上一篇
分布式消息中间件怎么用
分布式消息中间件通过API接口实现异步通信,生产者发送消息至队列,消费者订阅处理,支持削峰、解耦及持久化,常用Kaf
分布式消息中间件核心功能与使用指南
分布式消息中间件的核心功能
分布式消息中间件通过解耦生产者与消费者、平衡系统负载、保障数据可靠性,成为现代分布式系统的基础设施,其核心功能可归纳为以下表格:
| 功能分类 | 典型能力 |
|---|---|
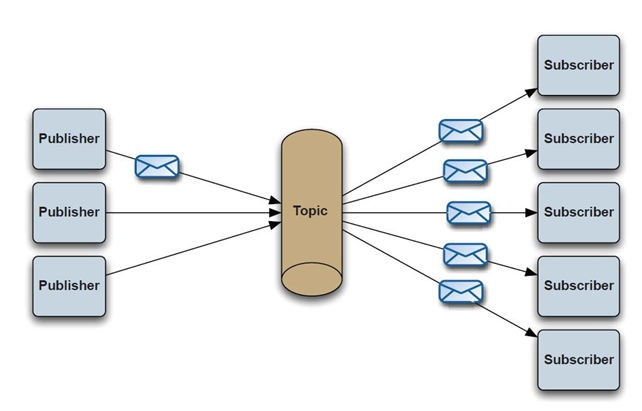
| 消息传递 | 支持点对点(P2P)、发布订阅(Pub/Sub)模式 消息路由与过滤(基于Topic/Tag) |
| 可靠性保障 | 消息持久化(磁盘/内存) ACK确认机制 重试与死信队列(DLQ)处理 |
| 性能优化 | 顺序消费保障 流量整形(限流) 批量处理与压缩 |
| 扩展性 | 水平扩展(Broker集群) 分区机制(Partition) 动态扩容无停机 |
| 监控管理 | 消息堆积监控 消费延迟报警 Broker健康状态检测 |
典型应用场景与选型建议
| 场景类型 | 业务特征 | 推荐中间件 | 关键设计点 |
|---|---|---|---|
| 异步任务处理 | 订单处理、文件转码等非实时任务 | RabbitMQ/Kafka | 低延迟、高吞吐量、失败重试机制 |
| 日志采集 | 分布式系统日志聚合分析 | Kafka | 高写入吞吐、分区顺序性保障 |
| 微服务通信 | RPC替代方案、事件驱动架构 | RocketMQ/Kafka | 事务消息、消息轨迹跟踪 |
| 物联网数据流转 | 设备传感器数据采集与存储 | Kafka/EMQX | 海量连接支持、持久化策略 |
| 金融级交易 | 支付回调、证券交易指令传输 | RocketMQ/Kafka | 严格消息顺序性、消息投递确认机制 |
基础使用流程与操作规范
环境搭建与部署
- 单机模式:适用于开发测试环境,直接启动单节点Broker
- 集群模式:生产环境需部署多Broker集群,典型架构:
[Producer] ---> LoadBalancer ---> Broker1/Broker2... ---> [Consumer] ^ |-ZooKeeper(Kafka协调元数据) - 容器化部署:推荐使用Docker Compose或Kubernetes管理集群
API接口调用示例
以Java客户端发送消息为例(Apache Kafka):// 初始化生产者 Properties props = new Properties(); props.put("bootstrap.servers", "broker1:9092,broker2:9092"); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new KafkaProducer<>(props); // 发送消息 ProducerRecord<String, String> record = new ProducerRecord<>("topic_name", "key1", "value1"); producer.send(record, (metadata, exception) -> { if (exception != null) { System.err.println("Send failed: " + exception.getMessage()); } else { System.out.println("Offset: " + metadata.offset()); } }); producer.close();消息设计规范
| 设计维度 | 最佳实践 |
|—————-|————————————————————————–|
| 消息体结构 | JSON/Avro格式
包含唯一ID、时间戳、业务标识符 |
| 分区策略 | 按业务Key哈希分区(保证相同Key顺序消费)
或按时间范围分区 |
| 序列化方式 | 优先选择二进制序列化(如Protobuf)
避免文本格式膨胀 |
| 消息大小 | 单条消息<=1MB(Kafka默认限制)
超大消息建议拆分为多个消息+组装层 |可靠性保障机制
- 同步刷盘:
acks=all配置确保数据写入磁盘 - 消息确认:消费者显式调用
commitSync()提交偏移量 - 幂等性:生产者开启
enable.idempotence=true防止重复投递 - 死信处理:设置
dlq.enable=true并配置最大重试次数
- 同步刷盘:
主流产品特性对比
| 产品 | 核心优势 | 适用场景 | 学习成本 |
|---|---|---|---|
| Kafka | 高吞吐量(百万级TPS) 水平扩展能力强 | 日志收集、大数据实时计算 | 中高 |
| RabbitMQ | 丰富路由规则 协议支持广泛(AMQP) | RPC调用、复杂路由场景 | 中 |
| RocketMQ | 金融级可靠性 阿里系生态支持 | 电商订单、金融交易 | 高 |
| Redisson | 轻量级 基于Redis的PubSub实现 | 小规模实时通知 | 低 |
监控与运维要点
关键监控指标
- Broker层面:CPU使用率、内存占用、磁盘IO、网络带宽
- 消息层面:积压数量、消费延迟、失败率、流量带宽
- 典型告警阈值:消息堆积>10万条(持续5分钟)、消费延迟>1分钟
日常运维操作
- 扩容操作:增加Broker节点后,需重新分配分区并迁移数据
- 故障转移:启用多活架构,配置自动主备切换策略
- 数据清理:设置日志保留策略(如Kafka的
log.retention.hours)
高级特性与优化技巧
顺序性保障方案
- 消息头添加序列号字段
- 使用RocketMQ的顺序消息特性(
ORDER_MESSAGE) - Kafka通过单分区+Key粘性分配实现顺序消费
流量控制策略
- 限流算法:令牌桶(如Kafka的
max.in.flight.requests.per.connection) - 背压机制:消费者主动反馈处理能力(如暂停拉取)
- 熔断降级:设置消息队列长度阈值触发熔断
- 限流算法:令牌桶(如Kafka的
多数据中心部署
- 跨AZ部署:采用同城双活+异地灾备架构
- 数据同步:使用增量复制(如Kafka的跨集群复制工具MirrorMaker)
- 延迟优化:部署边缘节点减少网络传输耗时
FAQs
Q1:如何保证消息不丢失也不重复消费?
A1:需组合多种策略:
- 生产者侧开启可靠投递(
acks=all+同步刷盘) - 消费者侧实现幂等处理(基于业务ID去重)
- 使用事务消息(如RocketMQ的半事务消息)
- 配置合理的重试策略(指数退避算法)
Q2:消息堆积过多时如何处理?
A2:分阶段处理方案:
- 紧急止血:临时扩容消费者实例,提升消费速率
- 根因分析:检查消费者逻辑瓶颈/突发流量来源
- 长期优化:
- 实施流量削峰(限流或延迟处理)
- 优化消息处理逻辑(并行消费/批量处理)
- 调整消息队列数量(增加Topic Partition)