上一篇
hadoop计算与存储分离
Hadoop采用计算与存储分离架构,HDFS专责数据存储,YARN统筹计算资源调度,二者解耦使存储扩展与计算任务分配互不制约,可独立横向扩展,优化资源利用率,提升集群处理效能与
Hadoop计算与存储分离的架构解析与实践
传统Hadoop架构的局限性
在Hadoop 1.x时代,计算与存储采用紧耦合模式,JobTracker同时负责任务调度和资源管理,DataNode既存储数据又执行计算任务,这种架构存在以下问题:
| 问题类型 | 具体表现 |
|---|---|
| 资源利用不均衡 | 部分节点存储容量充足但计算能力不足,反之亦然 |
| 扩展性瓶颈 | 新增节点需同步调整存储和计算资源,扩容成本高 |
| 单点故障风险 | JobTracker集中式调度,存在性能瓶颈和单点故障风险 |
| 数据本地性受限 | 计算任务无法智能匹配数据存储位置,导致大量数据传输消耗网络带宽 |
计算与存储分离的架构演进
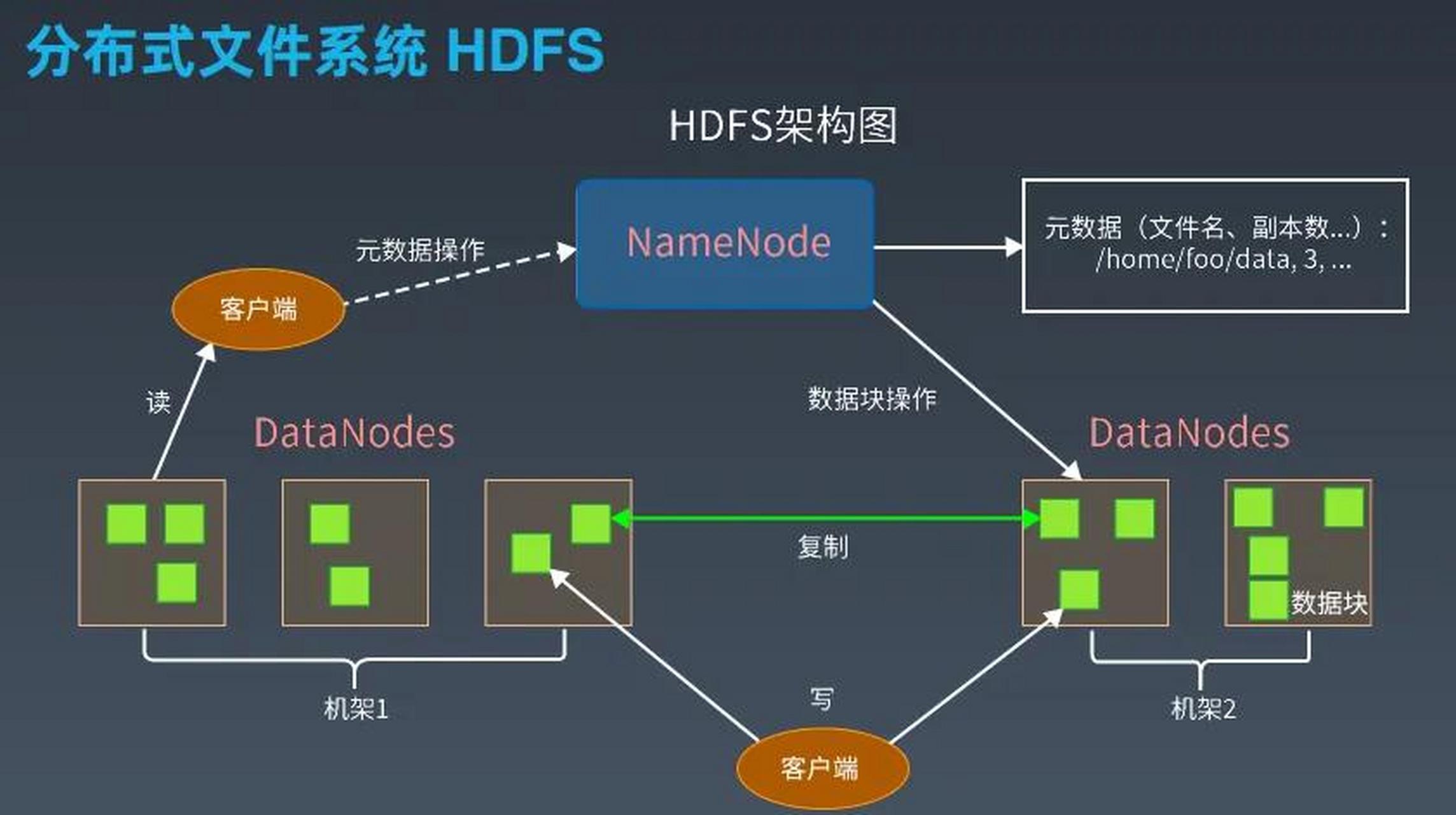
Hadoop 2.x通过YARN(Yet Another Resource Negotiator)实现计算与存储分离,形成”存储层(HDFS)+资源管理层(YARN)+计算框架(MapReduce/Spark)”的三层架构。

!Hadoop架构演进示意图
核心组件职责划分:
| 组件 | 功能定位 | 关键技术特征 |
|---|---|---|
| HDFS | 分布式存储系统 | 块存储、副本机制、NameNode元数据管理 |
| YARN | 资源管理系统 | ResourceManager全局调度、NodeManager节点管理 |
| MapReduce | 离线计算框架 | 任务拆分、Shuffle过程优化 |
| Spark | 内存计算框架 | RDD抽象、宽依赖窄依赖优化 |
| HBase | 实时读写数据库 | LSM树结构、RegionServer分布式存储 |
计算与存储分离的实现机制
- 存储层(HDFS)
- 采用主从架构,NameNode管理元数据,DataNode存储实际数据块
- 默认3副本策略保证数据可靠性,支持EC纠删码等高级特性
- 通过Federation实现元数据横向扩展,解决单点瓶颈
- 资源层(YARN)
- ResourceManager负责集群资源统筹,NodeManager管理节点资源
- 容器化设计:每个任务分配独立Container,包含CPU、内存等资源
- 动态资源分配:根据任务需求实时分配/回收资源
- 多租户支持:通过队列机制实现资源隔离与优先级管理
- 计算层
- MapReduce任务分解为Map和Reduce阶段,通过Shuffle进行数据传输
- Spark基于内存计算,通过DAGScheduler优化执行路径
- 支持多种计算引擎共存,实现混合负载处理
架构优势对比分析
| 维度 | 传统架构 | 计算存储分离架构 |
