上一篇
分布式海量数据存储文档介绍内容
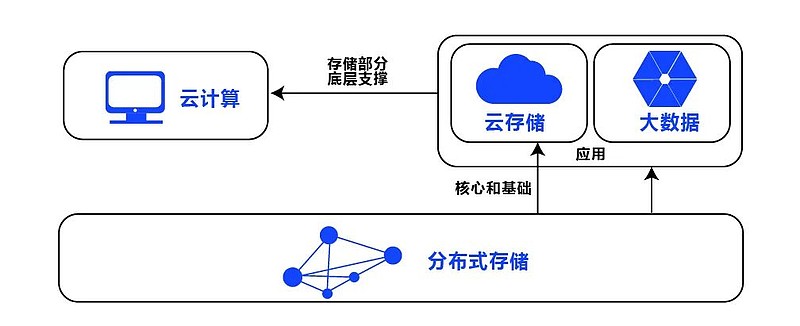
分布式海量存储架构,分片副本保障高可用,弹性扩展兼容多场景,优化一致性
分布式海量数据存储技术详解
核心概念与应用场景
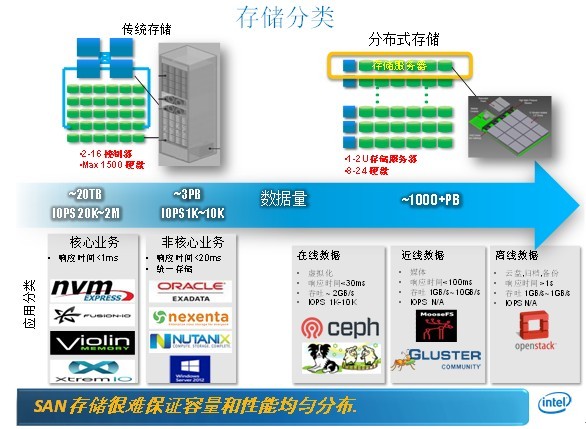
分布式海量数据存储是一种通过多台服务器协同工作,将数据分散存储在多个节点上的技术架构,其核心目标是解决传统集中式存储在容量、性能和可靠性方面的瓶颈,适用于以下场景:
- 互联网企业:用户行为日志、图片/视频等非结构化数据存储(如抖音每日新增PB级数据)
- 云计算服务:AWS S3、阿里云OSS等对象存储服务
- 大数据分析:Hadoop HDFS支撑的离线计算集群
- 物联网领域:百万级设备传感器数据实时采集
典型特征包括:水平扩展能力、高容错性、跨地域数据访问、EB级存储支持,据IDC预测,全球数据总量将在2025年突破175ZB,分布式存储成为唯一可行的技术路径。
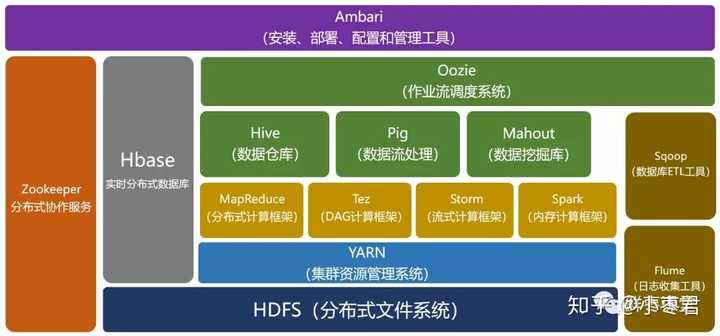
系统架构设计
| 架构类型 | 代表系统 | 数据流向 | 适用场景 |
|---|---|---|---|
| 主从架构 | Ceph/GlusterFS | 客户端→主节点→从节点 | 读写分离场景,需保证主节点高可用 |
| 对等架构 | Cassandra/DynamoDB | 客户端→任意节点 | 无单点瓶颈,适合高并发写入 |
| 混合架构 | TiDB/Greenplum | 计算层+存储层分离 | OLAP分析型数据库首选 |
关键组件解析:
- 客户端SDK:提供数据分片、路由、负载均衡功能
- 元数据服务:记录数据位置映射(如HDFS NameNode)
- 存储节点:实际数据存储载体,包含本地SSD+HDD混合存储
- 协调服务:ZooKeeper实现分布式锁和配置管理
核心技术实现
数据分片策略
| 分片方式 | 实现原理 | 优缺点 | 适用场景 |
|---|---|---|---|
| 哈希分片 | 按Key哈希取模 | 均匀分布,热点问题 | 对象存储(如S3) |
| 范围分片 | 按时间/ID区间划分 | 顺序访问高效 | 日志流式处理 |
| 目录分片 | 按路径前缀划分 | 兼容POSIX语义 | 分布式文件系统 |
典型案例:Elasticsearch采用虚拟分片技术,通过Pawley-Bateman算法实现动态扩缩容时的数据均衡。
副本机制
- 强一致性副本:Raft协议(etcd/Consul),写入需多数节点确认
- 最终一致性副本:DNSAnycast技术,优先本地写入
- 纠删码技术:Reed-Solomon编码,n+m节点容忍m个故障
性能对比:同步复制延迟约50ms,异步复制吞吐量提升3-5倍但存在数据丢失风险。
元数据管理
- 单点式:HDFS NameNode内存存储元数据,支持10^6级别目录
