上一篇
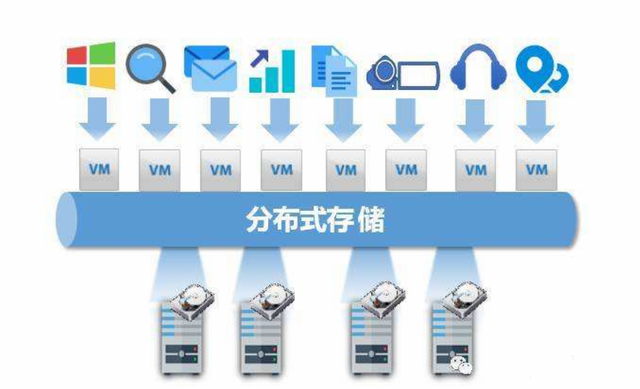
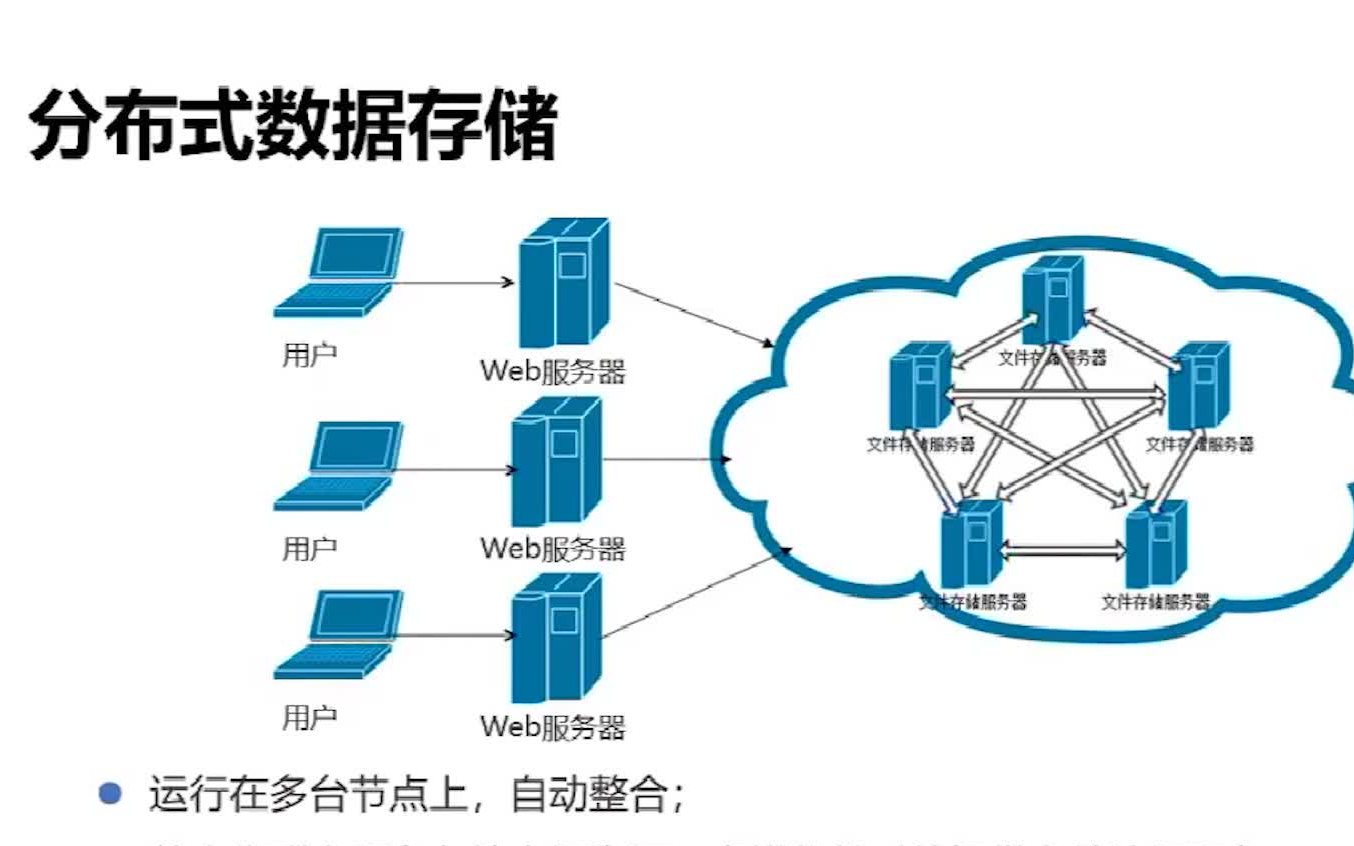
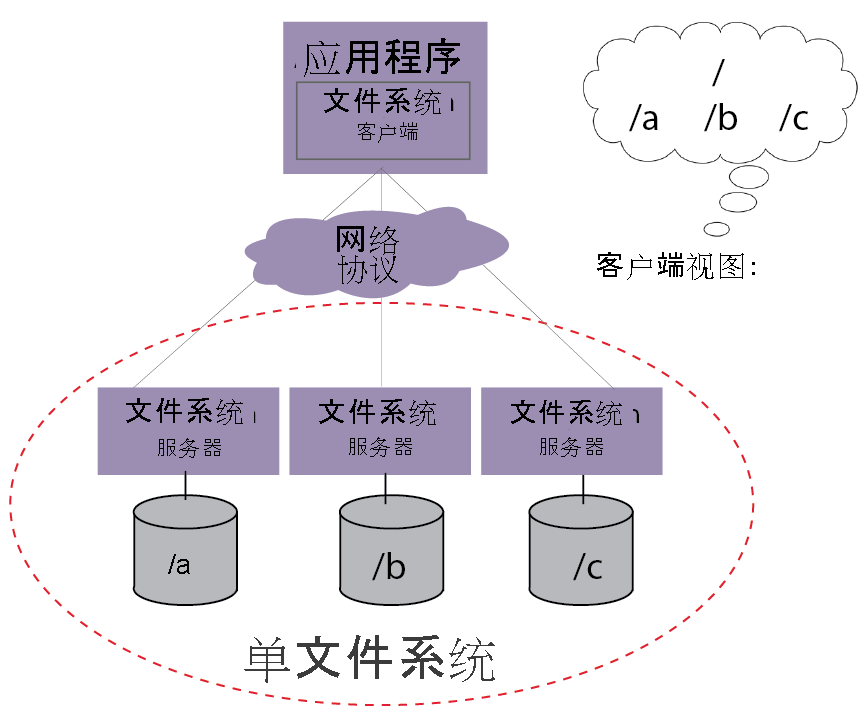
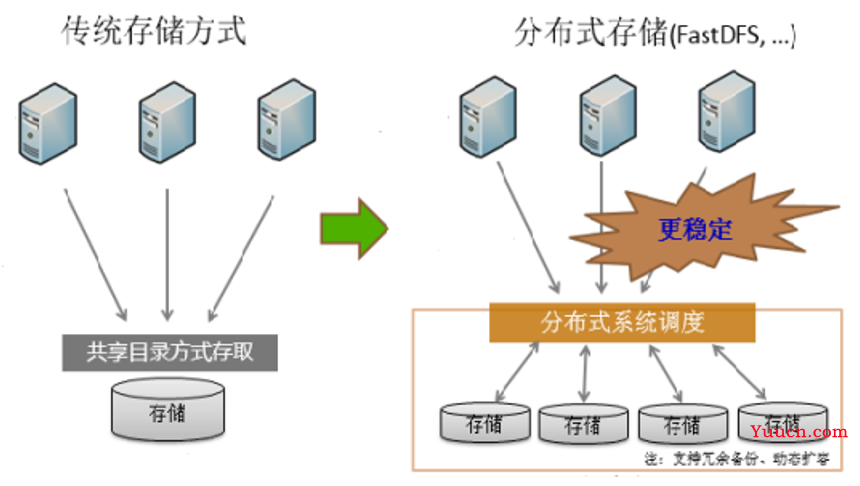
分布式文件存储有哪些变化
分布式存储向云原生演进,融合对象/块/文件多协议,强化容器化部署与AI
分布式文件存储的演变与技术变革分析
分布式文件存储作为支撑现代数据基础设施的核心技术,其发展历程经历了多次技术迭代与架构革新,从早期解决单机存储容量瓶颈的初步尝试,到如今支撑云计算、人工智能等复杂场景的智能化存储系统,其变化体现在架构设计、技术特性、应用场景及运维模式等多个维度,以下从技术演进路径、核心能力升级、场景适配扩展等方面展开详细分析。
架构设计层面的演变
| 阶段 | 传统集中式存储 | 第一代分布式存储 | 云原生分布式存储 | AI驱动型存储 |
|---|---|---|---|---|
| 节点角色 | 单一主控+多介质磁盘 | 主从式元数据服务器+存储节点 | 无中心化元数据服务(如Ceph) | 计算存储一体化节点 |
| 扩展方式 | 纵向扩容(硬件堆砌) | 横向扩展(添加存储节点) | 容器化动态扩缩容 | 存算资源联动弹性伸缩 |
| 数据一致性 | 本地事务保证 | 强一致性(如HDFS写前锁) | 最终一致性(DNS+版本控制) | 流式数据近似一致性 |
| 典型代表 | NAS/SAN | HDFS/GFS/Swift | MinIO/Rook+K8s | WeData/JuiceFS |
关键变化解读:

- 去中心化架构成熟:早期依赖主节点(如NameNode)的架构存在单点故障风险,新一代系统通过Raft协议实现元数据多副本同步(如Ceph MON集群),可用性从NMT(No Single Point of Failure)提升至99.99%级别。
