上一篇
分布式数据仓库是什么意思
分布式数据仓库是通过将数据分散存储于多节点集群,结合 %ignore_a_3%计算框架实现海量数据高效存储与并行分析的系统,具备弹性
分布式数据仓库详解
定义与核心概念
分布式数据仓库是一种基于分布式架构设计的数据存储与管理系统,通过将数据分散存储在多个物理节点上,并利用分布式计算技术实现数据的高效处理与分析,其核心目标是解决传统集中式数据仓库在数据量、性能、扩展性等方面的瓶颈,同时保证数据的高可用性和一致性。
核心特点解析
| 特性 | 传统数据仓库 | 分布式数据仓库 |
|---|---|---|
| 数据存储 | 单一节点集中存储 | 多节点分片存储 |
| 扩展性 | 纵向扩展(硬件升级) | 横向扩展(增加节点) |
| 性能瓶颈 | 依赖单点硬件性能 | 通过并行计算分散负载 |
| 故障恢复 | 单点故障可能导致服务中断 | 自动容错,节点故障不影响整体服务 |
| 成本效率 | 初期投入高,资源利用率低 | 按需扩展,长期成本更低 |
技术架构与关键组件
数据分层架构
- 数据源层:整合多源异构数据(如日志、数据库、流数据)。
- ETL层:通过分布式ETL工具(如Apache NiFi、Airflow)清洗、转换数据。
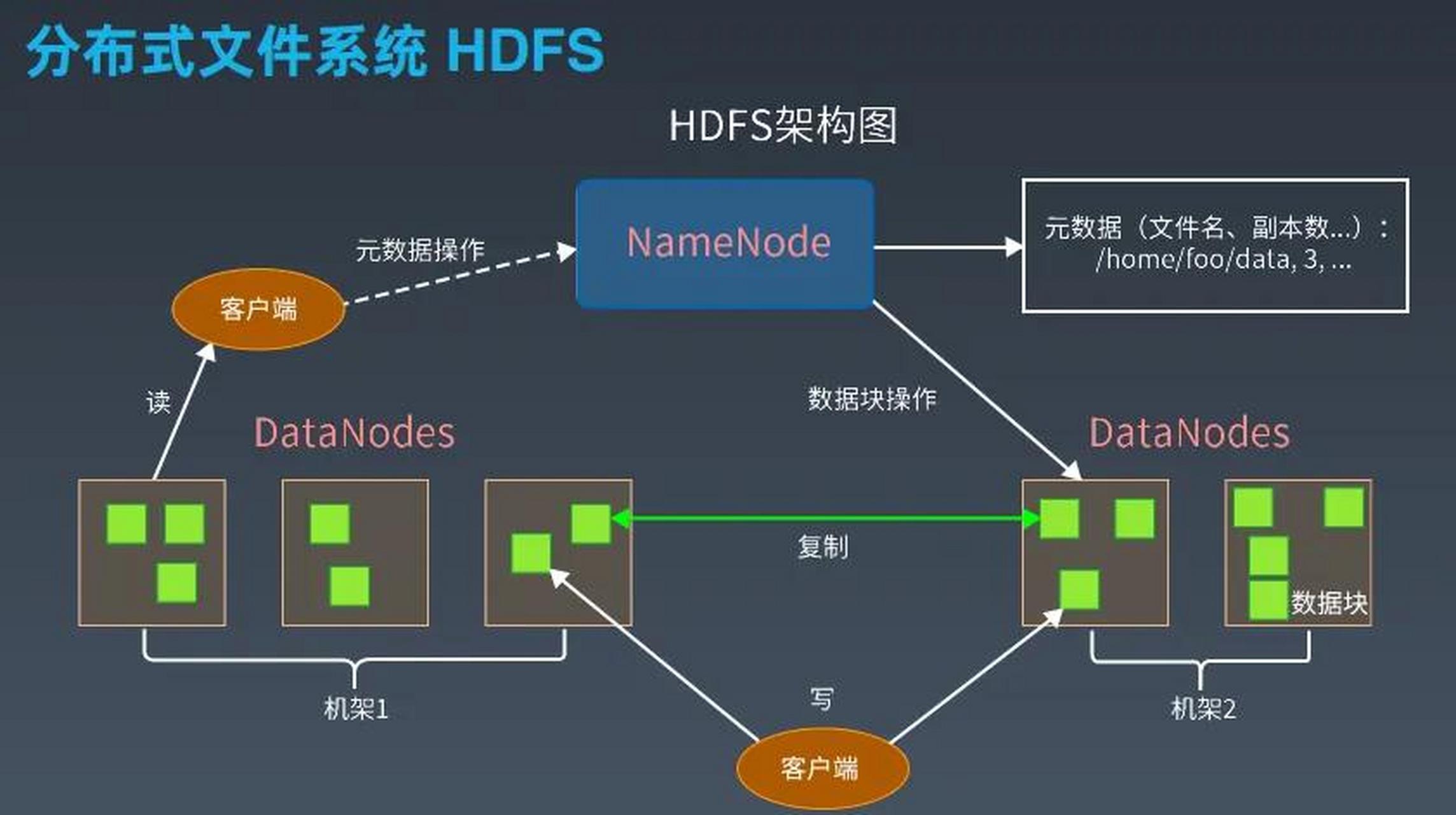
- 存储层:采用分布式文件系统(如HDFS)或数据库(如HBase、Cassandra)分片存储。
- 计算层:基于MPP(Massively Parallel Processing)引擎(如Greenplum、Impala)或流计算框架(如Flink)处理查询。
- 服务层:通过BI工具(如Tableau)或API提供数据服务。
核心技术对比
| 技术方向 | 典型工具/框架 | 功能特点 |
|——————–|——————————————-|———————————————|
| 分布式存储 | HDFS、Ceph、MinIO | 数据分块、副本机制、高吞吐量 |
| 分布式计算 | Spark、Flink、Presto | 支持SQL查询、实时/离线计算、资源调度 |
| 数据一致性 | CAP定理权衡(如CP模式的HBase、AP模式的Cassandra) | 强一致性 vs 最终一致性 |
| 任务调度 | YARN、Kubernetes | 资源分配、任务隔离、动态扩缩容 |
应用场景与优势
典型场景
- 海量数据处理:如电商用户行为分析(每日亿级日志)。
- 实时决策支持:金融风控系统需秒级响应。
