上一篇
分布式消息传递怎么用
分布式消息传递通过消息队列实现服务解耦与异步通信,用于削峰填谷、数据缓冲,常见于Kafka、RabbitMQ等中间件,支持跨系统可靠
分布式消息传递的核心原理与实践指南
分布式消息传递的核心概念
分布式消息传递是一种通过中间件实现跨进程、跨节点通信的机制,其核心目标是解决分布式系统中的服务解耦、数据异步处理、流量削峰等问题,与传统RPC(远程过程调用)相比,消息传递具有异步、松散耦合、高容错等特点。
关键特性:

- 异步性:发送方无需等待接收方处理完成即可继续执行。
- 解耦:生产者与消费者通过消息队列间接交互,降低依赖。
- 可靠性:通过持久化、重试机制保证消息不丢失。
- 可扩展性:支持多生产者、多消费者横向扩展。
核心组件与角色
| 组件 | 功能描述 |
|---|---|
| 生产者 | 负责生成消息并发送到消息队列(如订单服务生成“订单创建”消息)。 |
| 消费者 | 订阅消息队列并处理消息(如库存服务消费“订单创建”消息以扣减库存)。 |
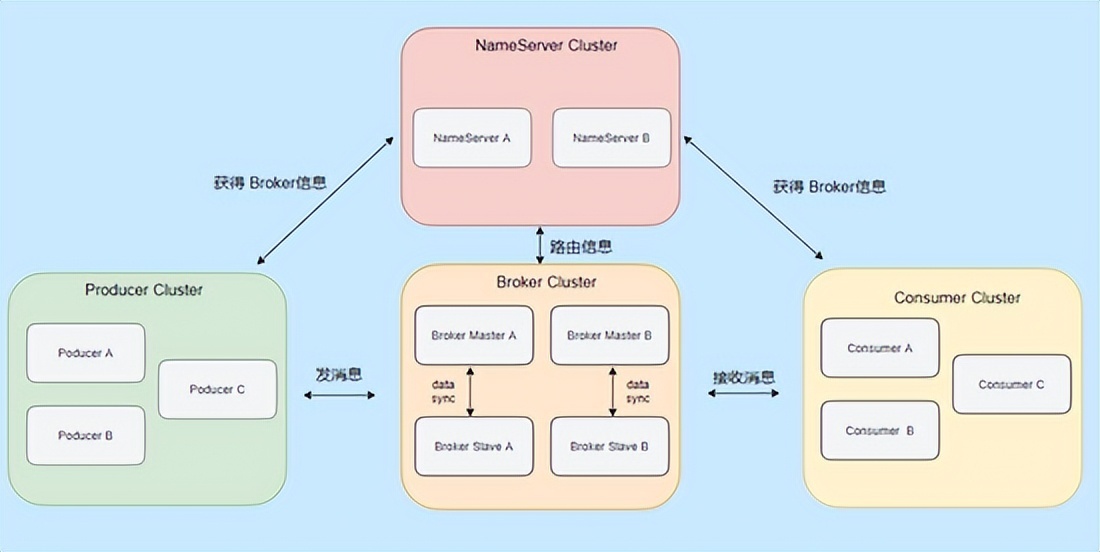
| 消息队列 | 中间存储组件,支持消息的暂存、路由和持久化(如Kafka、RabbitMQ)。 |
| Broker | 消息队列的管理节点,负责消息的路由、存储和分发(如Kafka的集群控制器)。 |
工作流程示例:
- 生产者发送消息到Broker;
- Broker将消息存入队列;
- 消费者从队列拉取消息并处理;
- 处理结果反馈给Broker(如确认或重试)。
消息传递模式对比
| 模式 | 特点 | 适用场景 |
|---|---|---|
| 点对点模式 | 单消费者处理消息,消息被消费后即删除 | 任务分配(如分布式锁) |
| 发布订阅模式 | 多消费者订阅同一主题,消息广播给所有订阅者 | 事件通知(如系统监控告警) |
关键技术实现
- 消息序列化:使用Protobuf、JSON等格式将对象转换为字节流。
- 消息确认机制:消费者处理完成后发送ACK,Broker收到后才删除消息。
- 持久化策略:
- 磁盘存储:保证重启后消息不丢失(如Kafka的日志文件)。
- 内存存储:高性能但风险高(如Redis的临时队列)。
- 消息排序:通过分区(Kafka)或消息键(RabbitMQ)保证顺序性。
典型应用场景
| 场景 | 解决方案 |
|---|---|
| 服务解耦 | 订单服务 → 消息队列 → 库存/支付服务 |
| 流量削峰 | 突发请求写入消息队列,后台按速率处理(如瞬秒活动) |
| 日志收集 | 各服务写入日志到消息队列,集中存储至Elasticsearch |
| CQRS模式 | 命令写消息队列,查询通过同步数据库读取 |
案例分析:电商订单处理流程
- 用户下单:前端将订单数据发送到订单服务。
- 消息生产:订单服务生成“OrderCreated”消息到Kafka的“order-topic”。
- 异步处理:
- 库存服务消费消息,扣减商品库存;
- 支付服务检查支付状态,触发支付回调;
- 物流服务生成发货单。
- 最终一致性:各服务通过事务消息或补偿机制处理失败场景。
实践建议与优化
- 选型策略:
- 高吞吐量:Kafka(日志、大数据场景)
- 复杂路由:RabbitMQ(支持交换机、绑定键)
- 低延迟:Redis Stream(实时性要求高)
- 消息幂等性:消费者需设计去重逻辑(如基于唯一ID)。
- 死信队列:处理无法消费的消息,避免阻塞主队列。
- 监控指标:
- 队列长度:反映处理压力;
- 消费延迟:评估系统性能;
- 消息堆积量:预警故障。
常见问题与解决方案
FAQs:
Q1:如何防止消息丢失?
A1:
- 开启可靠投递(如Kafka的ACKS=all);
- 使用持久化队列(消息存储到磁盘);
- 生产者发送后等待Broker确认;
- 消费者处理完手动提交偏移量。
Q2:如何保证消息顺序性?
A2:
- 使用有序队列(如RabbitMQ的
prefetch=1); - Kafka通过消息键哈希到同一分区;
- 业务层添加序列号校验。
分布式消息传递是构建高可用、可扩展系统的关键技术,其核心价值在于通过异步和解耦提升系统韧性,实际应用中需结合业务场景选择合适方案,并通过幂等、