- 存算分离到存算协同:传统HDFS严格区分计算节点与存储节点,而AI训练场景推动”近数据计算”模式,通过Smart NIC或GPU Direct技术实现计算任务直接访问存储节点内存,减少网络传输延迟。
核心能力升级对比
| 能力维度 | 传统分布式存储 | 现代分布式存储 | 增强特性 |
|---|---|---|---|
| 容量管理 | 静态分区划分 | 动态容量均衡(CRUSH算法) | 自动数据迁移、冷热分层 |
| 性能优化 | 机械硬盘顺序写入优化 | NVMe SSD随机读写优化 | IO隔离(QoS)、RDMA网络加速 |
| 数据保护 | RAID阵列+定时快照 | EC纠删码(如Reed-Solomon) | 跨AZ多副本、数据沙箱演练 |
| 安全机制 | 基础ACL权限控制 | 传输加密(TLS 1.3)+ SSE加密 | 零信任架构、隐私计算(如TEE隔离) |
技术突破点:
- 纠删码替代副本:传统3副本存储成本高达150%,现代采用EC 8+4策略(8份数据+4份校验)将冗余率降至40%,同时支持局部重建(如Azure Blob Storage的LRC)。
- 混合存储池:通过软件定义存储(SDS)实现HDD/SSD/内存分级,阿里云ESSD采用LSM-Tree结构实现热温冷数据自动分层,IOPS提升300%。
应用场景扩展与需求适配
| 场景类型 | 传统适用场景 | 新兴场景挑战 | 存储系统应对方案 |
|---|---|---|---|
| 大数据分析 | 批处理作业(MapReduce) | 实时流处理(Flink/Spark Streaming) | 支持ACID事务的Delta Lake格式 |
| AI训练 | 静态数据集加载 | 动态模型参数同步(Checkpointing) | 显存扩展(如WeKAIFA的显存聚合) |
| 边缘计算 | 数据中心内部署 | 断网容忍(如自动驾驶数据缓存) | 数据预取+本地修复机制 |