- 分布式:Ceph CRUSH算法实现去中心化寻址
- 新型方案:Apache Kudu采用多级分区索引,支持毫秒级OLAP查询
核心挑战与解决方案
CAP定理的工程实践
| 场景需求 | 典型选择 | 技术实现 |
|---|---|---|
| 跨区金融交易 | CP优先(牺牲可用性) | 2PC+Paxos协议 |
| 社交媒体Feed | AP优先(允许短暂不一致) | DynamoDB版本向量 |
| 电商订单系统 | 分区容忍+最终一致 | 基于时间戳的冲突解决 |
酷盾安全COS实践:通过多地域AZ部署,结合Quroa协议实现分钟级跨区域数据同步。
数据倾斜治理
- 动态分片调整:Spark RDD基于统计信息重新分区
- 热度感知存储:阿里云OSS的冷热分层存储,将高频访问数据自动迁移至SSD
- 一致性哈希优化:引入虚拟节点技术,Redis Cluster扩容时数据迁移量降低70%
成本优化策略
| 技术手段 | 降本效果 | 适用场景 |
|---|---|---|
| 纠删码存储 | 降低30%存储成本 | 温冷数据归档 |
| 压缩编码 | 节省50%带宽 | 视频监控存储 |
| 生命周期管理 | 减少60%冗余存储 | 日志合规存储 |
字节跳动实践:通过自研JUC存储引擎,将TikTok全球数据中心存储成本降低42%。
主流技术对比
| 维度 | Hadoop HDFS | Ceph | Amazon S3 | TiDB |
|---|---|---|---|---|
| 数据模型 | 文件系统 | 对象/块存储 | 对象存储 | NewSQL |
| 扩展方式 | 横向扩展 | 横向+纵向 | 全托管服务 | 计算存储分离 |
| 一致性保证 | 强一致性 | 可调一致性 | 最终一致性 | ACID事务 |
| 典型延迟 | 100ms+ | 50ms | <10ms | <30ms |
| 最佳应用场景 | 批处理计算 | 统一存储 | 静态资源托管 | 实时分析 |
未来发展趋势
- 存算一体化:NVMe over Fabrics实现近数据处理
- Serverless存储:按需计费模式,如AWS S3 Select
- AI增强存储:Google AutoML预测数据访问模式
- 量子存储探索:IBM Q System One实现量子纠错编码
FAQs
Q1:如何选择分布式存储系统?
A:需评估三个维度:①数据类型(结构化/非结构化)、②访问模式(OLTP/OLAP)、③业务SLA要求,例如电商订单系统应选强一致性存储,而用户画像分析可选择最终一致性存储,建议通过TPC-C/TPC-H基准测试验证性能。
Q2:如何处理数据一致性与性能的矛盾?
A:可采用分级策略:①核心业务采用Paxos协议保证强一致;②非关键数据使用Quorum NWR策略(如N=3,W=2,R=2);③日志类数据接受最终一致性,同时结合CDC(Change Data Capture)技术