
上一篇
hbase数据压缩
HBase支持表级和区域级数据压缩,采用Snappy、GZIP等算法减少存储空间与I/O消耗,但需平衡CPU资源
HBase数据压缩机制详解与实践指南
HBase数据压缩的核心概念
HBase作为分布式列式存储系统,其数据压缩功能主要针对存储在HDFS上的HFile文件,压缩过程发生在数据写入阶段,由RegionServer在构建HFile时完成,而读取时则由客户端或RegionServer解压缩,压缩策略直接影响存储空间利用率、网络传输效率及CPU资源消耗。
关键特性:
- 块级压缩:以Block为单位进行压缩(默认32KB/64KB)
- 列族粒度控制:可为不同列族配置独立压缩算法
- 动态可配置:支持运行时调整压缩策略
- 透明解压:客户端无需感知压缩过程
HBase支持的压缩算法对比
| 算法类型 | 压缩率 | CPU开销 | 可分割性 | 典型场景 |
|---|---|---|---|---|
| SNAPPY | 中(40-60%) | 低 | 是 | 高吞吐写入 |
| GZIP | 高(60-80%) | 高 | 否 | 冷数据存档 |
| LZO | 中(50-70%) | 中 | 是 | 混合读写场景 |
| BZIP2 | 高(70-90%) | 极高 | 否 | 极限压缩比 |
| ZSTD | 高(60-85%) | 中高 | 是 | 现代通用场景 |
| LZ4 | 低(30-50%) | 极低 | 是 | 实时分析 |
| NONE | 禁用压缩 |
技术实现差异:
- 可分割性:指压缩块能否被并行处理,如GZIP生成单个大压缩块,导致读取时需要全块解压
- 延迟敏感场景:LZ4/SNAPPY等轻量级算法更适合实时查询
- 批处理场景:GZIP/BZIP2适合离线批量处理任务
压缩配置与调优实践
全局配置(hbase-site.xml)
<property> <name>hbase.regionserver.hfile.block.compression</name> <value>SNAPPY</value> <!-可选值:NONE/GZ/LZO/BZIP2/SNAPPY/ZSTD/LZ4 --> </property> <property> <name>hbase.client.keyvalue.maxsize</name> <value>1048576</value> <!-配合压缩调整Block大小 --> </property>
列族级配置
TableDescriptorBuilder builder = TableDescriptorBuilder.newBuilder(tableName);
ColumnFamilyDescriptor cfDesc = ColumnFamilyDescriptorBuilder.newBuilder(columnFamily)
.setBlockCompression(BlockCompression.LZO)
.build();
builder.setColumnFamily(cfDesc);动态调整策略

