上一篇
分布式海量数据仓库
分布式海量数据仓库基于 分布式架构,采用存储计算分离设计,支持EB级数据弹性扩展,通过数据分片与副本机制保障可靠性,具备高并发处理能力,支撑实时分析与决策需求
分布式海量数据仓库:核心概念与技术解析
定义与核心特征
分布式海量数据仓库是一种面向大规模数据存储、管理和分析的系统架构,其核心目标是通过分布式计算和存储技术,实现对PB级甚至EB级数据的高效处理,与传统数据仓库相比,它具备以下特征:
| 特性 | 传统数据仓库 | 分布式海量数据仓库 |
|---|---|---|
| 数据规模 | TB级(集中式) | PB/EB级(分布式) |
| 存储架构 | 单一节点/纵向扩展 | 多节点横向扩展 |
| 计算模式 | 单机串行处理 | 分布式并行计算 |
| 容错性 | 依赖硬件可靠性 | 数据冗余与自动恢复 |
| 成本模型 | 高昂(专用硬件) | 弹性(通用服务器集群) |
架构设计核心组件
分布式存储层
- 数据分片(Sharding):将数据按哈希、范围或自定义规则拆分为多个分片,分散存储在不同节点。
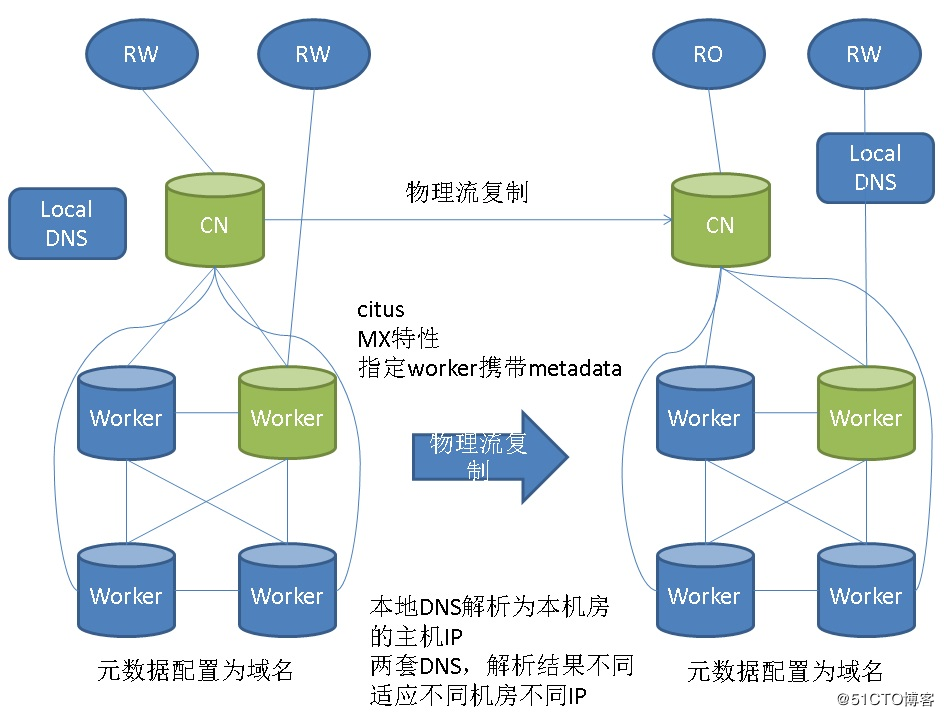
- 副本机制:通过RAID-like或Paxos协议实现数据冗余(如HDFS的3副本策略)。
- 典型技术:HDFS、Ceph、MinIO(对象存储),HBase(NoSQL)、Iceberg(湖仓一体)。
计算引擎层
- 批处理框架:MapReduce(Hadoop)、Spark(内存迭代)、Flink(流批一体)。
- OLAP引擎:Impala(低延迟查询)、Presto(多源数据联邦查询)、ClickHouse(列式存储)。
- 混合计算:支持SQL、图计算(如Pregel)、机器学习(如TensorFlow on Spark)。
元数据管理
- 统一目录:Hive Metastore、Apache Atlas(血缘追踪)。
- 索引优化:倒排索引(全文检索)、Bloom Filter(快速去重)。
调度与协调

- 资源管理:YARN(Hadoop)、Kubernetes(容器化调度)。
- 任务调度:Volcano(Spark)、Tez(DAG优化)。
关键技术挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 数据倾斜 | 哈希分桶、Range分区优化、动态负载均衡(如Spark的自适应执行) |
| 节点故障 | 心跳检测、自动Failover、副本重建(如HDFS的Block Recovery) |
| 查询延迟 | 向量化执行(Vectorization)、内存计算(Spark Tungsten)、索引下推(Greenplum) |
| 多源数据融合 | 数据湖架构(Iceberg/Hudi)、联邦查询(Presto Connector) |
| 成本控制 | 存算分离(如AWS S3+Athena)、冷热数据分层(生命周期策略) |
典型应用场景
互联网大数据分析
用户行为日志分析(如电商点击流)、实时推荐系统(Flink+Kafka)、A/B测试结果聚合。
金融风控与审计
反欺诈规则引擎(Hive+Spark)、交易流水追溯(时序数据库+数据仓库联动)。
物联网与边缘计算
设备日志聚合(EdgeX Foundry)、时序数据压缩存储(TimescaleDB)。
政务与公共安全
人口普查数据治理(DataVault模型)、交通流量预测(时空数据库+机器学习)。
主流技术栈对比
| 组件类别 | 开源方案 | 商业化方案 |
|---|---|---|
| 存储引擎 | HDFS、Ceph、Iceberg | Amazon S3、Google BigQuery、Azure Data Lake |
| 计算引擎 | Spark、Flink、Presto | Snowflake、Redshift、Google Spanner |
| 协调服务 | ZooKeeper、etcd | Consul、AWS ECS |
| 元数据管理 | Apache Atlas | IBM InfoSphere、Collibra |
未来演进趋势
- 存算分离架构普及:计算节点与存储解耦(如Snowflake架构),提升资源利用率。
- AI驱动优化:自动调优查询计划(如Google SQL AutoML)、智能数据分片。
- 多模数据处理:支持结构化、半结构化、非结构化数据的统一分析(Data Lakehouse)。
- 云原生部署:基于Kubernetes的弹性扩缩容(如Apache Flink on K8s)。
FAQs
Q1:分布式海量数据仓库与传统数据库的核心区别是什么?
A:传统数据库(如Oracle、MySQL)通常为集中式架构,适合事务型处理(OLTP),强调ACID特性;而分布式数据仓库专为分析型场景(OLAP)设计,采用横向扩展、最终一致性模型,支持PB级数据吞吐量和高并发查询。
Q2:如何保证分布式数据仓库中的数据一致性?
A:通过CAP定理权衡,通常采用以下策略:
- 强一致性:使用分布式事务协议(如2PC)或Paxos算法(如Spanner)。
- 最终一致性:允许短暂延迟同步(如HBase的WAL+Bulk Loading)。
- 时间戳标记:为数据打上版本号或LRU时间戳,冲突时