上一篇
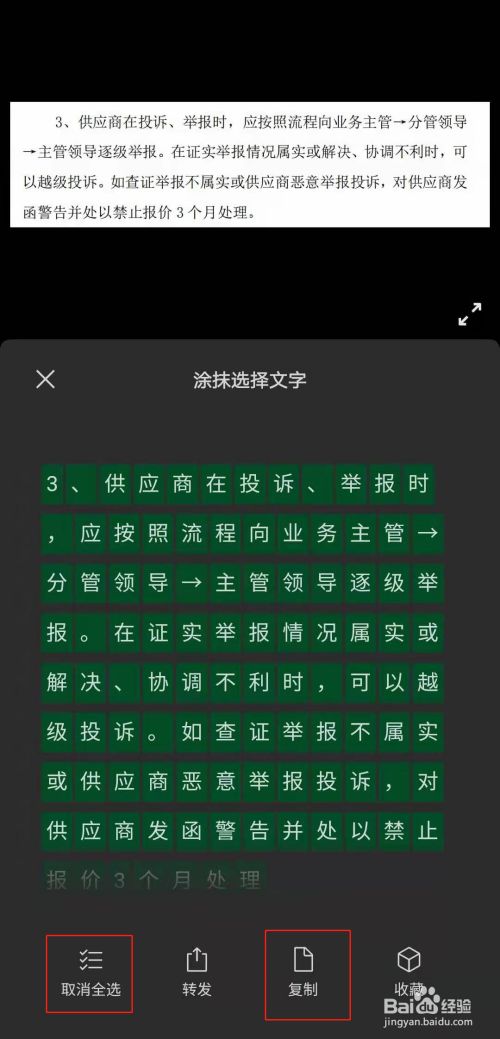
按键网页识别文字
按键网页识别文字指通过OCR技术解析网页截图或扫描件中的 文字信息,支持多语言实时转换与编辑,常用于文档数字化、信息快速提取及跨语言
工具与技术
按键模拟工具

- PyAutoGUI:跨平台自动化库,可模拟键盘、鼠标操作。
- Selenium:浏览器自动化工具,支持网页交互(如点击按钮、输入文本)。
- Robot Framework:关键字驱动自动化框架,适合复杂流程。
文字识别技术
- OCR(光学字符识别):如 Tesseract、百度OCR、Google Cloud Vision。
- 截图工具:Pillow(Python)、Selenium 自带的截图功能。
操作流程(以 Selenium + Tesseract 为例)
环境准备
| 步骤 | 操作 |
|---|---|
| 安装依赖 | pip install selenium pytesseract pillow |
| 下载驱动 | 根据浏览器类型(Chrome/Firefox)下载对应 WebDriver(如 chromedriver)。 |
| 配置 Tesseract | 安装 Tesseract OCR,并配置环境变量(Windows需添加 tesseract.exe路径)。 |
模拟按键与文字识别
from selenium import webdriver
from PIL import Image
import pytesseract
import time
# 初始化浏览器驱动
driver = webdriver.Chrome(executable_path='path/to/chromedriver')
driver.get('https://example.com') # 目标网页
# 模拟按键操作(如按下 Tab 键聚焦到目标区域)
driver.find_element_by_id('target-button').click() # 点击按钮展开内容
time.sleep(2) # 等待内容加载
# 截取网页区域图片
element = driver.find_element_by_id('text-container')
location = element.location
size = element.size
driver.save_screenshot('full_page.png') # 截取整个页面
# 裁剪目标区域并OCR识别
image = Image.open('full_page.png')
left = location['x']
top = location['y']
right = left + size['width']
bottom = top + size['height']
cropped_image = image.crop((left, top, right, bottom))
text = pytesseract.image_to_string(cropped_image, lang='chi_sim') # 中文识别
print(text)
driver.quit()常见问题与解决方案
| 问题 | 解决方案 |
|---|---|
| 动态加载内容无法截取 | 使用 Selenium 的 WebDriverWait 等待元素加载完成,或增加固定延时。 |
| OCR 识别准确率低 | 调整图片对比度/清晰度; 使用自定义训练模型(如 Tesseract 训练字库); 尝试百度/Google OCR API。 |
| 按键操作被弹窗阻断 | 检测弹窗元素并关闭,或使用 try-except 捕获异常。 |
工具对比表
| 工具 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| Selenium | 浏览器自动化交互 | 支持复杂操作,兼容性好 | 依赖浏览器驱动,资源占用高 |
| PyAutoGUI | 桌面应用或简单GUI自动化 | 轻量级,跨平台 | 对网页元素定位支持弱 |
| Tesseract | 本地化OCR需求 | 免费开源,支持多语言 | 准确率依赖图片质量,中文需额外配置 |
| 百度/Google OCR | 高精度云端识别 | 无需部署,准确率高 | 需网络,可能有调用次数限制 |
相关问题与解答
问题1:如何识别网页中动态生成的验证码?
解答:
- 绕过验证码:通过分析网页请求,直接发送验证码验证接口(需抓包分析)。
- OCR+手动输入:用 OCR 识别验证码图片,结合 Selenium 自动输入(成功率低,需人工辅助)。
- 第三方打码平台:调用打码API(如 Anti-Captcha、2Captcha),自动付费破解。
问题2:如何提高 Tesseract 对中文的识别准确率?
解答:
- 配置语言包:安装
tesseract-ocr-chi-sim(简体中文)或tesseract-ocr-chi-tra(繁体中文)。 - 图片预处理:转为灰度图、二值化、降噪(如
threshold=180)。 - 自定义训练:使用
tesseract的traindata工具,针对特定字体或场景训练