上一篇
分布式数据库用户
分布式数据库用户需跨节点访问,处理分片 数据,保障高可用,实施细粒度权限管控
分布式数据库用户详解
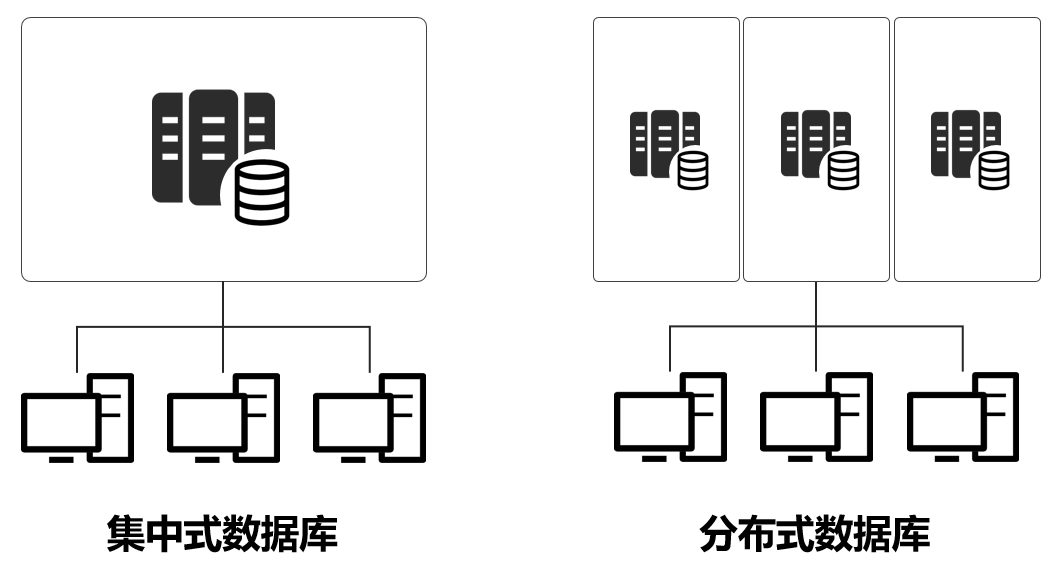
分布式数据库
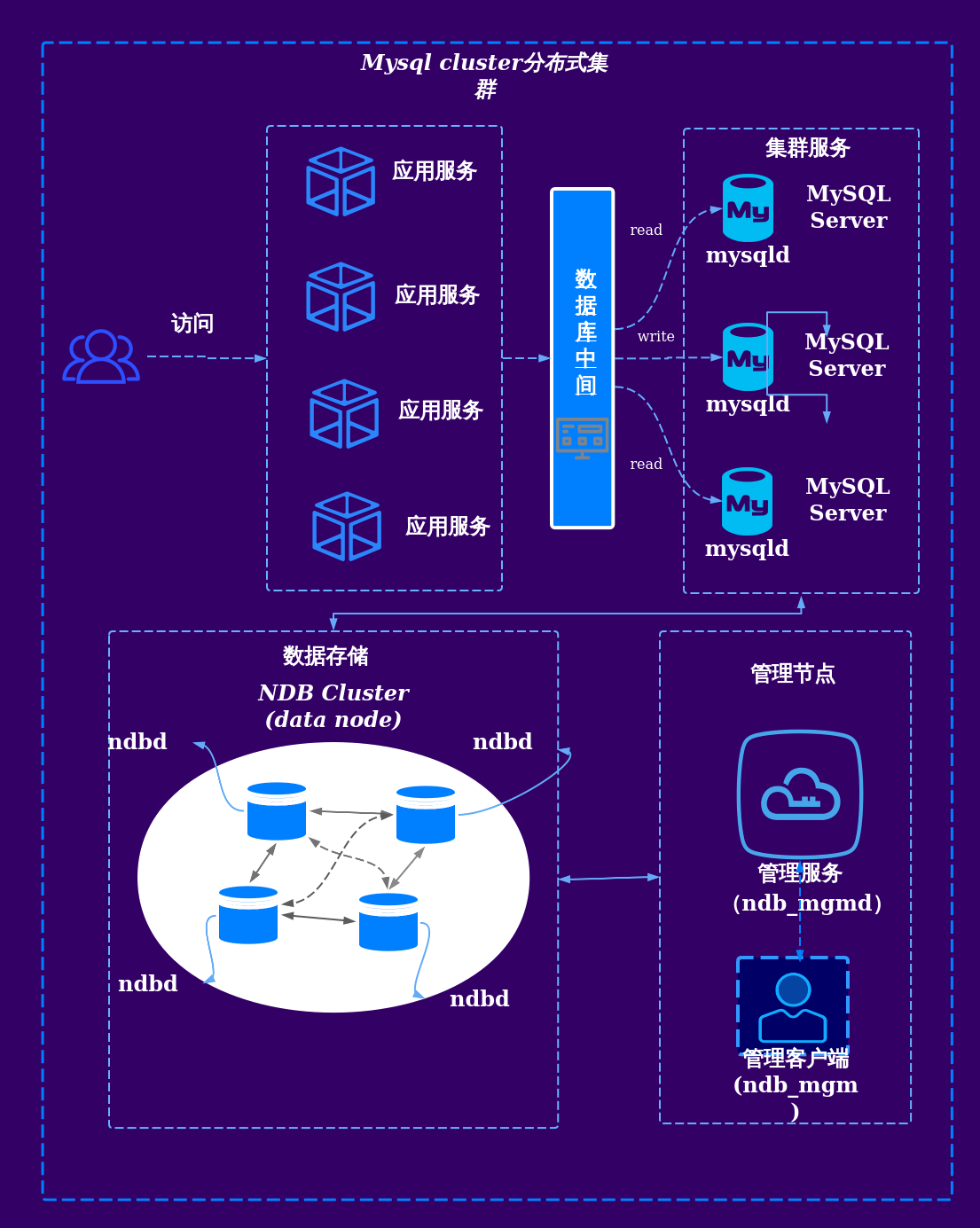
分布式数据库是一种通过网络将数据存储在多个物理节点上的数据库系统,旨在解决传统集中式数据库在扩展性、可靠性和性能方面的瓶颈,其核心目标是实现数据的横向扩展(Scale-Out)、高可用性和地理分布性,同时保持数据一致性和透明性,用户作为系统的直接使用者,需要理解分布式数据库的特性、操作模式及适用场景。
分布式数据库的核心特点与用户关系
| 特性 | 描述 | 对用户的影响 |
|---|---|---|
| 弹性扩展 | 通过增加节点实现水平扩展,无需停机。 | 用户可灵活应对业务增长,但需关注数据分片策略。 |
| 高可用性 | 数据多副本存储,节点故障时自动切换。 | 用户获得更高的容灾能力,但需配置合理的冗余机制。 |
| 透明性 | 对用户隐藏分布式细节,提供单一逻辑视图。 | 用户无需关注底层复杂性,但需理解分布式事务限制。 |
| 数据一致性 | 通过协议(如Paxos、Raft)保证多节点数据一致。 | 用户需权衡一致性与性能(CAP定理)。 |
| 地理分布性 | 支持跨区域部署,降低延迟。 | 用户可优化全球访问,但需处理网络分区风险。 |
分布式数据库用户的核心角色与需求
开发者
- 需求:
- 支持SQL或NoSQL接口,降低学习成本。
- 提供分布式事务(如两阶段提交、TCC)或最终一致性选项。
- 工具链集成(如ORM框架、监控面板)。
- 挑战:
- 处理分片键设计、跨节点查询优化。
- 避免分布式死锁和超时问题。
- 需求:
运维工程师
- 需求:
- 自动化节点扩缩容、故障转移。
