上一篇
GPU存储架构如何优化能带来更高计算性能
GPU存储架构采用多层次设计,包含全局内存、共享内存、寄存器及缓存体系,共享内存提供线程块内低延迟通信,全局内存容量大但延迟较高,寄存器实现线程独享高速存取,通过分层数据调度和宽总线高带宽设计,优化并行计算的数据吞吐效率,支持大规模线程并发执行。
GPU存储架构解析:从底层设计到应用实践
在人工智能、高性能计算和图形渲染等领域,GPU(图形处理器)的性能表现至关重要,而决定GPU性能的核心因素之一,是其存储架构的设计,本文将深入剖析GPU存储架构的组成、关键技术及其对计算效率的影响,帮助读者全面理解其工作原理。
GPU存储架构的核心层级
GPU的存储架构是一个多层级的系统,不同层级的存储介质在容量、速度和访问权限上存在显著差异,以满足计算任务对数据的高效调度需求。
寄存器(Register)
- 作用:寄存器的速度最快,直接与计算单元(CUDA Core/流处理器)相连,用于暂存当前线程的临时数据。
- 特点:容量极小(通常每个线程分配几十到上百个寄存器),但访问延迟几乎为零。
- 优化点:合理分配寄存器资源可减少全局内存访问次数,提升并行效率。
共享内存(Shared Memory)

- 作用:同一线程块(Block)内的线程共享此内存,用于缓存高频访问数据。
- 特点:容量有限(通常为几十KB),但带宽高,适合线程间通信或数据复用。
- 典型案例:矩阵乘法运算中,将子矩阵加载到共享内存以减少全局内存访问。
全局内存(Global Memory)
- 作用:GPU的主内存,所有线程均可访问,用于存储大规模数据(如输入图像、模型参数)。
- 特点:容量大(现代GPU可达24GB~80GB),但延迟较高(数百时钟周期)。
- 优化方向:通过“合并访问”(Coalesced Access)提高带宽利用率。
常量内存(Constant Memory)与纹理内存(Texture Memory)
- 常量内存:存储只读数据(如卷积核参数),具备高速缓存机制。
- 纹理内存:针对图形渲染设计,支持硬件级插值和缓存优化,适合非结构化数据访问。
GPU存储架构的关键技术
高带宽显存技术
GDDR与HBM的对比
- GDDR6:主流显存类型,通过高频率(14~20Gbps)和宽总线(256~384位)实现高带宽(448~768GB/s)。
- HBM(高带宽内存):采用3D堆叠和硅通孔(TSV)技术,显著提升带宽(1TB/s以上),但成本较高,多用于数据中心GPU(如NVIDIA A100)。
带宽与计算性能的关系
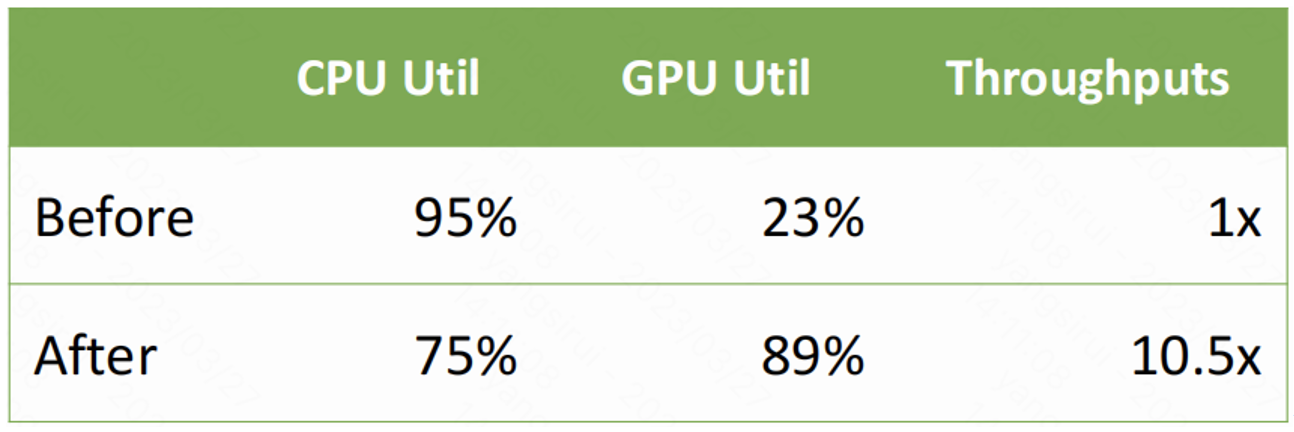
带宽是衡量GPU“喂数据”能力的关键指标,训练大型神经网络时,显存带宽不足会导致计算单元闲置,形成性能瓶颈。
缓存系统的优化
现代GPU(如NVIDIA Ampere架构)引入多级缓存(L1/L2),通过以下方式提升效率:
- 缓存一致性协议:减少多核间数据同步的开销。
- 数据预取(Prefetching):预测未来需要的数据并提前加载至缓存。
显存虚拟化技术
- Unified Memory(统一内存):允许CPU和GPU共享同一内存空间,简化编程模型(如CUDA的
cudaMallocManaged)。 - Page Migration(页迁移):根据访问频率动态迁移数据位置,降低延迟。
存储架构对应用场景的影响
AI训练与推理
- 挑战:大模型参数占用显存容量(如GPT-3需数百GB),需通过模型并行或显存压缩技术(如FP16/INT8量化)解决。
- 解决方案:NVIDIA的显存扩展技术(NVLink)支持多GPU互联,提升总显存容量。
实时图形渲染
- 需求:高分辨率纹理和复杂着色器需快速访问显存。
- 技术应用:纹理内存的硬件插值功能可加速像素着色计算。
科学计算
- 典型案例:流体动力学仿真中,显存带宽决定每秒可处理的网格节点数量。
未来发展趋势
- 3D堆叠显存普及:HBM3和HBM4将进一步突破带宽限制,支持更复杂的计算任务。
- 近存计算(Near-Memory Computing):将计算单元嵌入显存内部,减少数据搬运能耗(如AMD的CDNA架构)。
- 异构内存系统:结合DRAM、NVM(非易失内存)和分布式存储,实现容量与速度的平衡。
引用说明 参考以下权威资料:
- NVIDIA官方技术白皮书《NVIDIA Ampere Architecture In-Depth》
- AMD研究论文《High Bandwidth Memory: Scaling Deep Learning Performance》
- 计算机体系结构会议ISCA 2022议题《3D-Stacked Memory Challenges and Opportunities》
通过理解GPU存储架构的设计逻辑,开发者可以更高效地优化代码,硬件工程师则能把握未来技术方向,无论是游戏、AI还是科学研究,存储架构的进步将持续推动计算性能的边界。