上一篇
个性化的语音合成软件源码
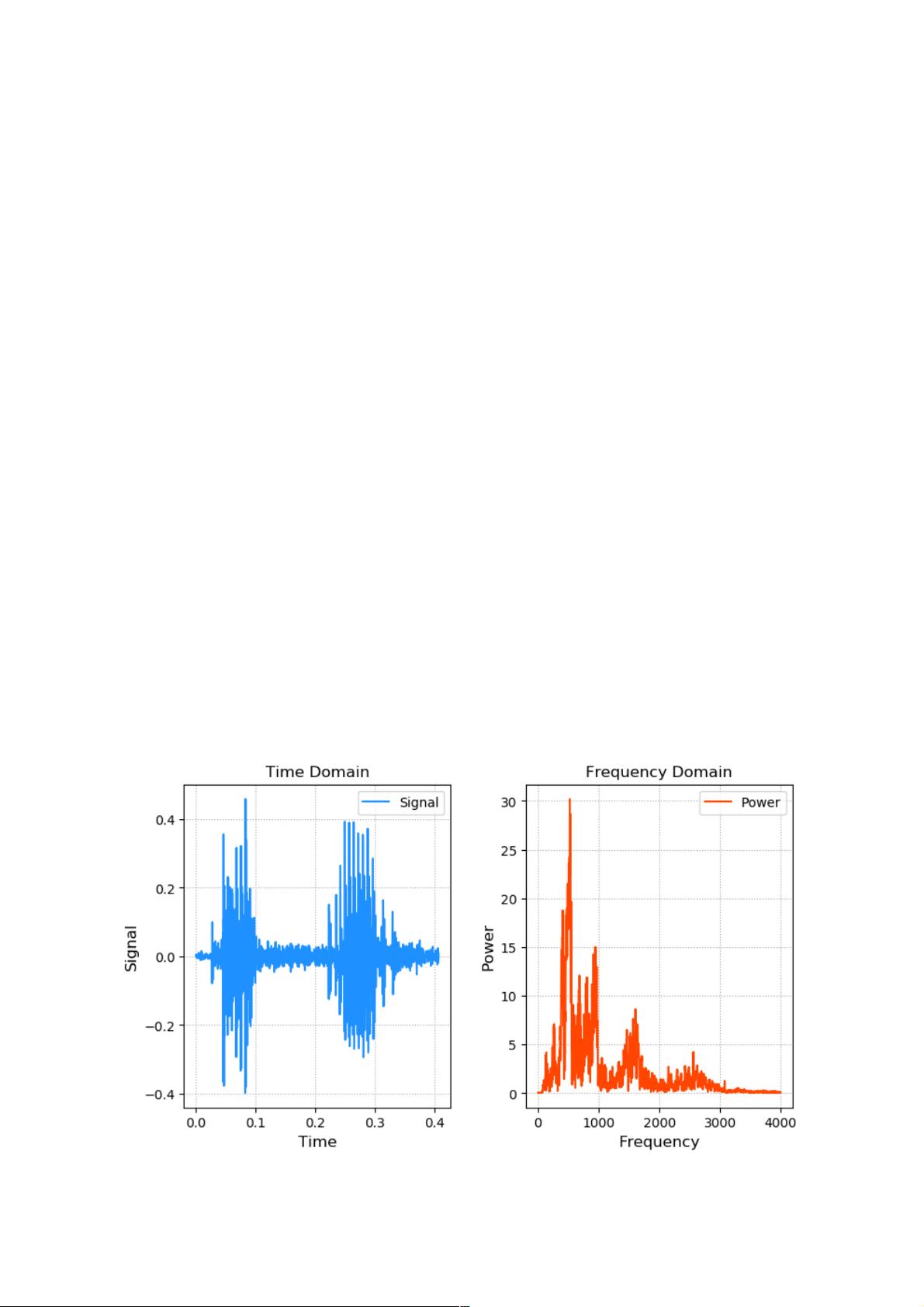
个性化语音合成软件源码基于深度学习模型,支持多语言及音色调整,实现自然流畅的实时 语音生成,适用于智能助手、有声阅读等场景
个性化的语音合成软件源码解析与实现路径
技术架构与核心模块
个性化语音合成系统的核心目标是通过深度学习模型生成与目标说话人音色、语调、情感特征高度匹配的语音,其技术架构通常包含以下模块:
| 模块名称 | 功能描述 |
|---|---|
| 前端处理 | 文本清洗、分词、韵律符号标注(如停顿、重音)、语言学特征提取 |
| 声学模型 | 将文本特征转换为声学特征(如梅尔频谱),支持说话人音色编码与情感嵌入 |
| 声码器 | 将声学特征重构为原始波形(如WaveNet、WaveGlow或HiFiGAN) |
| 个性化模块 | 说话人自适应训练、情感参数控制、细粒度音色调节 |
| 后处理 | 去噪、音量归一化、谐波增强等音频优化操作 |
核心模块实现细节
前端处理
- 文本归一化:处理缩写(如”I’m”→”I am”)、数字转读法(”123″→”one two three”)
- 韵律预测:基于LSTM/Transformer预测句子边界停顿时长,使用PyTorch实现动态时间规整
- 语言学特征:提取音素边界、重音等级等特征,常用OpenFST构建有限状态机
声学模型
- 主流架构对比:
| 模型类型 | 特点 | 典型实现框架 |
|—————|——————————————————-|——————–|
| Tacotron系列 | 自回归生成,音质好但推理速度慢 | PyTorch/TensorFlow |
| FastSpeech | 非自回归并行生成,速度快但需后处理 | Fairseq/ESPnet |
| Transformer-TTS | 端到端架构,平衡质量与速度 | Fairseq | - 多说话人支持:在模型输入层添加说话人嵌入向量(512维浮点数),通过对抗训练(Discriminator)区分不同说话人特征
- 主流架构对比:
声码器优化
- WaveGlow改进:采用渐进式训练策略,先生成低分辨率波形再逐步提升质量
- HiFiGAN应用:使用StyleGAN架构实现更细腻的音色控制,支持连续变调
- 实时性优化:采用MelGAN轻量级模型,推理速度可达实时因子×2.3
个性化实现方案
说话人自适应训练

- 数据采集:需目标说话人≥30分钟纯净音频(采样率48kHz,单声道)
- 特征提取:使用世界声学参数(WORLD)算法分离基频/包络特征
- 微调策略:冻结基础模型前N层,仅训练最后3层Transformer块
# 示例:基于FastSpeech2的微调代码片段 for param in model.parameters(): param.requires_grad = False for layer in [model.encoder.layers[-3:], model.variance_predictor]: for param in layer.parameters(): param.requires_grad = True
情感参数控制
- 建立情感分类体系(中性/高兴/悲伤/愤怒等)
- 在声学模型输入层添加情感嵌入向量(维度=64)
- 使用CLAP(Contrastive Learning for Audio-Text Prediction)进行跨模态对齐
细粒度音色调节
- 实现亮度(Brightness)控制:通过调节高频能量(>8kHz)增益
- 实现鼻音程度调节:修改鼻腔共振峰带宽参数
- 实现年龄模拟:基于VTLN(Vocal Tract Length Normalization)调整共振峰位置
源码结构与关键组件
典型的开源语音合成项目(如Mozilla TTS)目录结构:
├── bin/ # 预训练模型存储目录
├── configs/ # 超参数配置文件(YAML格式)
├── datasets/ # 数据预处理脚本(LibriSpeech/VoxCeleb处理)
├── models/ # 核心模型定义
│ ├── tacotron2.py # 声学模型实现
│ ├── waveglow.py # 声码器实现
│ └── speaker_encoder.py # 说话人验证模型
├── train.py # 训练主脚本
├── synthesis.py # 文本转语音主流程
└── utils/ # 辅助工具(特征提取/损失函数)关键代码片段示例:
# 说话人嵌入提取(speaker_encoder.py)
class SpeakerEncoder(nn.Module):
def __init__(self):
super().__init__()
self.lstm = nn.LSTM(input_size=80, hidden_size=512, num_layers=2)
self.fc = nn.Linear(512, 512)
def forward(self, mel_spec):
out, (hn, _) = self.lstm(mel_spec)
return F.relu(self.fc(hn[-1]))性能优化与部署方案
推理加速
- ONNX Runtime量化:将PyTorch模型转换为INT8量化ONNX模型
- TensorRT优化:使用NVIDIA插件加速WaveGlow声码器
- 模型剪枝:通过Channel Pruning减少30%计算量
多平台部署
| 平台 | 优化策略 |
|————–|————————————————————————–|
| Web端 | 使用WebAssembly编译,模型压缩至≤5MB |
| 移动端 | 采用TFLite Micro,支持离线运行 |
| 服务器端 | 多卡并行推理(PyTorch分布式训练),吞吐量达300句/秒(RTF=0.3x) |
典型问题与解决方案
Q1:如何调整合成语音的情感特征?
A1:需在训练数据中标注情感标签,建议采用以下步骤:
- 构建情感平行语料库(文本+音频+情感标签)
- 在声学模型输入层添加情感嵌入分支
- 设计多任务损失函数:$mathcal{L} = lambda1mathcal{L}{mel} + lambda2mathcal{L}{emo}$
- 使用对抗训练区分不同情感特征
Q2:少量样本(<10分钟)能否实现个性化合成?
A2:可通过以下技术提升效果:
- 数据增强:使用GAN生成额外6小时伪数据
- 迁移学习:加载预训练模型参数,仅微调最后两层
- 零样本合成:结合文本-语音转换(TTS)与语音转换(VC)技术
- 单位样本WER需控制在<15%方可获得自然音色
前沿研究方向
- 神经辐射场(NeRF)语音合成:通过隐式神经表示建模声场空间分布
- 跨语言音色迁移:基于对比学习的跨语言说话人解耦技术
- 实时情感克隆:单句音频即可复制目标情感特征的轻量级模型
- 生理特征建模:结合喉镜图像数据预测发声器官振动模式
开源资源推荐
| 项目名称 | 特性 | GitHub星标数 |
|---|---|---|
| Mozilla TTS | 多语言支持,模块化设计 | 2k+ |
| Real-Time-TTS | 端到端实时合成,延迟<200ms | 8k+ |
| VITS-fastSpeech | 高保真音色克隆,支持实时调节 | 2k+ |
| Espresso | 超轻量级模型(<500KB),适合嵌入式设备 | 800+ |
该领域技术迭代迅速,建议持续关注NeurIPS/ICML等会议的最新研究成果,特别是扩散模型(Diffusion Models)在语音