上一篇
爱语音合成
爱语音合成以自然流畅、情感丰富的音色著称,广泛应用于智能客服、有声阅读等场景,其依托深度学习技术实现多语言支持,通过韵律建模与情感迁移提升交互真实感,显著
语音合成技术基础
核心技术原理
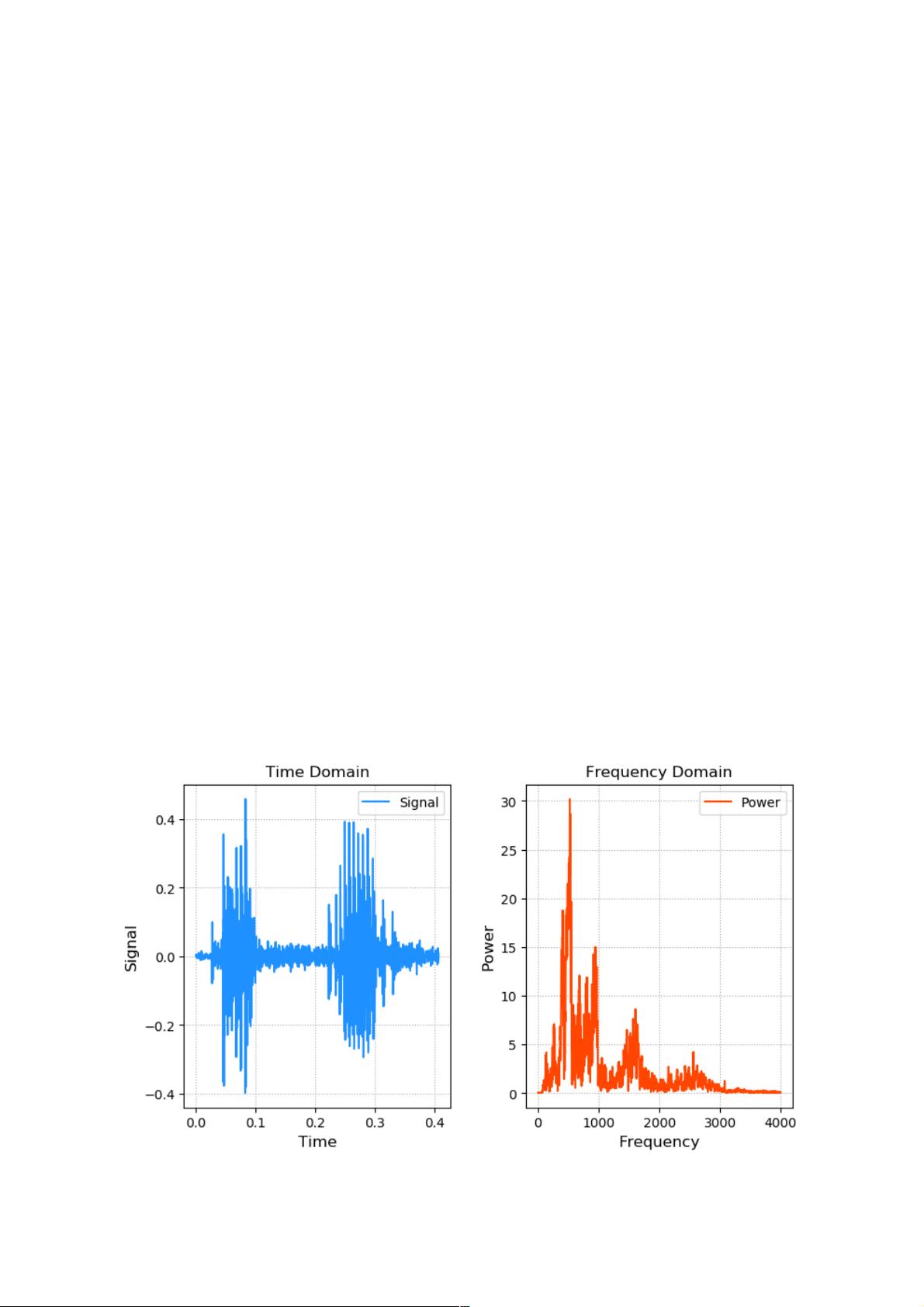
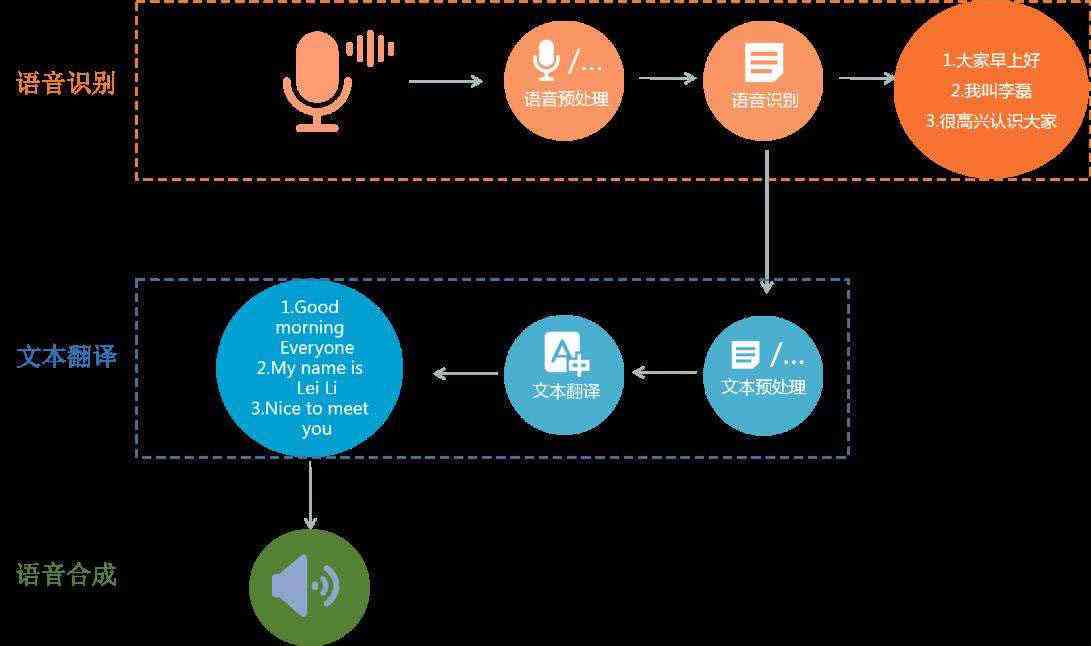
语音合成(Text-to-Speech, TTS)是将文本转化为可听语音的技术,主要包含以下模块:

- 文本分析:对输入文本进行断句、语法解析、情感识别。
- 声学模型:将文字转换为发音参数(如音高、时长、音色)。
- 波形生成:通过拼接语音片段或神经网络生成最终音频。
技术分类
| 技术类型 | 特点 |
|---|---|
| 拼接合成 | 基于录音库拼接,音质自然但灵活性差(如早期导航语音) |
| 参数合成 | 提取语音特征参数生成,音质较机械,资源占用少 |
| 神经网络合成 | 端到端深度学习模型(如WaveNet、Tacotron),支持动态情感和音色调整 |
爱语音合成的核心功能
多维度音色定制
| 参数 | 说明 |
|---|---|
| 年龄 | 青年/中年/老年切换 |
| 性别 | 男声/女声/中性声 |
| 情感 | 中立/高兴/悲伤/愤怒(部分高级模型支持) |
| 方言/口音 | 普通话/英语/日语等,部分平台支持方言(如粤语、四川话) |
实时交互能力
- 低延迟模式:500ms内响应,适用于智能客服、直播字幕朗读
- 长文本处理:支持万字级别文档分段渲染,自动标点停顿控制
典型应用场景
| 场景 | 技术需求 | 案例产品 |
|---|---|---|
