上一篇
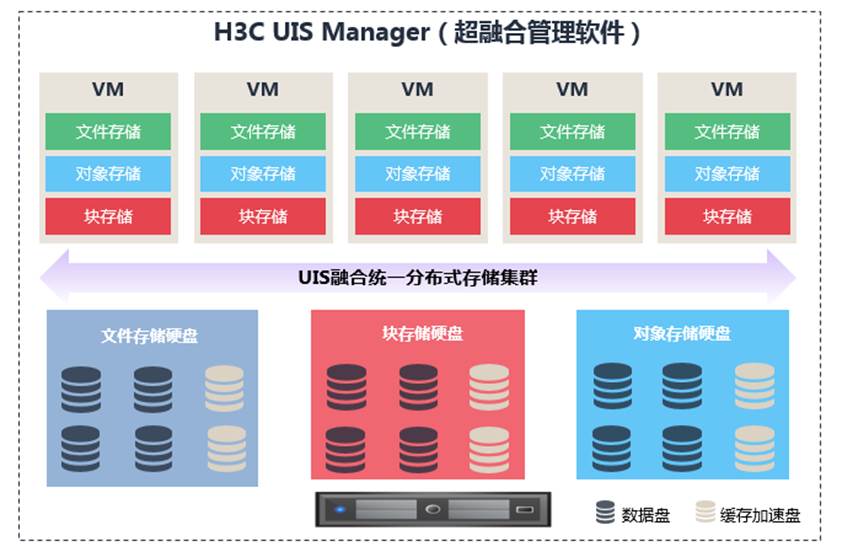
分布式流批统一存储
分布式流批统一存储通过共享架构实现实时与批量数据处理的高效协同,优化资源利用,降低成本,保障 数据一致性与低
技术架构与实践解析
背景与需求驱动
随着大数据与实时计算技术的融合,企业对数据存储系统的要求从单一场景(批处理或流处理)向流批一体化演进,传统架构中,批处理(如Hive、Spark)与流处理(如Kafka、Flink)通常采用独立存储系统,导致数据冗余、同步延迟高、维护成本大。分布式流批统一存储通过一套存储层同时支撑离线计算、实时分析、Ad-hoc查询等多元需求,成为破解”数据孤岛”问题的关键方案。

核心概念与技术特征
| 特性 | 传统分离存储 | 流批统一存储 |
|---|---|---|
| 数据一致性 | 流批数据物理隔离,需ETL同步 | 共享存储层,读写强一致性保障 |
| 延迟 | 分钟级批处理延迟 | 秒级近实时处理 |
| 存储成本 | 多副本存储导致资源浪费 | 数据去重与生命周期管理优化成本 |
| 计算模式 | 批流任务独立调度 | 统一计算引擎(如Flink SQL)支持混合作业 |
关键技术要素:
- 分层存储模型:结合热温冷数据分层(如HDFS+内存/SSD+对象存储),满足不同访问频率需求。
- 时间窗口抽象:通过时间戳标记数据版本,支持流式Upsert与批量Overwrite操作。
- 混合索引机制:
- 流式场景:基于LSM-Tree的增量索引(如RocksDB)
- 批处理场景:列式存储+倒排索引(如Parquet+ZOrder)
- ACID/BASE混合事务:
- 批处理要求ACID保证数据准确性
- 流处理采用BASE模型提升吞吐量
架构设计要点
存储引擎层
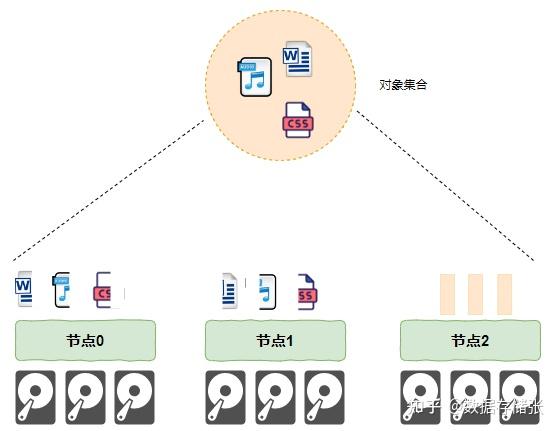
- 数据湖架构:以Apache Hudi/Iceberg为代表的数据湖格式,通过Merge On Read实现流批数据统一写入。
- 元数据管理:采用Hive Metastore或独立服务(如Uber Zanzibar)维护表schema、分区信息。
- 存储介质适配:
- 热数据:本地SSD+内存缓存
- 冷数据:HDD/对象存储(如S3)
计算引擎层
- 统一SQL接口:通过Flink SQL/Trino等引擎提供标准SQL,屏蔽流批差异。
- Checkpoint机制:周期性生成数据快照,支持故障恢复与历史回溯。
- 资源隔离策略:动态分配CPU/Memory资源,避免批作业阻塞实时查询。
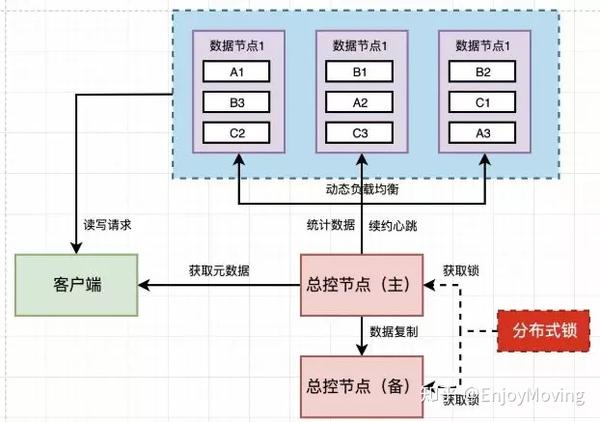
数据一致性保障
- 恰好一次语义:依赖分布式事务协议(如Two-Phase Commit)保证跨存储节点一致性。