| 多云环境 | 单一云平台 | 跨云数据流动 | 统一命名空间(如S3兼容API)+ 数据锚点 |
典型案例:
- 基因测序分析:华大基因采用分布式文件系统承载PB级基因组数据,通过并行文件切分(ChunkShard)实现200+计算节点并发访问,比传统HPC存储提速4倍。
- 元宇宙资产存储:Decentraland利用IPFS分布式文件存储管理数字孪生模型,通过内容寻址(CID)确保全球玩家低延迟访问,同时抵御DDoS攻击。
运维模式与经济性变革
| 运维指标 | 传统运维 | 智能运维 | 成本优化手段 |
|---|---|---|---|
| 故障恢复 | 人工排查+脚本恢复 | AI异常检测(如时序数据分析) | 混沌工程(Chaos Monkey)自动演练 |
| 资源利用率 | 固定配额分配 | 弹性配额+空闲资源回收 | 存储即代码(StorAGE)动态调度 |
| TCO降低 | 硬件采购锁定厂商 | 异构硬件混部(ARM+x86) | 闲时压缩(ZFS LZ4压缩)+按需计费 |
经济性提升数据:
- 酷盾安全COS通过对象生命周期管理使存储成本下降40%,冷数据存储单价低于0.02元/GB/月。
- 华为云EFS使用AI预测容量需求,将资源预留量从30%降至8%,节省数百万闲置费用。
FAQs
Q1:如何为机器学习场景选择分布式存储?
答:需重点考察三个维度:①是否支持大文件流式读取(避免HDFS小文件瓶颈),②是否具备数据版本管理能力(方便实验回滚),③是否集成特征存储加速(如Alluxio内存缓存),建议采用支持Prefetch预读和Checkpoint增量同步的系统,如Dell ECS或QuotaFS。
Q2:多云环境下如何保证数据一致性?
答:可采用两种方案:①基于强一致性协议(如Paxos)构建跨云元数据服务,②使用数据版本哈希校验+事件溯源记录变更,推荐工具包括Portworx(容器化存储抽象)和Rook