上一篇
hive是基于什么的数据仓库
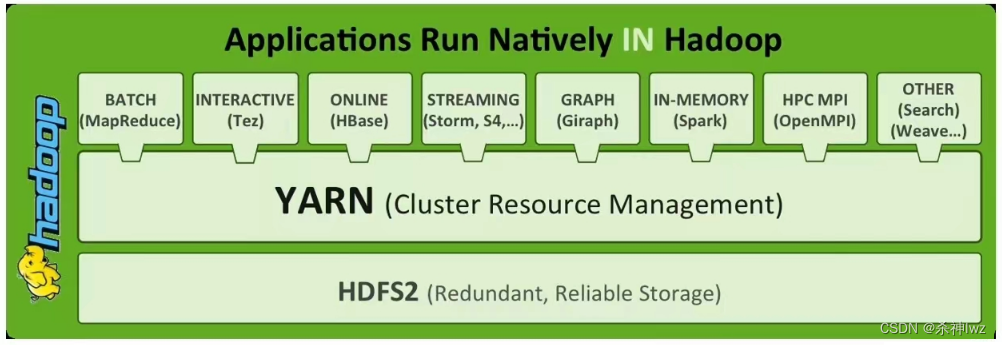
Hive是基于Hadoop的数据仓库工具,依托HDFS存储数据,利用MapReduce处理查询,支持类SQL的HQL语言,专为大规模数据仓库场景设计
Hive是基于Hadoop生态系统构建的分布式数据仓库工具,其核心设计目标是为大规模数据存储和分析提供高效的SQL-like查询能力,以下从技术架构、核心组件、存储模型等多个维度详细解析Hive的底层实现原理与特性。
Hive的技术基础
| 核心组件 | 技术实现 |
|---|---|
| 计算框架 | 依赖Hadoop MapReduce(也可集成Tez/Spark) |
| 存储系统 | HDFS(Hadoop Distributed File System) |
| 元数据管理 | 关系型数据库(默认MySQL/PostgreSQL) |
| 查询语言 | Hive QL (HQL) 类SQL语法兼容 |
| 客户端接口 | CLI/JDBC/ODBC/Thrift Server |
计算层:MapReduce的深度整合
Hive通过将HQL语句编译为一系列MapReduce任务实现分布式计算。
SELECT department, AVG(salary) FROM employees GROUP BY department;
会被拆解为:

- Map阶段:读取HDFS中的员工数据文件,按
department字段进行分区并计算局部平均值 - Reduce阶段:聚合所有分区的中间结果,生成全局平均值
这种设计使得Hive天然具备横向扩展能力,可通过增加Hadoop节点提升计算能力。
存储层:HDFS的优化使用
Hive表在HDFS中的存储结构具有以下特征:
- 分区表:按业务维度(如日期
dt=2023-10-01)划分子目录,减少全表扫描 - 文件格式:支持Text/ORC/Parquet等格式,其中ORC格式支持列式存储和压缩
- 桶表:通过哈希函数将数据分配到多个桶中,优化连接操作性能
典型存储路径示例:
/user/hive/warehouse/employees/dt=2023-10-01/employee_data.orc元数据层:关系型数据库的运用
元数据包括数据库、表结构、分区信息等,存储在独立的关系数据库中,关键作用:
- 元数据管理:维护表结构定义(Schema)、分区信息、权限控制
- 查询优化:存储统计信息(如行数、文件大小)辅助查询计划生成
- 事务支持:通过ACID事务表实现原子操作(需开启事务支持)
Hive的核心特性对比
| 特性 | Hive | 传统数据仓库(如Teradata) | 实时计算引擎(如Flink) |
|---|---|---|---|
| 数据规模 | PB级(依赖HDFS) | GB-TB级(受硬件限制) | 实时流处理(亚秒级延迟) |
| 查询延迟 | 分钟级(批处理) | 秒级(MPP架构优化) | 毫秒级(低延迟) |
| 扩展性 | 线性扩展(Hadoop集群) | 垂直扩展(专有硬件) | 水平扩展(容器化部署) |
| 成本 | 开源免费 | 高昂的软硬件投入 | 中等(Flink社区版免费) |
| 灵活性 | 支持复杂数据类型(JSON/AVRO) | 结构化数据为主 | 支持流批一体处理 |
Hive的典型应用场景
离线数据分析
- 日志处理:网站访问日志的UV/PV统计
- 用户行为分析:电商埋点数据的漏斗转化分析
- 报表生成:每日销售数据汇总报表
数据仓库建设
- ETL流程:通过HiveQL实现数据清洗、转换、加载
- 维度建模:星型/雪花模型构建企业级数据仓库
- 历史数据归档:长期存储冷数据并支持回溯查询
机器学习数据准备
- 特征工程:对原始数据进行预处理和特征提取
- 样本筛选:按时间范围/用户群体划分训练集
- 数据打平:将嵌套结构数据转换为宽表格式
Hive的技术架构详解
系统架构图
+----------------+ +----------------+ +------------------+
| Hive Clients | <---> | Hive Metastore| <---> | MySQL/PostgreSQL|
+----------------+ +----------------+ +------------------+
^ ^
| |
v v
+---------------------------------+---------------------------------+
| Hadoop Yarn | Hadoop HDFS |
| (Job Scheduling) | (Data Storage) |
+---------------------------------+---------------------------------+执行流程解析
- 语法解析:将HQL转换为抽象语法树(AST)
- 语义分析:检查表/列是否存在,数据类型校验
- 查询优化:基于规则/成本的优化器生成执行计划
- 任务提交:将执行计划拆分为多个MapReduce任务
- 结果合并:汇总各任务结果并返回给用户
存储格式对比
| 格式类型 | 特点 | 适用场景 |
|---|---|---|
| Text | 行式存储,无压缩,易解析 | 简单日志处理 |
| ORC | 列式存储,支持Zlib/Snappy压缩,高效列裁剪 | 复杂分析查询 |
| Parquet | 列式存储,支持多种压缩算法,跨平台兼容(Flink/Spark) | 数据共享与长期存储 |
| Avro | 列式存储,支持Schema演进,适合动态字段数据 | 日志收集与流处理 |
常见问题解答(FAQs)
Q1:Hive与传统数据库的主要区别是什么?
A:核心差异体现在三个方面:
- 数据量级:Hive面向PB级数据处理,传统数据库通常处理GB-TB级数据
- 计算模式:Hive采用批处理(分钟级延迟),传统数据库侧重实时查询(秒级响应)
- 扩展方式:Hive通过横向扩展Hadoop节点提升能力,传统数据库主要依赖垂直扩展
Q2:Hive是否支持实时数据分析?
A:原生Hive主要针对离线分析,但可通过以下方案实现近实时处理:
- 时间分区策略:按小时/分钟创建分区表,配合外部调度工具(如Oozie)定时加载新数据
- 集成流处理引擎:使用Kafka+Flume采集实时数据,通过Spark Streaming或Flink进行即时处理,最终结果写入Hive作为历史存档
- 增量查询优化:利用
INSERT OVERWRITE语句结合分区剪裁功能,仅处理最新数据分区
通过上述技术架构与特性分析可以看出,Hive凭借对Hadoop生态的深度整合,在处理海量结构化/半结构化数据时展现出显著优势,其核心价值在于将传统数据仓库的SQL能力与互联网级别的分布式存储计算相结合,为大数据分析提供了