上一篇
分布式流式计算简介
分布式流式计算通过实时处理连续数据流,依托分布式架构实现并行计算与横向扩展,具备低延迟、高吞吐特性,适用于实时数据分析、监控预警等场景,提升业务
分布式流式计算简介
定义与核心特征
分布式流式计算(Distributed Stream Processing)是一种基于分布式架构的实时数据处理技术,能够对连续产生的数据流进行低延迟、高吞吐量的处理,与传统批处理(如MapReduce)不同,流式计算无需等待数据全部收集完成,而是以事件驱动的方式逐条或逐批次处理数据,适用于需要实时响应的场景。
核心特征:
- 实时性:数据从产生到处理完成的延迟极低(毫秒级)。
- 连续性:处理对象是无边界的连续数据流(如日志、传感器数据)。
- 分布式:通过多节点并行计算实现横向扩展,支持海量数据处理。
- 容错性:系统需具备节点故障自动恢复能力,保证数据不丢失。
核心组件与架构
分布式流式计算系统通常由以下组件构成:
| 组件 | 功能描述 |
|---|---|
| 数据源 | 产生连续数据流(如Kafka、日志、传感器网络),支持多节点写入。 |
| 流处理引擎 | 核心计算模块(如Flink、Spark Streaming),负责任务调度、数据分区和状态管理。 |
| 存储系统 | 持久化中间状态或结果(如HDFS、Redis),支持容错和恢复。 |
| 协调服务 | 管理集群元数据(如ZooKeeper),实现任务分配和故障检测。 |
| 客户端/输出端 | 接收处理结果(如数据库、消息队列、实时仪表盘)。 |
典型架构流程:

- 数据源持续生成数据流并分发到各计算节点。
- 流处理引擎按规则(如过滤、聚合、窗口计算)处理数据。
- 中间状态通过分布式存储系统持久化,避免单点故障。
- 处理结果实时推送至下游系统或存储。
关键技术解析
分布式流式计算的实现依赖多项核心技术:
| 技术点 | 实现方式 |
|---|---|
| 数据分区 | 按Key哈希分区(如Kafka Partition)或自定义规则,确保数据均匀分布。 |
| 容错机制 | 通过副本存储(如Kafka副本)、检查点(Checkpointing)和日志重放实现故障恢复。 |
| 状态管理 | 维护算子状态(如窗口计数器),使用外部存储(如RocksDB)保证状态一致性。 |
| 时间窗口 | 滑动窗口(Sliding Window)或滚动窗口(Tumbling Window)处理无序或延迟数据。 |
| Exactly-Once | 结合事务协议(如Flink的两阶段提交)和WAL(预写日志)保证精确一次处理。 |
