上一篇
分布式数据仓库HIVE技术
HIVE是基于 Hadoop的分布式数据仓库,支持SQL查询,适用于大数据分析,具备高扩展性与存储能力
分布式数据仓库HIVE技术详解
Hive技术
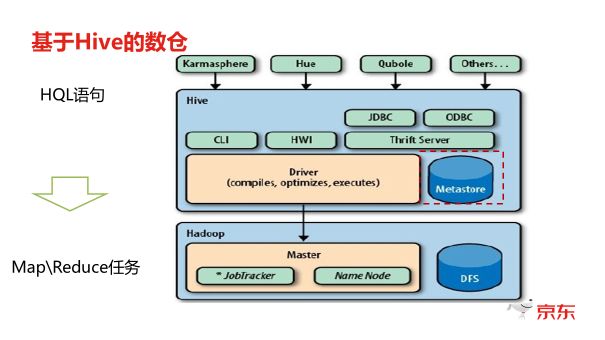
Hive是基于Hadoop生态系统构建的分布式数据仓库工具,专为处理大规模结构化和半结构化数据设计,它通过类SQL的查询语言(HiveQL)实现数据提取、转换和加载(ETL),底层依赖HDFS存储数据,并通过MapReduce或Tez等计算框架执行任务,Hive的核心优势在于将传统数据仓库的灵活性与Hadoop的分布式存储和计算能力结合,适用于离线数据分析场景。
Hive架构与核心组件
Hive采用分层架构设计,主要组件及功能如下表所示:
| 组件 | 功能描述 |
|---|---|
| Metastore | 元数据管理服务,存储表结构、分区信息、权限等,默认使用内嵌Derby数据库,生产环境多用MySQL。 |
| Driver | 客户端入口,负责解析HiveQL语句,生成执行计划并提交到执行引擎。 |
| Compiler | 编译HiveQL为抽象语法树(AST),优化查询计划(如谓词下推、列式裁剪),生成物理执行计划。 |
| Execution Engine | 执行引擎(如MapReduce、Tez、Spark),将任务拆分为Stage并分配到集群节点执行。 |
| HDFS | 底层存储系统,以文件形式存储表数据,支持按分区组织数据,提升查询效率。 |
数据存储格式
Hive支持多种存储格式,常见格式对比如下:

| 格式 | 特点 |
|---|---|
| Text | 行式存储,简单易用但无压缩,适合小规模数据。 |
| SequenceFile | 二进制行式存储,支持压缩,适合中等规模数据。 |
| ORC | 列式存储,高效压缩和投影,适合大数据分析(需结合索引)。 |
| Parquet | 列式存储,支持复杂嵌套结构,与ORC类似但跨平台兼容性更好。 |
HiveQL与SQL的关键差异
HiveQL兼容标准SQL语法,但针对分布式环境进行了扩展和优化,主要差异包括:
- 文件格式与存储
- 支持
STORED AS指定存储格式(如ORC、Parquet)。 - 通过
PARTITIONED BY定义分区字段,提升查询效率。
- 支持
- 动态分区插入
INSERT OVERWRITE DIRECTORY ... SELECT ... FROM ... WHERE ...;
- 内置函数扩展
提供JSON解析(get_json_object)、正则表达式(regexp_extract)等大数据专用函数。
示例:创建分区表并加载数据
CREATE TABLE user_logs ( uid STRING, action STRING, timestamp BIGINT ) PARTITIONED BY (date STRING) STORED AS ORC; LOAD DATA INPATH '/raw_logs/' INTO TABLE user_logs PARTITION (date='2023-10-01');
Hive的适用场景与局限性
典型应用场景
- 日志分析:处理TB/PB级服务器日志,统计访问量、用户行为路径。
- 数据仓库:构建企业级历史数据仓库,支持复杂OLAP查询。
- ETL处理:通过HiveQL清洗、转换原始数据并加载到目标表。
局限性
| 缺点 | 原因及影响 |
|————————|——————————————————————————|
| 实时性差 | 依赖MapReduce导致查询延迟高(分钟级),不适用于实时分析。 |
| 更新删除效率低 | HDFS文件不可变特性,UPDATE/DELETE操作需重写全表数据。 |
| 依赖Hadoop生态 | 需部署HDFS、YARN等组件,学习成本较高。 |
Hive性能优化策略
- 分区与桶(Bucket)设计
- 按业务维度(如日期、地区)分区,减少全表扫描。
- 对高频查询字段(如用户ID)分桶,提升JOIN效率。
- 列式存储与压缩
使用ORC/Parquet格式并开启Snappy/Zlib压缩,减少IO开销。 - 倾斜优化
- 通过
MAPJOIN或SKEWED JOIN处理数据倾斜。 - 设置
hive.groupby.skewindata=true自动负载均衡。
- 通过
- 内存与并行度调优
- 调整
mapreduce.reduce.memory.mb和yarn.nodemanager.resource.memory-mb。 - 启用Tez引擎替代MapReduce,提升执行速度。
- 调整
Hive与其他技术的对比
| 技术 | Hive | Impala | Spark SQL |
|---|---|---|---|
| 计算模型 | 批处理(MapReduce/Tez) | 实时MPP(Memory+CPU) | 批流一体(DAG调度) |
| 延迟 | 高(分钟级) | 低(秒级) | 中等(10秒~分钟级) |
| 适用场景 | 离线分析、ETL | 实时交互式查询 | 混合负载(批处理+流处理) |
| 生态依赖 | Hadoop/HDFS | Hadoop/HDFS | 独立部署或对接HDFS/S3 |
常见问题与解答(FAQs)
Q1:Hive是否支持实时数据处理?
A1:Hive本身设计为批处理工具,依赖MapReduce导致延迟较高,若需实时处理,可结合以下方案:
- 使用Impala或Spark SQL进行实时查询。
- 通过Kafka+Flink实现流式数据处理,结果写入Hive供后续分析。
Q2:如何优化Hive小文件过多问题?
A2:小文件会导致Map任务数量激增,可通过以下方法优化:
- 合并小文件:使用
Hive CONCAT命令合并分区数据,或定期执行ALTER TABLE ... CONCATENATE。 - 调整分区粒度:避免过度分区(如按小时分区),改为按天或更大范围分区。
- 开启ORC文件格式:利用ORC的轻量级索引和文件合并特性减少碎片