- 时间戳对齐:采用事件时间(Event Time)而非摄入时间(Ingestion Time),解决乱序数据问题。
- 冲突解决策略:
- 流式更新:Last Write Wins(LWW)
- 批量修正:基于版本号的冲突检测
典型应用场景
| 场景 | 业务需求 | 存储设计 |
|---|---|---|
| 实时数仓 | 秒级OLAP分析+小时级ETL | Kafka+Hudi(流式写入)+Iceberg(批处理) |
| 日志聚合 | PB级日志存储+实时搜索 | Elasticsearch+Hadoop归档 |
| 金融风控 | 毫秒级交易反欺诈+日终结算 | Kafka Streams+HBase(行式存储) |
| IoT设备管理 | 亿级设备数据采集+月度分析报告 | TimescaleDB(时序数据)+S3冷存储 |
挑战与解决方案
数据新鲜度与查询延迟矛盾
- 问题:实时查询需要最新数据,但频繁Compaction影响写入性能。
- 方案:采用读写分离架构,写入路径使用LSM-Tree,查询路径通过BloomFilter加速检索。
异构计算负载混部
- 问题:批作业全量扫描与流作业点查争抢资源。
- 方案:引入分级存储策略:
- 热数据:保留最近1小时数据在内存
- 温数据:保留1天数据在SSD
- 冷数据:下沉至HDD/对象存储
Schema演化兼容性
- 问题:流式数据Schema频繁变更导致历史数据不可读。
- 方案:支持Schema Evolution,通过字段标记(如
__deleted_field)兼容新旧版本。
业界实践案例
| 企业 | 技术栈 | 关键创新点 |
|---|---|---|
| 阿里巴巴 | HiStore(自研)+MaxCompute | 流批共享存储+存算分离架构 |
| 字节跳动 | Kafka+Hudi+Doris | 实时数仓与离线分析混合部署 |
| Snowflake | Native Mutation+Time Travel | 无锁并发写入+历史版本秒级回溯 |
FAQs
Q1:分布式流批统一存储与传统数据湖有什么区别?
A1:传统数据湖(如Hive+HDFS)主要面向批处理场景,缺乏流式写入能力与实时查询优化,流批统一存储通过支持Upsert操作、增量Compaction、低延迟索引等特性,实现了流批混合负载的高效处理,Apache Hudi在数据湖基础上增加了时间旅行(Time Travel)、流式消费(Streaming Source)等功能。
Q2:如何评估企业是否需要流批统一存储?
A2:可从三个维度判断:
- 业务实时性要求:是否需同时支持实时Dashboard与T+1报表
- 数据重复度:是否存在超过30%的跨系统数据冗余
- 运维复杂度:是否面临多套存储系统的版本升级与容灾压力
若以上任一条件成立,流批统一存储将显著提升资源利用率与