| 智能音箱 | 自然对话语气+多轮交互 | 小爱同学、天猫精灵 |
| 有声阅读 | 接近真人的抑扬顿挫+长时间稳定性 | 喜马拉雅AI朗读 |
| 游戏NPC语音 | 个性化音色+情绪匹配 | 《原神》角色语音生成 |
| 无障碍服务 | 高对比度发音+盲文同步 | 屏幕阅读器语音引擎 |
技术优势与挑战
优势
- 成本效益:合成语音边际成本趋近于零
- 灵活定制:通过少量样本即可克隆特定音色
- 多模态扩展:可结合唇形动画、虚拟形象提升沉浸感
挑战
- 情感迁移:复杂情感表达仍依赖大量标注数据
- 实时性瓶颈:高精度模型可能产生>2s延迟(需硬件加速)
- 伦理风险:深度伪造语音可能被用于诈骗或诽谤
主流工具对比
| 平台 | 免费额度 | 音色数量 | 情感支持 | SDK支持平台 |
|---|---|---|---|---|
| 百度语音合成 | 5万字符/月 | 47种 | 基础4类 | Android/iOS/PC |
| 阿里云TTS | 5万字符/月 | 36种 | 进阶6类 | 全平台(含小程序) |
| Amazon Polly | 5分钟/月 | 英语为主 | 基础2类 | AWS全生态 |
相关问题与解答
Q1:语音合成如何实现方言发音?
A:需构建方言专属语料库,通过以下步骤:
- 收集方言母语者的发音数据
- 标注特殊拼音规则(如粤语的九声六调)
- 训练方言专用声学模型
- 部署时优先匹配地域IP调用对应模型
Q2:合成语音能否通过图灵测试?
A:当前最高水平(如Google WaveNet)已实现:
- 自然度:MOS评分4.5/5(接近真人)
- 但仍存在局限性:
• 复杂语境下的语义理解误差
• 极端情感(如极度恐惧)表现不足
• 多人对话场景的声源