- 实时监控数据分布、负载均衡状态。
- 日志聚合与审计功能。
- 挑战:
- 多节点网络延迟、硬件故障排查。
- 平衡数据副本与存储成本。
- 需求:
数据分析师
- 需求:
- 支持复杂查询(如OLAP分析)、亚秒级响应。
- 数据联邦能力(跨分片联合查询)。
- 挑战:
- 处理数据倾斜导致的查询性能下降。
- 优化全局统计与局部计算的冲突。
- 需求:
企业管理者

- 需求:
- 低成本规模化存储(如冷热数据分层)。
- 符合合规要求的数据隔离(如GDPR、CNPD)。
- 挑战:
- 评估分布式数据库的长期运维成本。
- 制定多云/混合云部署策略。
- 需求:
用户需关注的关键技术点
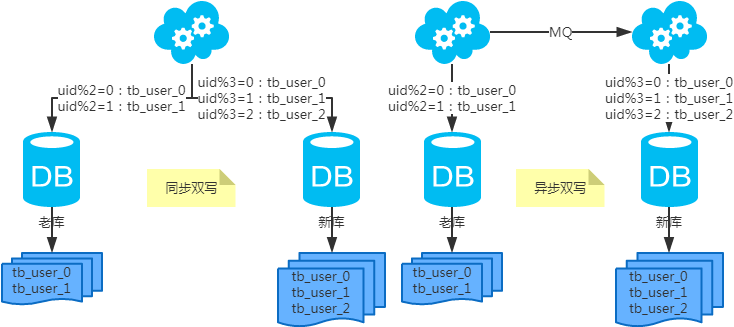
数据分片(Sharding)
- 用户决策:选择哈希分片(均匀分布)或范围分片(按时间/ID区间),需结合业务访问模式。
- 示例:电商订单按用户ID分片,社交Feed按时间范围分片。
副本机制
- 强一致性 vs 最终一致性:
- 金融交易需强同步副本(如Raft协议)。
- 日志类应用可接受最终一致性(如DNS记录)。
- 用户配置:副本数、同步/异步复制策略。
- 强一致性 vs 最终一致性:
事务管理
- 分布式事务:需牺牲部分性能(如2PC协议),适用于关键业务。
- 本地事务:单节点内快速执行,但跨分片操作受限。
- 用户选择:根据业务容忍度决定一致性级别。
CAP定理权衡
- 用户场景匹配:
- CP优先:金融、电信等强一致性场景。
- AP优先:社交媒体、物联网等高可用场景。
- 典型误区:盲目追求“完美一致”导致性能瓶颈。
- 用户场景匹配:
用户常见挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 复杂度高 | 使用托管服务(如AWS Aurora、Azure Cosmos DB)或简化中间件。 |