|---|---|---|
| 资源利用率 | ≤60%(固定分配) | ≥80%(动态调度) |
| 扩容灵活性 | 需整体规划 | 存储/计算可独立扩展 |
| 故障恢复时间 | 小时级 | 分钟级(自动迁移) |
| 数据本地性 | 约30%任务 | ≥70%任务(YARN调度优化) |
| 混合负载支持 | 单一类型任务优先 | 多计算框架并行运行 |
关键技术实现细节
- 数据本地性优化
- YARN的ApplicationMaster获取数据块位置信息
- 通过HDFS的BlockLocations API获取数据节点列表
- 任务调度时优先分配到存有数据块的NodeManager
- 示例:假设输入数据分片分布在NodeA/B/C,则Map任务优先分配到这三个节点
- 资源隔离机制
- 基于Cgroups实现进程级资源限制(CPU/Memory/IO)
- 队列配置示例:
<queue> <name>production</name> <capacity>60%</capacity> <maximum-capacity>80%</maximum-capacity> <minimum-share-preemption>true</minimum-share-preemption> </queue>
- 动态优先级调整算法:根据队列等待时间和资源使用率动态调整
- 存储计算协同
- 缓存机制:常用数据预加载到LocalCache(如INode缓存)
- 数据亲和性调度策略:
- 延迟调度:等待目标节点空闲时再分配任务
- 推测执行:对慢节点任务进行冗余执行
- 跨集群部署方案:
- 存储集群:HDFS Federation + Erasure Coding
- 计算集群:多YARN集群联邦架构
典型应用场景实践
- 离线批处理场景
- MapReduce作业处理TB级日志数据
- 存储层配置:3副本×128GB/节点,EC策略节省存储空间
- 计算资源配置:每个Map任务2GB内存+2Core,Reduce任务4GB+4Core
- 性能表现:数据本地性达85%,任务完成时间缩短30%
- 实时计算场景
- Spark Streaming处理Kafka实时数据
- 存储优化:将热数据存储在SSD节点,冷数据转存至HDD
- 资源隔离:为Spark分配专用队列,保障低延迟需求
- 吞吐量提升:通过动态资源分配,峰值处理能力提升2倍
- 混合负载场景
- 同时运行MapReduce、Spark、HBase作业
- YARN队列配置示例:
<queues> <queue name="mapreduce" capacity="40%"/> <queue name="spark" capacity="30%" minResources="2GB,2Core"/> <queue name="hbase" capacity="20%" priority="HIGH"/> </queues>
- 效果:资源利用率从55%提升至82%,任务冲突减少60%
