication)
原理:
主节点(Master)负责处理写操作,并将数据变更记录(如二进制日志)同步到从节点(Slave),从节点通过重放日志或直接读取主节点数据来保持与主节点的一致性。
分类:
- 异步复制:主节点不等待从节点确认即完成写入,性能高但存在数据丢失风险。
- 半同步复制:主节点需至少一个从节点确认接收日志后才完成写入,平衡性能与一致性。
- 同步复制:主节点等待所有从节点确认,强一致性但延迟高。
优点:
- 架构简单,易于实现(如MySQL、MongoDB默认支持)。
- 读写分离提升读性能。
缺点:
- 主节点成为单点瓶颈和故障点。
- 异步复制可能导致数据不一致(如主节点故障时未同步的数据丢失)。
适用场景:
对一致性要求不高、读多写少的场景(如缓存同步、日志收集)。
多主复制(Multi-Master Replication)
原理:
所有节点均可处理读写请求,通过冲突检测和分辨率机制(如版本向量、时间戳)解决并发冲突,典型算法包括:
- Paxos/Raft协议:通过选举领导者协调数据一致性。
- 冲突自由复制(CFR):依赖唯一标识符或哈希分片避免冲突。
优点:
- 无单点故障,高可用性。
- 支持地理分布部署。
缺点:
- 冲突解决复杂,需额外开销。
- 写性能随节点数增加而下降。
适用场景:
金融交易、全球化业务等需要高可用性和多活节点的场景(如Google Spanner、CockroachDB)。
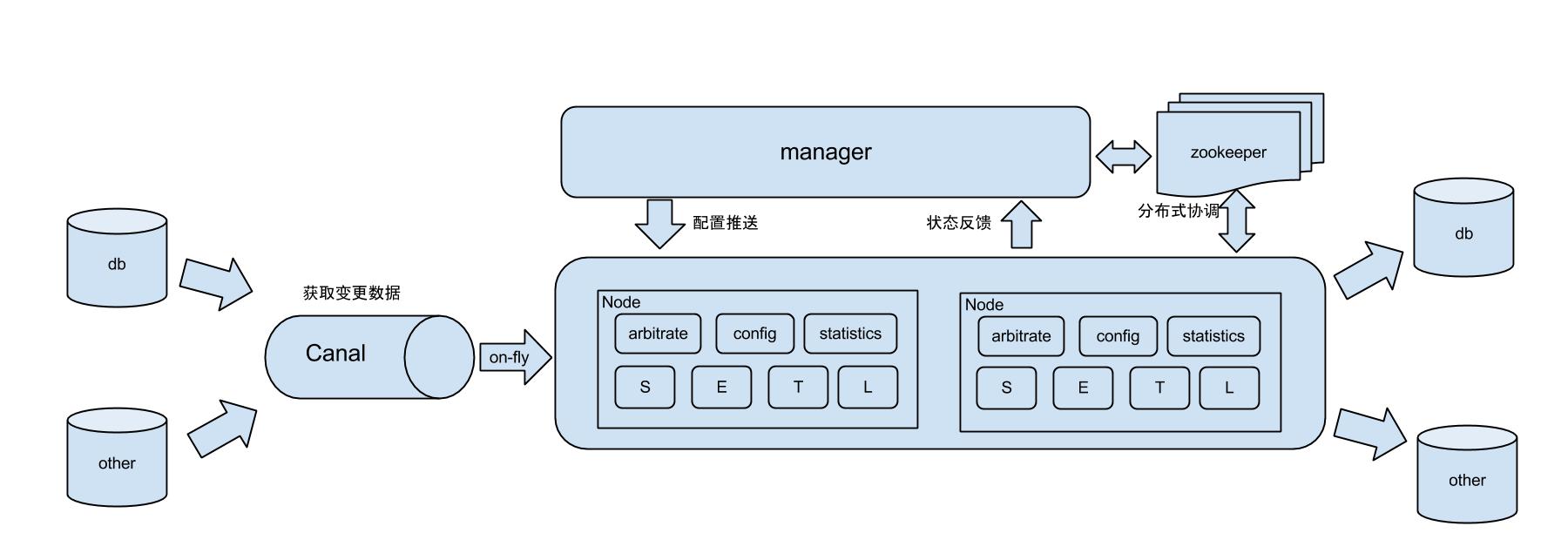
基于日志的增量同步(Log-Based Incremental Replication)
原理:
通过捕获数据变更日志(如WAL,Write-Ahead Logging),将操作序列传输到目标节点并重放。
- Debezium:基于Kafka流式处理数据库变更事件。
- Change Data Capture (CDC):记录行级变更并同步。
优点:
- 细粒度同步,减少数据传输量。
- 支持实时或近实时同步。
缺点:
- 依赖日志可靠性,日志损坏可能导致同步失败。
- 需要处理日志格式兼容性问题。
适用场景:
数据频繁更新、需要低延迟同步的场景(如实时数据分析、跨库同步)。
流式数据同步(Stream-Based Replication)
原理:
利用消息队列(如Kafka、RabbitMQ)作为数据变更的中间管道,源节点将变更事件发布到流,目标节点订阅并消费。
特点:
- 解耦架构:源与目标节点独立扩展。
- 持久化:消息队列可存储未处理事件,避免数据丢失。
优点:
- 高吞吐量、低延迟。
- 支持多目标同步(如同步到多个数据中心)。
缺点:
- 依赖外部组件,架构复杂度高。
- 需保证消息顺序性(如Kafka的分区机制)。
适用场景:
大规模数据同步、ETL管道、跨系统数据集成(如Apache Kafka + Flink生态)。
混合同步策略(Hybrid Synchronization)
原理:
结合多种同步模式,
- 主从+流式:主从复制保障基础一致性,流式同步处理增量数据。
- 多主+最终一致性:通过Quorum机制(如多数派共识)实现最终一致。
典型方案:
- Amazon Aurora:主从复制+日志同步,结合Paxos协议实现秒级恢复。
- TiDB:多Raft组复制,支持强一致性和高可用性。
优点:
- 灵活适配不同业务需求。
- 提升容灾能力和性能。
缺点:
- 实现复杂,运维成本高。
适用场景:
大型分布式系统、金融级高一致性要求场景。
同步方法对比表
| 方法 | 一致性级别 | 延迟 | 复杂度 | 单点故障风险 | 典型应用 |
|---|---|---|---|---|---|
| 主从复制(异步) | 最终一致 | 低 | 低 | 高(主节点) | MySQL、Redis |
| 主从复制(半同步) | 强一致(部分) | 中 | 中 | 中(主节点) | Percona XtraDB |
| 多主复制 | 强一致/最终一致 | 高 | 高 | 低 | Google Spanner、CockroachDB |
| 日志增量同步 | 强一致 | 低 | 中 | 中(依赖日志) | PostgreSQL Logical Replication |
| 流式同步 | 最终一致 | 低 | 高 | 低 | Kafka + Flink |
| 混合策略 | 可配置 | 可配置 | 高 | 低 | Amazon Aurora、TiDB |
FAQs
Q1:如何选择分布式数据库的同步方法?
A1:需综合考虑以下因素:
- 一致性要求:金融交易需强一致,日志分析可接受最终一致。
- 延迟容忍度:实时场景选同步/流式,非实时可选异步。
- 部署规模:全球多活需多主或混合策略,单中心可简化为主从。
- 运维能力:复杂策略(如Raft)需专业技术支持。
Q2:网络分区导致数据不一致时如何处理?
A2:需基于CAP定理权衡:
- 优先可用性(AP):允许临时不一致,恢复后自动合并(如DynamoDB)。
- 优先一致性(CP):拒绝部分写操作,保证已确认节点一致(如Raft协议)。
- 混合策略:通过Quorum多数派决策降低冲突概率(如Ca