上一篇
hive究竟算不算数据仓库
Hive属于数据仓库范畴,其基于Hadoop存储管理结构化数据,支持SQL查询与分析,具备 数据仓库的核心特征(主题导向、集成处理),但采用分布式架构和批处理模式,与传统数仓在技术实现上存在差异,(
Hive究竟算不算数据仓库?深度解析与对比分析
数据仓库的核心定义与特征
数据仓库(Data Warehouse)是一种面向主题的、集成的、非易失的、随时间变化的数据集合,用于支持企业决策分析,其核心特征包括:
- 面向主题:数据按业务主题(如销售、用户行为)组织,而非按业务过程。
- 集成性:整合来自多个异构数据源的数据,消除冗余和冲突。
- 非易失性:数据长期存储,主要用于查询而非频繁修改。
- 时间一致性:包含时间戳,支持历史数据分析。
- 大规模数据处理:支持TB/PB级数据存储和复杂查询。
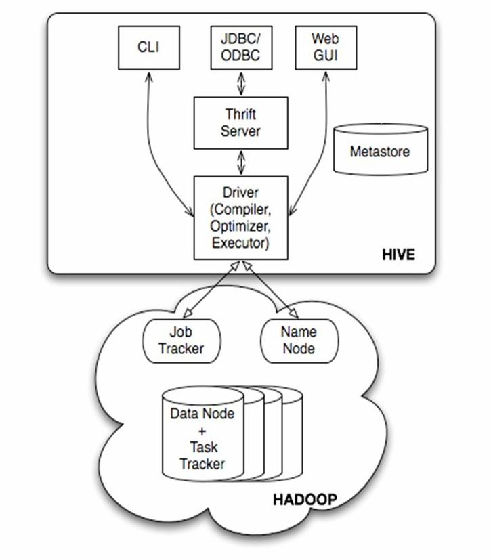
Hive的技术定位与架构
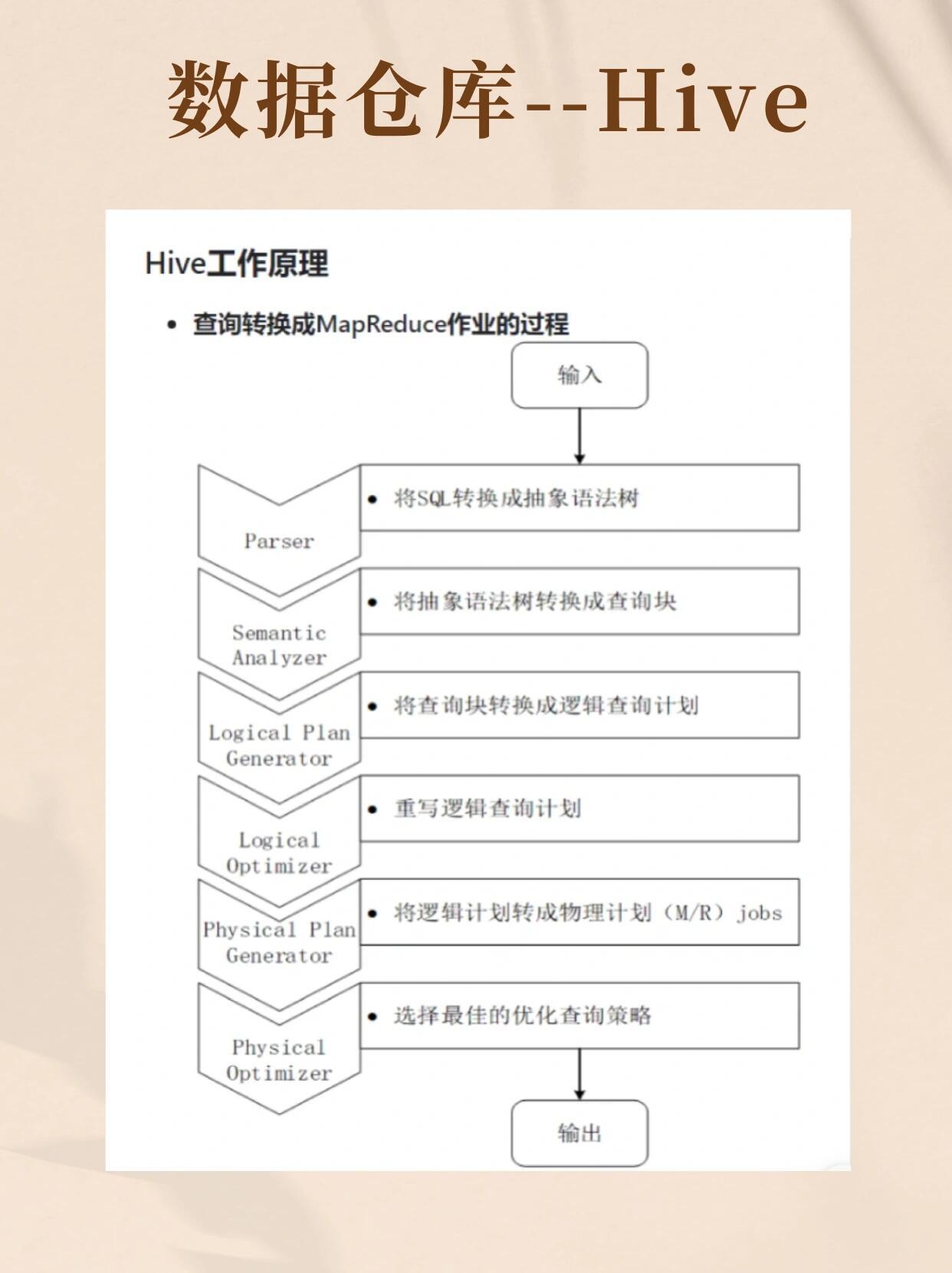
Hive是由Apache开源的基于Hadoop的数据仓库工具,其核心目标是通过类SQL语言(HiveQL)简化对大规模数据的分析和处理,其架构特点包括:
- 底层依赖:直接运行在Hadoop HDFS上,依赖MapReduce或Tez/Spark引擎执行查询。
- 数据模型:支持类似传统数仓的表、分区、桶(Bucket)等概念。
- 存储格式:默认使用文本文件(如CSV、JSON),但也支持SequenceFile、ORC等列式存储格式。
- 扩展性:通过水平扩展支持EB级数据存储,天然适应分布式环境。
Hive与传统数据仓库的对比
| 特性 | 传统数据仓库(如Teradata、Redshift) | Hive |
|---|---|---|
| 存储层 | 专用分布式存储(如MPP架构) | HDFS(分布式文件系统) |
| 计算引擎 | 优化的SQL引擎(支持ACID事务) | 依赖MapReduce/Tez/Spark(批处理为主) |
| 数据更新 | 支持实时/近实时更新 | 仅支持批量加载(INSERT OVERWRITE),无事务支持 |
| 查询延迟 | 亚秒级(优化后) | 分钟级(复杂查询可能更长) |
| 成本 | 硬件/软件成本高,扩展性受限 | 依赖廉价HDFS,横向扩展成本低 |
| 灵活性 | 结构化数据为主,扩展性有限 | 支持半结构化/非结构化数据(如JSON、AVRO) |
| 适用场景 | 企业级BI、实时报表 | 离线分析、海量数据ETL、历史归档 |
Hive是否符合数据仓库的核心标准?
主题建模与集成性
Hive支持通过外部表(External Table)集成多源数据,并通过PARTITION和CLUSTER BY实现数据逻辑组织,符合数据仓库的主题导向和集成性要求。非易失性与时间一致性
Hive表默认不支持更新/删除(除非使用事务表,需开启ACID),数据以追加方式写入,天然满足非易失性,时间字段可通过分区(如year=2023/month=06)实现历史数据管理。