- 通过HBase Shell临时关闭压缩:
ALTER 'table', {NAME => 'cf', BLOCK_COMPRESSION => 'NONE'} - 使用HDFS工具验证压缩效果:
hadoop fs -stat %o /path/to/hfile
性能影响深度分析
写入性能
- CPU负载:压缩算法复杂度直接影响RegionServer的编码耗时
- 网络带宽:压缩后数据量减少约30-70%,降低RPC传输压力
- 存储IO:HDFS写入小文件时,压缩可减少寻道次数
读取性能
- 解压延迟:每个Block需执行解压操作,LZO比GZIP快5-10倍
- 缓存命中率:压缩后数据块更小,有利于BlockCache利用
- 扫描效率:可分割算法允许跳过无关Block,提升随机读性能
资源消耗模型
!压缩算法资源消耗对比 (示意图)
最佳实践推荐
场景1:日志型写入为主的业务
- 优先选择SNAPPY/LZ4
- 配置Block大小64KB
- 开启自动flush合并小文件
场景2:历史数据归档
- 采用GZIP/BZIP2
- 结合HBase生命周期管理冻结旧数据
- 设置TTL自动删除过期数据
场景3:混合读写工作负载
- LZO/ZSTD折中选择
- 通过HBase UI监控
RegionServer的CPU使用率 - 建立压缩比与查询延迟的基线指标
高级优化技巧
分层存储策略:
- 热数据:无压缩/LZ4
- 温数据:SNAPPY
- 冷数据:GZIP+LruCache
自适应压缩:
// 根据数据特征动态选择算法 if (isTimeSeriesData) { useLZ4(); } else if (isJsonData) { useZSTD(); }硬件协同优化:
- Intel QuickSync支持的硬件加速压缩
- 配置JVM参数启用多线程压缩:
-XX:+UseCompressedOops
常见问题诊断
问题1:压缩后查询变慢
- 检查是否使用不可分割算法(如GZIP)
- 验证Block大小设置是否合理(建议32-128KB)
- 查看RegionServer的CPU等待时间是否过高
问题2:压缩率未达预期
- 确认数据是否具备可压缩特征(如重复文本)
- 检查列族配置是否覆盖所有目标列
- 使用HDFS
-text命令抽样验证压缩效果
FAQs
Q1:如何判断当前表是否开启了数据压缩?
A1:可通过以下方式验证:
- 使用HBase Shell执行
DESCRIBE 'table_name',查看ENCODE列是否显示压缩算法 - 通过HDFS命令检查HFile文件后缀:
.gz表示GZIP,.lz4表示LZ4编码 - 在HBase UI的Region详情页查看”Compression”配置项
Q2:压缩是否会影响HBase的事务性保证?
A2:不会,HBase的WAL(Write Ahead Log)机制确保数据持久化不受压缩影响,即使压缩过程失败,已写入WAL的原始数据仍可恢复,但需注意:极端情况下(如磁盘满),未压缩的数据可能更快触发故障
相关文章

音视频处理中的数据压缩(音视频数据压缩编码的国际标准mpeg-2与什么保持兼容)
如何实现MapReduce作业中从HBase读取数据后再将结果高效地写回HBase?

云数据库HBase版,HBase协议兼容实例如何实现?
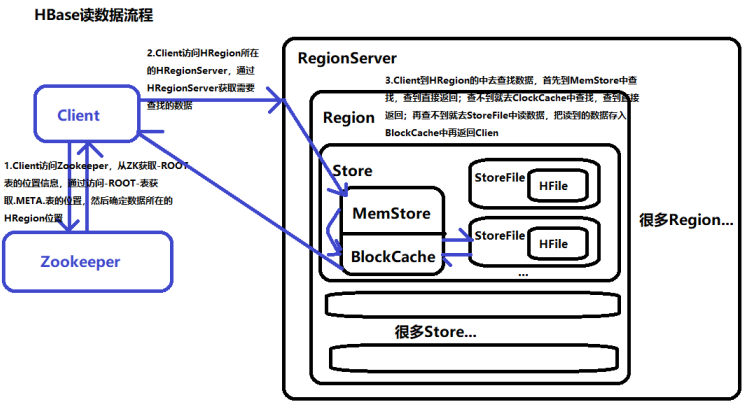
如何通过MapReduce从HBase读取数据并重新写入HBase?

如何为ELB Ingress配置gzip数据压缩以启用虚拟主机的gzip压缩?

Gzip 网站 能够压缩图片吗_为ELB Ingress配置gzip数据压缩

SEO行业是否正面临前所未有的焦虑与挑战?,你如何看待当前SEO行业的焦虑现状?,你是否也对SEO行业的现状感到焦虑?,SEO行业的现状是否引发了你的担忧和思考?,你对SEO行业的未来有何看法?,你是否认为SEO行业正在经历一场变革?,你对SEO行业的发展趋势有何预测?,你是否觉得SEO行业的竞争压力越来越大?,你是否认为SEO行业需要更多的创新和改革?,10. 你对SEO行业的未来发展有何期待?

OceanBase数据库咨询下创建 OBProxy 集群无法对接OceanBase 集群什么原因?