主流框架对比
以下是三种主流流式计算框架的对比:
| 特性 | Apache Flink | Apache Spark Streaming | Apache Storm |
|---|---|---|---|
| 延迟 | 低(毫秒级) | 中等(秒级) | 低(毫秒级) |
| 状态管理 | 内置精准状态管理 | 依赖外部存储 | 需手动管理 |
| 容错性 | 基于检查点的增量恢复 | 微批处理快照 | 基于ACK的主动恢复 |
| 编程模型 | 流批一体(DataStream API) | 微批处理(DStream) | 纯流式(Spout-Bolt) |
| 适用场景 | 复杂事件处理、实时分析 | 近实时处理、机器学习 | 简单流处理、低延迟场景 |
应用场景与案例
实时监控:
- 场景:服务器日志实时分析,检测异常请求或错误。
- 技术:通过Flink聚合窗口统计每分钟错误率,触发告警规则。
金融交易:
- 场景:股票行情实时计算,高频交易策略执行。
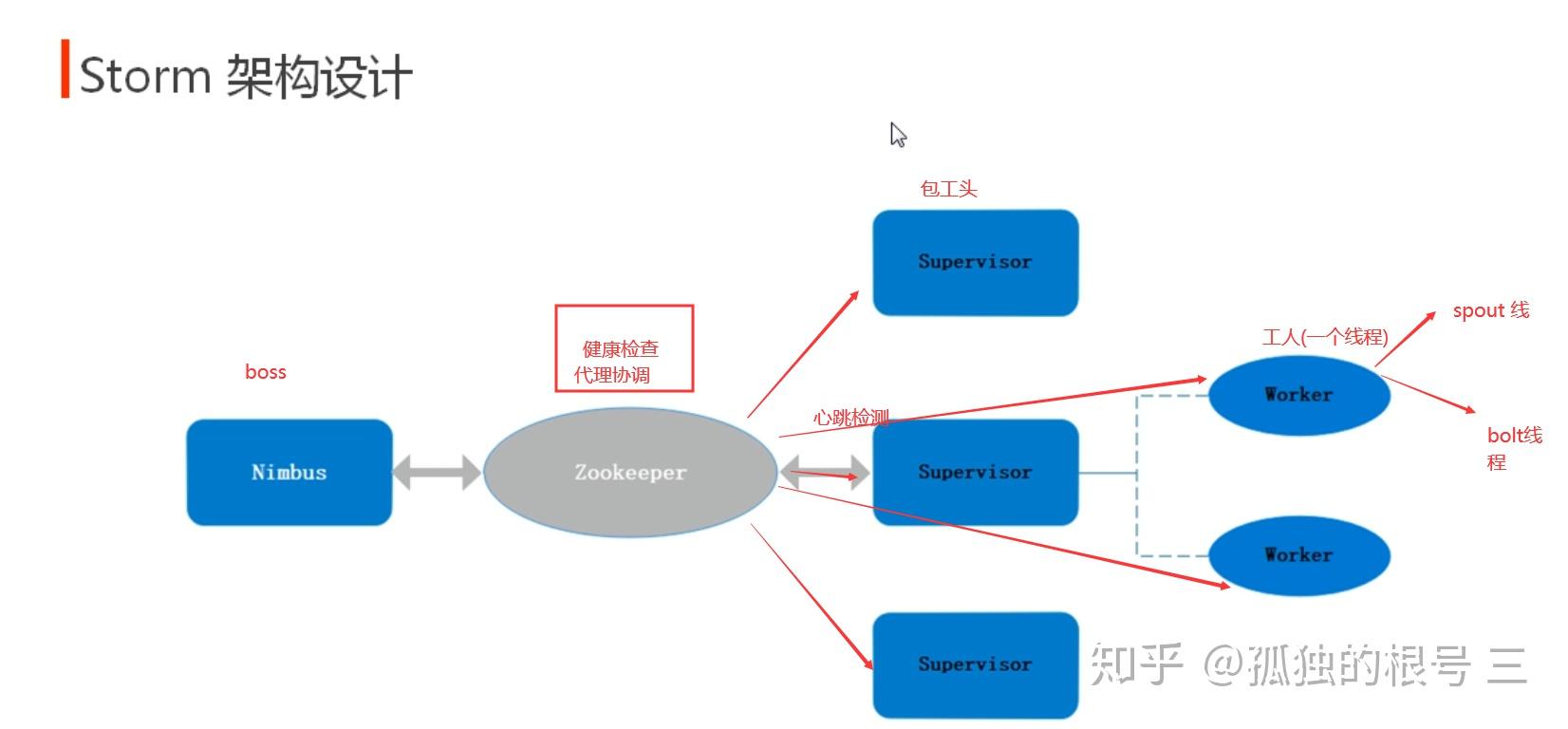
- 技术:Storm处理交易所数据流,结合机器学习模型预测趋势。
物联网(IoT):
- 场景:传感器数据实时处理,设备故障预测。
- 技术:Kafka传输数据,Spark Streaming计算设备状态特征值。
挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 数据乱序与延迟 | 使用事件时间(Event Time)语义,结合水位线(Watermark)机制。 |
| 状态爆炸 | 采用状态后端优化(如RocksDB)、TTL(时间窗口过期清理)减少存储压力。 |
| 资源动态扩缩容 | 通过Kubernetes容器化部署,结合自适应调度算法(如Flink的Resource Manager)。 |
FAQs
Q1:流式计算与批处理的本质区别是什么?
A1:流式计算处理无边界的连续数据流,追求低延迟和实时性;批处理针对静态数据集,通过划分批次完成任务(如Hadoop MapReduce),流式计算可用于实时欺诈检测,而批处理适合离线用户行为分析。
Q2:如何选择Flink、Spark Streaming或Storm?
A2:
- Flink:适合复杂事件处理(如状态ful操作、精确一次语义)。
- Spark Streaming:兼容Spark生态,适合与机器学习、SQL结合的近实时场景。
- Storm:适用于低延迟、简单流处理(如日志清洗),但需手动