上一篇
分布式数据仓库hive教材
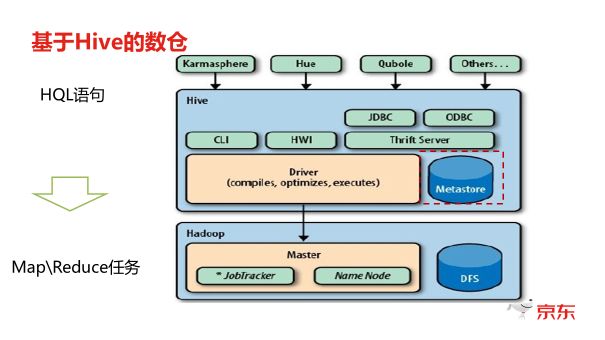
Hive是基于Hadoop的分布式数据仓库,支持SQL查询
分布式数据仓库Hive核心知识体系解析
Hive基础架构与核心组件
Hive是基于Hadoop的分布式数据仓库工具,其架构包含多个关键组件,具体如下:
| 组件名称 | 功能描述 | 运行位置 |
|---|---|---|
| MetaStore | 元数据管理(表结构/分区信息/权限) | 独立服务(RDBMS) |
| Driver | 客户端接口(SQL解析入口) | 客户端节点 |
| Compiler | 查询计划编译(语法解析→抽象语法树→执行计划) | Driver所在节点 |
| Execution Engine | 任务执行引擎(生成MapReduce/Tez任务) | Hadoop集群 |
| Metadata Cache | 元数据本地缓存 | 执行节点 |
典型部署模式对比:
- 内嵌模式:MetaStore与Hive服务部署在同一节点,适合测试环境
- 远程模式:MetaStore独立部署,通过JDBC连接,适合生产环境
HiveQL语言特性与操作规范
HiveQL在保留标准SQL特性的基础上进行了扩展,主要差异点如下:
| 类别 | HiveQL特性 | 标准SQL对比 |
|---|---|---|
| 数据定义 | 支持ALTER TABLE修改表属性 | 部分DDL操作受限 |
| 数据加载 | LOAD/IMPORT导入数据(支持HDFS/本地文件) | 标准SQL无对应 |
| 文件格式 | 支持TEXT/SEQUENCEFILE/ORC/PARQUET | 标准SQL仅支持表结构 |
| 分区管理 | 静态/动态分区创建(PARTITIONED BY) | 需手动管理 |
| 存储策略 | 表存储格式指定(STORED AS) | 由DBMS自动管理 |
典型DDL操作示例:
-创建分区表(按日期分区) CREATE TABLE user_logs ( uid STRING, action STRING, timestamp BIGINT ) PARTITIONED BY (dt STRING) STORED AS ORC; -动态分区插入 INSERT OVERWRITE TABLE user_logs PARTITION(dt) SELECT uid, action, timestamp, FROM_UNIXTIME(timestamp, 'yyyy-MM-dd') as dt FROM staging_table;
数据存储与组织形式
Hive通过多种机制优化数据存储,关键特性对比:
| 特性 | 说明 | 适用场景 |
|---|---|---|
| 分区(Partition) | 按指定字段划分目录结构 | 时间周期数据/地域分布数据 |
| 桶(Bucket) | 哈希取模划分文件 | 均匀分布查询场景 |
| 文件格式 | ORC/Parquet列式存储 | 复杂查询/压缩需求 |
| 索引 | Bitmap/Compacted索引 | 高频率查询字段 |
存储优化策略:

- 按业务维度建立组合分区(如:year=2023/month=06/day=15)
- 对高频查询字段创建COMPACTED索引
- 采用ORC格式开启Zlib压缩(配置
orc.compress=ZLIB) - 设置合理桶数量(通常取值10-30倍于reduce数)
查询执行与优化机制
Hive查询执行流程包含多个优化环节:
graph TD
A[Client提交查询] --> B{Compiler编译}
B --> C[语法解析]
C --> D[语义分析]
D --> E[逻辑计划生成]
E --> F[优化器]
F --> G[谓词下推]
F --> H[列式存储优化]
F --> I[连接优化]
G/H/I --> J[物理计划生成]
J --> K[任务提交]
K --> L[YARN资源调度]