| 成本控制 | 采用存算分离架构,冷数据归档至廉价存储(如对象存储)。 |
| 数据一致性问题 | 结合业务场景选择一致性模型,或使用分布式事务框架(如Seata)。 |
| 网络延迟与分区 | 部署就近节点,配置多活数据中心,使用异步复制缓解分区影响。 |
| 安全与合规 | 启用加密传输(TLS)、字段级权限控制,定期审计访问日志。 |
用户选型建议
业务匹配度:
- 高频写入(如日志):选择无共享架构(如Cassandra)。
- 复杂查询(如BI):选择列式存储(如Greenplum)。
- 混合负载(如电商):选择支持HTAP的数据库(如TiDB)。
生态成熟度:
- MySQL/PostgreSQL生态:选择兼容的分布式版本(如Vitess、CockroachDB)。
- NoSQL场景:根据数据模型选择MongoDB(文档)、Redis(键值)、HBase(宽表)。
成本评估:
- 开源方案(如TiDB、ClickHouse)适合资源充足的团队。
- 云服务(如Amazon DynamoDB、Google Spanner)降低运维门槛。
FAQs
Q1:分布式数据库适合哪些业务场景?
A1:适用于需要横向扩展、高可用性或全球化的业务,
- 海量数据存储(如社交网络、物联网设备数据)。
- 高并发读写(如电商大促、游戏服务器)。
- 跨地域低延迟访问(如CDN缓存、金融风控)。
需避免在低并发、小规模数据场景中使用,以免增加复杂度。
Q2:如何评估分布式数据库的性能瓶颈?
A2:从以下维度排查:
- 分片策略:检查是否存在数据热点或分片不均。
- 网络延迟:监控节点间RTT(往返时间)及带宽占用。
- 磁盘IO:分析慢查询是否由磁盘瓶颈导致。
- 事务冲突:检查锁等待或分布式死锁日志。
可通过压测工具(如YCSB、JMeter)模拟真实负载,定位瓶颈