- 跨地域数据整合:全球化企业多数据中心数据聚合。
- 历史数据归档:长期存储PB级冷数据。
核心优势
- 弹性扩展:节点数量可随数据量线性增加,无需停机。
- 高可用性:数据多副本存储(如HDFS默认3副本),节点故障自动切换。
- 成本优化:使用廉价PC服务器集群替代高端小型机。
- 性能提升:复杂查询通过并行计算分解到多个节点执行。
挑战与解决方案
| 挑战 | 应对策略 |
|---|---|
| 数据一致性 | 采用分布式事务协议(如两阶段提交)或接受最终一致性模型 |
| 运维复杂度 | 通过容器化(Docker/K8s)和自动化运维工具(如Ansible)降低管理成本 |
| 查询延迟 | 引入内存计算引擎(如ClickHouse)或数据预分区优化 |
| 网络带宽瓶颈 | 数据本地化处理(如Spark的RDD就近计算)减少跨节点传输 |
与传统数据仓库的本质区别
架构设计
- 传统仓库:依赖单体服务器,扩展需停机升级硬件。
- 分布式仓库:无单点瓶颈,通过增加节点实现水平扩展。
适用场景
- 传统仓库:适合小规模、结构化数据,对实时性要求低的场景。
- 分布式仓库:面向大规模、混合数据类型,需高并发查询的场景。
技术选型
- 传统仓库:Oracle、SQL Server等商业数据库。
- 分布式仓库:开源组合(如Hadoop+Spark+Kafka)或云服务(AWS Redshift)。
未来发展趋势
- 云原生化:与Kubernetes深度集成,支持Serverless分析。
- AI融合:内置机器学习模型训练与推理能力(如Amazon Redshift ML)。
- 存算分离:计算与存储资源独立扩展(如阿里云AnalyticDB)。
- 混合云部署:跨私有云与公有云的无缝数据流动。
FAQs(常见问题解答)
Q1:分布式数据仓库和传统数据仓库的最大区别是什么?
A1:核心差异在于扩展性和架构设计,分布式数据仓库通过多节点并行处理数据,支持EB级存储和高并发查询,而传统仓库受限于单机性能,扩展成本高且存在单点故障风险,处理10TB数据时,分布式系统可通过增加10个节点线性提升能力,而传统仓库可能需要更换更高配置的服务器。
Q2:哪些行业最需要分布式数据仓库?
A2:以下场景需求显著:
- 互联网企业:用户行为分析(如抖音每日处理PB级日志)。
- 金融机构:实时反欺诈检测(毫秒级交易数据分析)。
- 物联网领域:设备传感器数据聚合(如智慧城市中的百万级设备监控)。
- 电商行业:双十一大促期间的实时库存与销量分析。
这些场景的共同特点是数据量大、实时性要求高、需要支持