L --> M[MapReduce执行]关键优化参数:
mapreduce.job.reduces:设置Reducer数量(默认1)hive.exec.parallel:启用并行执行(建议开启)hive.exec.dynamic.partition:允许动态分区(需设nonstrict模式)hive.vectorized.execution:向量化执行(提升CPU利用率)
典型优化案例:
-原始查询(全表扫描) SELECT department, COUNT() FROM employee_records GROUP BY department; -优化方案(添加分区字段) ALTER TABLE employee_records ADD IF NOT EXISTS PARTITION(entry_date STRING); -重建分区表后执行相同查询,减少扫描量80%
企业级应用实践
Hive在企业数据平台中的定位与最佳实践:
| 应用场景 | 实施要点 | 注意事项 |
|---|---|---|
| 离线数据分析 | 每日定时ETL任务调度 | 避免小文件过多 |
| 数据湖集成 | 与Iceberg/Hudi结合实现流批一体 | 版本兼容性测试 |
| BI报表支撑 | 预聚合中间表设计 | 平衡查询性能与存储空间 |
| 历史数据归档 | 按时间分区存储+冷存储策略 | 设置合理的生命周期策略 |
典型企业架构:
数据源 → Kafka → Spark Streaming → HDFS原始层 → Hive清洗层 → Hive数据集市 → BI工具常见问题与解决方案
FAQs:
Q1:Hive与关系型数据库的核心区别是什么?
A:主要差异体现在:
- 存储层:Hive基于HDFS分布式存储,传统RDBMS使用集中式存储
- 事务支持:Hive默认不支持ACID事务(3.0+版本支持),RDBMS具备完整事务机制
- 延迟性:Hive适合分钟级延迟的批量处理,RDBMS适用于秒级实时查询
- 扩展性:Hive横向扩展能力更强,可处理PB级数据
Q2:如何诊断和解决Hive查询性能问题?
排查步骤:
- 检查执行计划:
EXPLAIN EXTENDED查看是否全表扫描 - 分析任务监控:通过YARN ResourceManager查看Map/Reduce阶段耗时
- 数据倾斜检测:观察Reducer任务执行时间差异(超过3倍需优化)
- IO瓶颈确认:HDFS吞吐量监控(NameNode/DataNode指标)
- 资源配置验证:调整
mapreduce.map.memory等YARN参数
解决方案:
- 添加合理分区字段过滤数据
- 启用Tez/Spark执行引擎替代MapReduce
- 对倾斜key进行特殊处理(如
skewed参数配置) - 增加CombineFileInputFormat减少Map任务数
技术演进与生态整合
当前Hive技术栈的重要发展趋势:
- 计算引擎升级:从MapReduce转向Tez/Spark,提升查询性能10-50倍
- ACID支持:Hive 3.0+实现事务支持,支持INSERT OVERWRITE等操作
- 流批一体:与Iceberg/Hudi集成实现近实时数据处理
- 云原生适配:支持AWS Glue、Azure Synapse等托管服务
- SQL标准化:逐步兼容ANSI SQL:2011标准
主流生态工具对比:
| 工具 | 定位 | 优势 | 适用场景 |
|—————–|——————————-|——————————-|————————-|
| Hive | 分布式数据仓库 | 成熟稳定/生态丰富 | 批量数据处理/历史分析 |
| Impala | Mpp实时查询引擎 | 亚秒级响应 | 交互式分析 |
| Spark SQL | 内存计算引擎 | 多源数据处理能力 | 混合负载场景 |
| Presto | 分布式SQL查询引擎 | 极速启动/多数据源支持 | 即时查询 |
| Trino | 高性能查询引擎 | 水平扩展性 | 大并发查询场景