
上一篇
hbase数据存储
HBase数据存储基于表结构,由行键、列族、 列限定符和时间戳组成,按行键排序存储,支持多版本,依托HD
HBase数据存储机制详解
HBase是一种基于列式存储的分布式数据库,其数据存储设计以高可靠性、高可扩展性为核心目标,以下从存储结构、写入流程、读取流程、数据删除与过期策略、存储优化等角度详细解析HBase的数据存储机制。
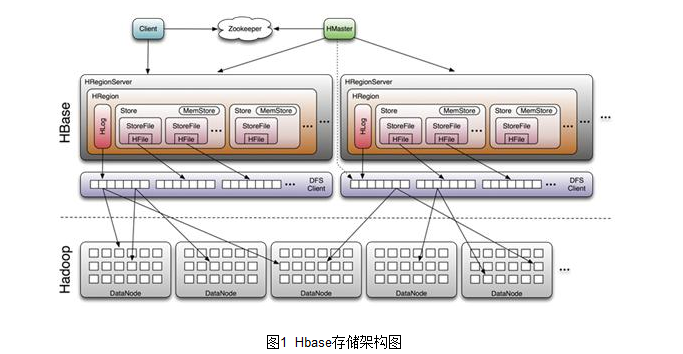
HBase存储结构
HBase的存储结构是分层设计的,核心组件包括表(Table)、Region、Store、StoreFile(HFile)和MemStore,以下是关键层级的说明:
| 层级 | 功能描述 |
|---|---|
| Table | 逻辑上的二维表结构,由行键(RowKey)、列族(Column Family)和单元格(Cell)组成。 |
| Region | 表的横向分片,每个Region包含多个行键范围(如startKey到endKey),默认大小为10GB(可配置)。 |
| Store | 每个Region对应一个列族,一个列族对应一个Store,负责存储该列族的所有数据。 |
| MemStore | 内存中的写缓冲区,用于暂存未持久化的数据,每个Store对应一个MemStore。 |
| HFile | 磁盘上的存储文件,由MemStore刷新后生成,支持多版本合并和压缩。 |
| BlockCache | 缓存已读取的Block块,减少磁盘IO,提升读性能。 |
数据存储流程:
- 数据写入时,先存入MemStore和WAL(Write-Ahead Log)。
- MemStore满后,触发Flush操作,将数据写入HFile。
- HFile在后台通过Compaction(合并)和Major Compaction(大合并)优化存储。
数据写入流程
HBase的写入流程以“高可靠”和“低延迟”为目标,具体步骤如下:

- 客户端请求:客户端通过RPC向RegionServer发送写入请求。
- Region定位:通过ZooKeeper或Meta表查找目标Region所在的RegionServer。
- 写入WAL:数据先写入WAL(预写日志),确保故障时可恢复。
- 写入MemStore:数据按列族写入对应的MemStore(内存中)。
- 触发Flush:当MemStore达到阈值(如128MB)或超过时间窗口时,触发Flush。
- 生成HFile:Flush时,MemStore中的数据按行键排序后写入HFile,并清理WAL。
写入优化:
- WAL分组提交:多个写入操作合并为一个WAL条目,减少日志开销。
- 批量写入:支持Pipeline模式,客户端可连续发送多个写入请求。
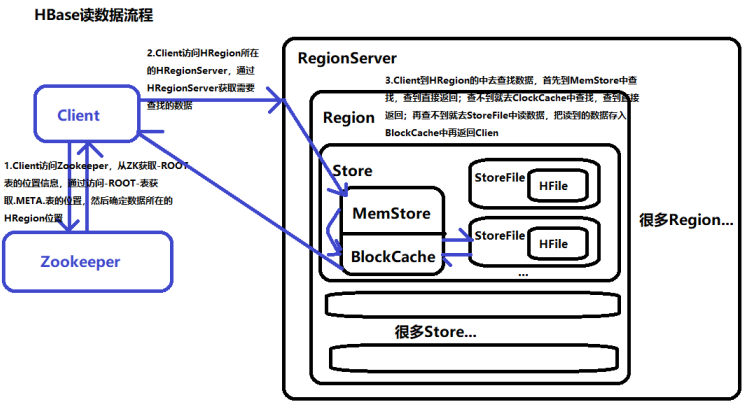
数据读取流程
HBase的读取流程依赖缓存和索引加速,具体步骤如下:
- 定位Region:通过Meta表确定目标RowKey所在的Region。
- 查询MemStore:优先从MemStore中读取最新数据。
- 查询BlockCache:若MemStore未命中,则从BlockCache中查找已缓存的Block。
- 读取HFile:若缓存未命中,需读取HFile中的Data Block和Index Block。
- Index Block:存储行键索引,快速定位目标Block。
- Data Block:存储实际数据,支持压缩(如Snappy、LZO)。
- 合并多版本:若存在多个版本的数据,按时间戳合并返回。
读取优化:
- BloomFilter:在HFile层面过滤不存在的行键,减少无效IO。
- BlockCache预热:高频访问的Block会被提前加载到缓存。
数据删除与过期策略
HBase通过标记删除和物理删除结合的方式管理数据生命周期:
- 标记删除:
- 删除操作仅标记Deletion Marker,不会立即移除数据。
- 后续读取时跳过被标记的单元格。
- 物理删除:
在Compaction或Major Compaction时,清理被标记的过期数据。
- TTL(Time-to-Live):
通过设置列族的TTL属性,自动删除超过生存周期的数据(如日志类数据)。
- 版本管理:
- 默认保留至少1个版本的数据,可通过
VERSIONS参数控制最大版本数。
- 默认保留至少1个版本的数据,可通过
存储优化策略
| 优化项 | 说明 |
|---|---|
| MemStore大小调整 | 根据业务写入量调整MemStore大小(如增大以减少Flush频率)。 |
| HFile合并策略 | 通过hbase.hregion.majorcompaction控制大合并触发条件,避免频繁合并。 |
| 数据压缩 | 启用Snappy/LZO压缩算法,降低存储空间和网络传输成本。 |
| 预分区(Pre-Splitting) | 对大表提前创建Region,避免后期热点写入导致负载不均。 |
| 缓存配置 | 调整BlockCache大小(hfile.block.cache.size)以提升读性能。 |
FAQs
Q1:HBase与传统关系型数据库(如MySQL)的存储差异是什么?
A1:HBase是列式存储,按列族组织数据,适合稀疏列和海量写入;而MySQL是行式存储,适合事务性强的结构化数据,HBase无二级索引,依赖RowKey设计实现高效查询。
Q2:如何应对HBase中单个Region过热的问题?
A2:可通过以下方式解决:
- 预分区:提前将大表拆分为多个Region。
- RowKey设计:采用哈希或反转RowKey,分散写入压力。
- 动态Split:启用自动Split功能,当Region
相关文章
如何实现MapReduce作业中从HBase读取数据后再将结果高效地写回HBase?

云数据库HBase版,HBase协议兼容实例如何实现?
如何通过MapReduce从HBase读取数据并重新写入HBase?
探秘Base服务器:让你的数据存储更便捷 (base服务器)

SEO行业是否正面临前所未有的焦虑与挑战?,你如何看待当前SEO行业的焦虑现状?,你是否也对SEO行业的现状感到焦虑?,SEO行业的现状是否引发了你的担忧和思考?,你对SEO行业的未来有何看法?,你是否认为SEO行业正在经历一场变革?,你对SEO行业的发展趋势有何预测?,你是否觉得SEO行业的竞争压力越来越大?,你是否认为SEO行业需要更多的创新和改革?,10. 你对SEO行业的未来发展有何期待?

HBase中的数据存储结构是怎样的

OceanBase数据库咨询下创建 OBProxy 集群无法对接OceanBase 集群什么原因?
OceanBase数据库连接mysql和tidb都连得上但连oceanbase就报错了密码是正确的?