大规模处理能力
Hive通过Hadoop集群实现PB级数据存储,结合调优(如ORC格式、压缩、向量化执行)可处理复杂查询,满足数据仓库的大规模分析需求。局限性
- 实时性不足:缺乏流式计算能力,依赖Kafka+Impala等组合实现近实时。
- 事务支持弱:仅事务表支持ACID,默认表无此能力。
- 查询延迟高:复杂查询可能耗时较长,不适合交互式分析。
Hive在现代数据架构中的角色
Hive通常作为大数据生态的“数据仓库层”,与其他工具协同工作:
- 数据湖与数仓融合:Hive可读写HDFS中的数据湖(如JSON、AVRO),同时通过分区和Schema演化支持结构化分析。
- ETL核心工具:通过
INSERT OVERWRITE实现数据清洗,结合Apache Sqoop导入传统数据库数据。 - 与实时引擎互补:Hive处理历史批量分析,Impala/Presto提供低延迟查询,Flink/Spark Streaming负责实时计算。
典型案例与适用场景
| 场景 | Hive的适用性 | 替代方案 |
|---|---|---|
| 日志分析(PB级) | 高扩展性、低成本存储,适合离线统计 | Elasticsearch(实时搜索) |
| 用户行为分析 | 支持复杂SQL(如窗口函数、GROUP BY) | ClickHouse(更快的OLAP) |
| 历史数据归档 | 数据不可变,适合长期存储 | Amazon S3+Glue |
| 实时报表 | 不适用(延迟高) | Redshift/Snowflake |
Hive是“大数据时代的数据仓库”
Hive完全符合数据仓库的核心定义(主题建模、集成性、非易失性),但其实现方式与传统数仓有显著差异:
- 技术路线:传统数仓依赖专用硬件和优化引擎,Hive则利用Hadoop生态实现弹性扩展。
- 场景适配:Hive更适合离线分析、海量历史数据处理,而非实时BI。
- 生态定位:在Lambda架构中,Hive承担批处理层职责,与实时计算引擎形成互补。
Hive既是数据仓库的一种实现,也是大数据时代对传统数仓的扩展,尤其适合互联网、AI等需要处理非结构化数据的场景。
FAQs
问题1:Hive和数据湖有什么区别?Hive能否作为数据湖使用?
答:
- 数据湖:存储原始、多样化的数据(结构化/半结构化/非结构化),强调灵活存储和按需处理。
- Hive:可在数据湖(如HDFS)上构建Schema,通过表抽象实现结构化分析,因此Hive是数据湖的“管理层”,而非数据湖本身。
- 区别:数据湖关注存储,Hive提供SQL接口;数据湖可无Schema,Hive需要定义Schema。
问题2:Hive是否支持实时数据分析?如何弥补其延迟缺陷?
答:
- 原生限制:Hive依赖MapReduce,查询延迟较高(分钟级),不适合实时场景。
- 解决方案:
- 近实时ETL:用Kafka+Spark Streaming将数据预处理后写入Hive。
- 加速查询:使用Impala或Presto替代Hive执行引擎,提升交互式分析速度。
- 混合架构:实时需求用ClickHouse/Druid