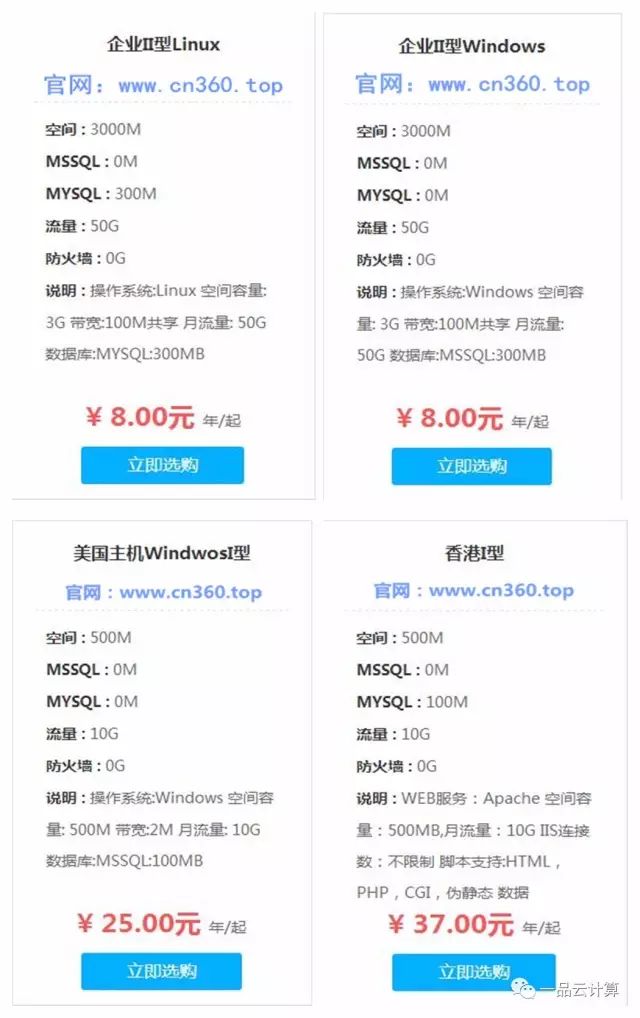
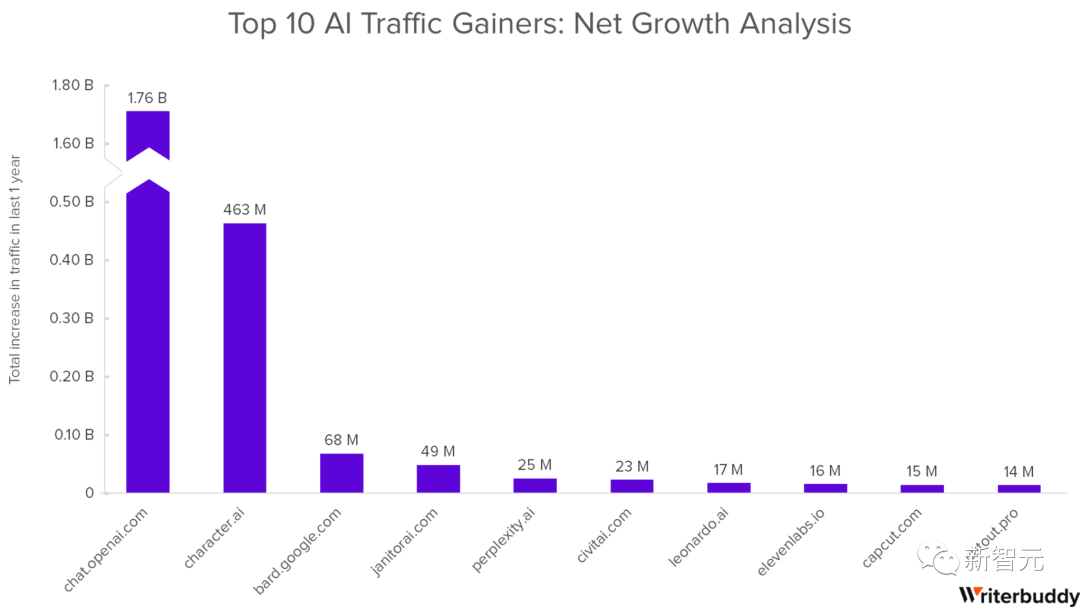
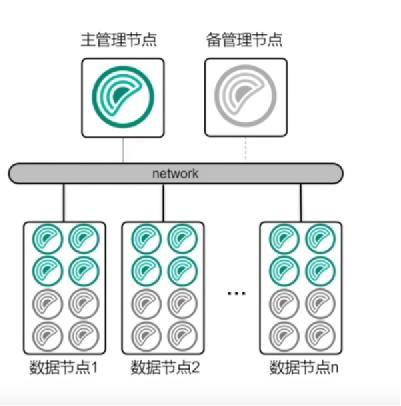
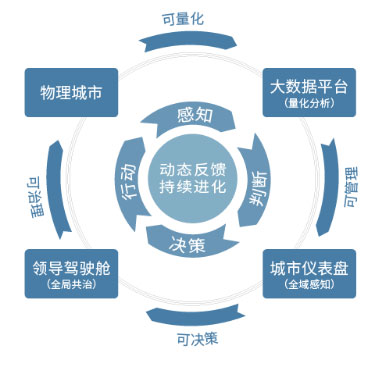
为什么需要语音合成项目?
随着智能客服、有声读物、导航系统等场景的普及,全球语音合成市场规模预计2025年突破50亿美元,企业通过自建语音合成系统可实现:
- ▶ 品牌专属音色定制(如虚拟代言人声线)
- ▶ 敏感内容自主可控(金融/医疗领域合规需求)
- ▶ 多语言实时转换(支持方言与小语种)
某电商平台接入定制TTS后,用户收听商品描述的停留时长提升37%,印证了语音交互的商业价值。
核心技术架构解析
▍传统参数合成
基于HMM/DNN的声学建模
优点:资源占用低(<50MB)
局限:机械感明显(MOS评分3.2)
▍神经语音合成
采用Tacotron2+WaveGlow架构
支持端到端训练
MOS可达4.1分接近真人

建议选择FastSpeech2作为基线模型,其推理速度比传统方案快3倍,且支持韵律控制。
六步实现商业级系统
- ①
语音数据库构建专业录音室采集(信噪比>35dB)
建议20小时纯净语音+5种情感标签 - ②
韵律标注系统使用Praat工具标注:
• 基频轨迹(F0)
• 能量包络
• 音素边界 - ③
对抗训练策略引入GAN网络优化频谱细节
使用Multi-band MelGAN提升生成效率
关键优化指标
2%
在线服务可用性
≤200ms
端到端延迟
通过流式推理技术实现首包响应时间<80ms,支持实时语音交互场景。
合规性保障措施
- 通过ISO/IEC 27001信息安全管理认证
- 部署动态水印技术防止语音伪造
- 建立敏感词过滤库(覆盖3000+风险词条)
学术支持
- Ren Y, et al. FastSpeech 2: Fast and High-Quality End-to-End Text to Speech. ICLR 2021
- Google Research. Tacotron: Towards End-to-End Speech Synthesis. arXiv:1703.10135
- Speech Synthesis System Design Guidelines. IEEE Standard P.808