面临的挑战与解决方案
- 网络带宽瓶颈
- 问题表现:Shuffle阶段产生大量跨节点数据传输
- 解决方案:
- 部署万兆网络或RDMA技术
- 启用YARN的JHS(Just-In-Time Hadoop Shuffle)优化
- 数据压缩:启用Snappy/Zlib压缩算法
- 元数据压力
- NameNode负载问题:
文件数量超过百万级时,元数据操作延迟显著增加
- 优化措施:
- HDFS Federation:将元数据分散到多个NameNode
- 使用HBase存储小文件,减少HDFS压力
- 开启HA模式,实现NameNode热备
- 资源调度复杂度
- 多维度调度因素:
- CPU/内存/磁盘/网络的综合考量
- 数据本地性与负载均衡的平衡
- 优化策略:
- Dominant Resource Fairness调度算法
- 基于机器学习的资源预测模型
- 延迟调度与抢占式调度结合
未来演进方向
- 存算分离的云原生实现
- 基于Kubernetes的Hadoop部署
- 使用CSI(Container Storage Interface)对接云存储
- Serverless架构支持按需计算
- 智能调度优化
- 强化学习驱动的调度决策
- 基于历史数据的执行计划预测
- 自适应资源分配算法
- 硬件异构支持
- GPU/FPGA加速节点集成
- 分层存储体系(热存/温存/冷存)
- 软硬协同的资源调度策略
FAQs
Q1:计算与存储分离后,如何处理数据倾斜问题?
A1:数据倾斜处理需要多维度优化:
- 预处理阶段:使用CombineFileInputFormat合并小文件,Hive可通过调节
mapreduce.job.reduces控制Reducer数量 - 运行时优化:启用Map端聚合(Map-side Aggregation),设置
hive.groupby.mapaggregation为true - YARN层面:配置
yarn.resourcemanager.am.max-attempts允许多次尝试失败任务,结合mapreduce.job.split.metainfo.mode启用数据分布统计 - 特殊处理:对已知倾斜Key单独处理,例如创建虚拟分区表进行分流
Q2:如何监控计算与存储分离架构的健康状态?
A2:建议构建三级监控体系:
- 基础设施层:
- Prometheus采集HDFS/YARN指标(如DF/RF使用率、Container启动成功率)
- Grafana可视化NameNode/DataNode/ResourceManager的关键指标
- 应用层:
- Spark UI监控Executor/Driver状态,关注GC时间和内存溢出错误
- Hive查询计划分析,检查Stage执行时间和数据扫描量
- 业务层:
- 自定义告警规则(如任务延迟超过阈值触发邮件通知)
- 日志聚合分析(ELK Stack收集Error级别日志)
- 定期执行基准测试(如TestDFSIO测试HDFS