上一篇
hadoop网络架构
Hadoop采用主从式网络架构,NameNode管理元数据,DataNode存储数据块,节点间通过TCP/IP通信,支持数据冗余与负载均衡,保障分布式
Hadoop网络架构深度解析
Hadoop作为分布式计算框架的核心,其网络架构设计直接影响集群的性能、可靠性和扩展性,本文将从HDFS、YARN、客户端交互、高可用性配置及优化策略五个维度,详细分析Hadoop网络架构的关键技术与实现原理。
HDFS网络架构
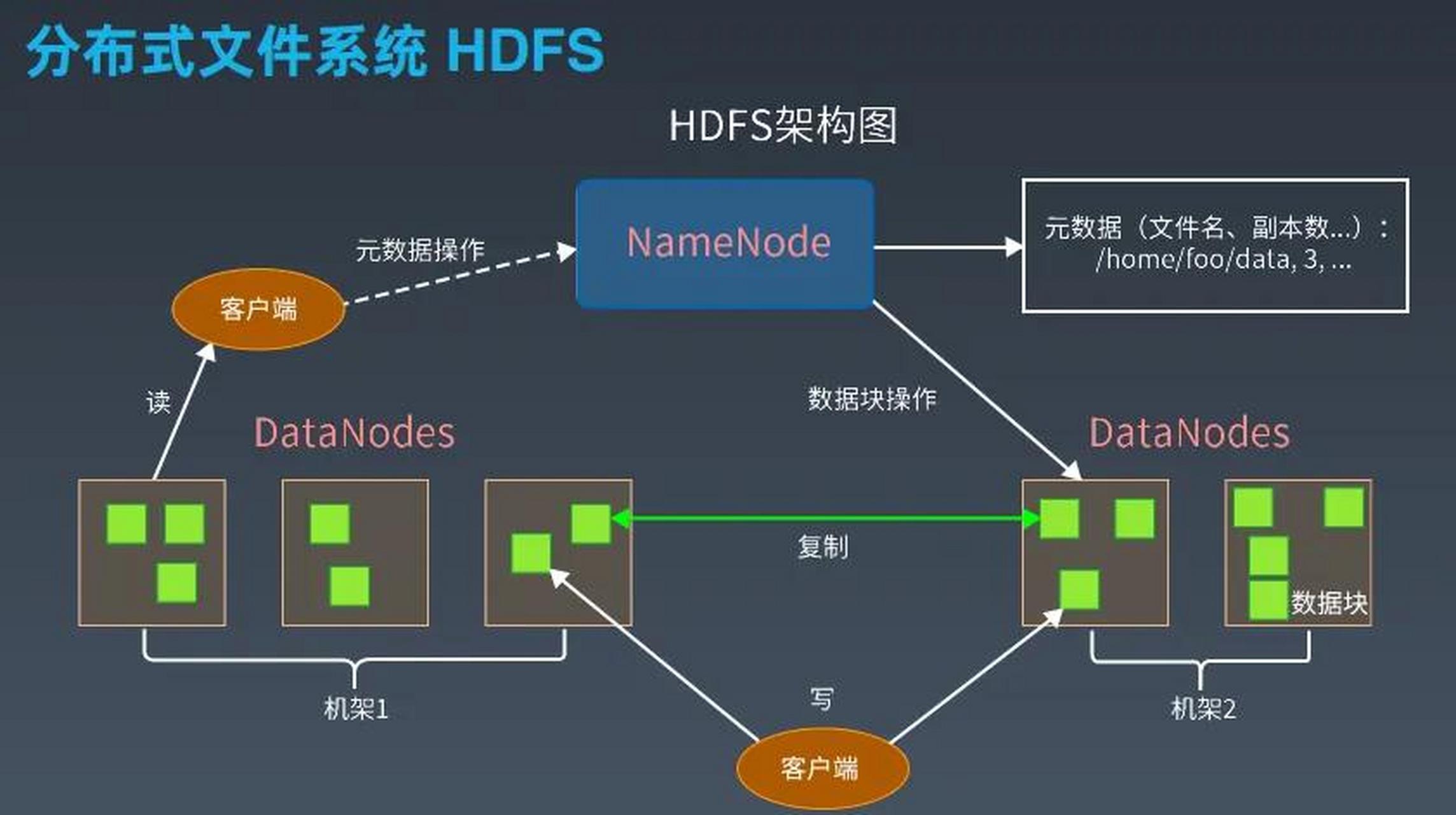
HDFS(Hadoop Distributed File System)是Hadoop的存储核心,其网络架构围绕NameNode与DataNode的协同展开。
| 组件 | 功能 | 通信协议 | 典型端口 |
|---|---|---|---|
| NameNode | 管理元数据(文件路径、块位置、权限),协调DataNode心跳与块报告 | RPC(基于TCP) | 8020 |
| DataNode | 存储实际数据块,定期向NameNode发送心跳和块报告,处理客户端读写请求 | RPC(基于TCP) | 8020 |
| Client | 发起文件操作请求,与NameNode交互获取元数据,直接与DataNode传输数据 | HTTP/RPC | 8020/50070 |
| SecondaryNameNode | 辅助NameNode合并日志与元数据(Hadoop 2.x及以前版本) | HTTP/RPC | 50090 |
关键流程:

- 客户端写入数据:Client向NameNode请求上传文件,NameNode返回可用DataNode列表。
- 数据分块传输:Client将数据分块后并行推送至多个DataNode,采用流水线(Pipeline)方式逐跳传输。
- 心跳机制:DataNode每3秒向NameNode发送心跳,包含块完整性信息;NameNode通过心跳维持集群状态。
- 块报告:DataNode定期(每小时)向NameNode发送块列表,确保元数据与实际存储一致。
高可用架构:
- Active/Standby模式:通过ZooKeeper协调主备NameNode状态,共享EditLog实现元数据同步。
- JournalNode集群:在HA模式下,主备NameNode通过一组JournalNode(通常3个奇数节点)实现日志同步,避免单点故障。
YARN网络架构
YARN(Yet Another Resource Negotiator)负责资源管理和任务调度,其网络架构以ResourceManager和NodeManager为核心。
| 组件 | 功能 | 通信协议 | 典型端口 |
|---|---|---|---|
| ResourceManager | 全局资源调度,接收ApplicationMaster请求,分配Container资源 | HTTP/RPC | 8030/8031 |
| NodeManager | 管理单个节点资源(CPU、内存),启动/监控Container,汇报资源使用情况 | HTTP/RPC | 8040/8041 |
| ApplicationMaster | 任务调度核心,向RM申请资源,协调任务执行(如MapReduce中的AppMaster) | HTTP/RPC | 动态分配 |
| TimelineServer | 存储应用历史记录(Hadoop 2.x+) | HTTP | 8480 |
关键流程:
- 资源分配:ApplicationMaster向ResourceManager提交资源请求,RM通过调度算法(如CapacityScheduler)分配Container。
- Container启动:RM指令NodeManager在本地启动Container,NM通过RPC报告状态。
- Shuffle阶段:Map任务完成后,Reduce端通过HTTP从多个Map节点拉取数据,网络带宽成为瓶颈。
- 心跳与健康检查:NodeManager每5秒向RM发送心跳,汇报资源使用率与Container状态。
客户端与集群交互
客户端(Client)通过网络与Hadoop集群交互,需注意以下设计:
- 元数据缓存:Client缓存NameNode的元数据(如文件块位置),减少重复RPC调用。
- 数据本地性优化:Client优先选择离自身近的DataNode存储数据,降低跨机架延迟。
- 安全通信:通过Kerberos认证和HTTPS加密(需配置
hadoop.security.authentication),防止数据泄露。
高可用性网络设计
Hadoop 3.x通过以下机制增强网络容错能力:
| 场景 | 解决方案 |
|————————-|——————————————————————————|
| NameNode单点故障 | 启用HA模式(QJM或JR),通过JournalNode集群同步元数据日志 |
| 网络分区导致脑裂 | 依赖ZooKeeper选举主NameNode,超时阈值可配置(dfs.ha.fencing.methods) |
| 跨数据中心部署 | 使用DNS轮询或Anycast实现多活集群,结合联邦存储(Federation)分散元数据压力 |
网络性能优化策略
| 优化方向 | 具体措施 |
|---|---|
| 带宽利用率 | 启用数据压缩(io.compression.codec)、调整块大小(dfs.blocksize) |
| 延迟敏感任务 | Shuffle阶段使用本地磁盘缓存(mapreduce.reduce.shuffle.merge.percent) |
| 负载均衡 | 配置机架感知(topology.script.number.of.networks),避免跨机架数据传输 |
| 监控与诊断 | 集成Prometheus/Grafana监控网络流量,分析慢日志(yarn.log-aggregation) |
FAQs
Q1:Hadoop集群中出现“Safemode”无法退出,可能与网络有关吗?
A1:是的,Safemode是NameNode的一种保护状态,当DataNode心跳丢失比例超过阈值(dfs.namenode.safemode.threshold)时触发,常见原因包括:
- DataNode网络中断导致心跳丢失
- NameNode与DataNode之间的防火墙阻断RPC端口(默认8020)
- JournalNode同步延迟(HA模式下)
解决方法:检查集群网络连通性,查看NameNode日志中的BlockReport异常信息。
Q2:如何优化MapReduce任务的Shuffle阶段网络开销?
A2:Shuffle阶段需从多个Map节点拉取数据,优化策略包括:
- 压缩数据传输:启用
mapreduce.task.io.sort.mb和mapreduce.map.output.compress参数。 - 合并Fetch请求:调整
mapreduce.reduce.shuffle.parallelcopies参数,并行拉取数据。 - 本地化Shuffle:将Reduce任务分配到Map节点所在机架,减少跨机架流量。
- 升级硬件:使用RDMA(远程直接内存访问)或100