
上一篇
分布式文件存储格式
分布式文件存储格式通过分块、冗余和元数据管理实现数据分布式存储,常见如HDFS采用块存储与副本机制,Ceph利用CRUSH算法优化分布,具备高可用、可扩展及容错特性,适用于大规模数据
分布式文件存储格式详解
分布式文件存储的核心概念
分布式文件存储系统通过将数据分散存储在多个节点上,实现数据的冗余备份、高可用性和横向扩展能力,其核心目标包括:
- 数据分片与分布:将文件拆分为多个块(Block)或对象(Object),分布到不同节点
- 元数据管理:记录文件位置、权限、块信息等元数据
- 容错机制:通过副本或纠删码实现数据冗余
- 负载均衡:动态调整数据分布以优化资源利用
主流分布式文件存储格式对比
| 特性 | HDFS (Hadoop) | Ceph RADOS GW | GlusterFS | Swift (OpenStack) |
|---|---|---|---|---|
| 存储模型 | 块存储(Block) | 对象存储(Object) | POSIX文件系统 | 对象存储(Object) |
| 元数据管理 | 中央NameNode | 分布式CRUSH算法 | 弹性哈希分布 | 账户/容器层级 |
| 数据分片 | 固定128MB块 | 可变大小对象 | 动态分块 | 可变大小对象 |
| 冗余策略 | 3副本默认 | EC/副本可选 | 可调副本数 | 副本数可配置 |
| 扩展性 | 水平扩展(需Rebalance) | 自动CRUSH平衡 | 自动哈希重分布 | 一致性哈希环 |
| API兼容性 | HDFS自有协议 | S3/Swift API | NFS/SMB/FTP | S3/Swift API |
| 典型应用场景 | 大数据分析 | 统一存储平台 | 传统文件服务替代 | 云存储服务 |
关键技术实现解析
HDFS架构特点
- 采用主从架构(Active NameNode + DataNodes)
- 块大小固定(默认128MB),适合顺序读写
- 通过心跳机制监控节点状态
- 写入时先分割再分发,读取时全局寻址
Ceph存储集群
- 基于CRUSH算法的伪随机数据分布
- 支持对象/块/文件三种存储接口
- 动态子树拆分实现负载均衡
- 支持EC(Erasure Coding)节省存储空间
GlusterFS特性
- 纯分布式架构(无中心元数据服务器)
- 弹性哈希(Elastic Hashing)算法
- 支持在线扩容(Automatic Volume Rebalance)
- 通过xattr存储元数据
Swift对象存储
- 完全对称的架构设计
- 分区器(Partitioner)+ 账户/容器三级索引
- 采用一致性哈希环(Consistent Hashing Ring)
- 支持永久缓存的中间代理节点
性能优化策略对比
| 优化维度 | HDFS | Ceph | GlusterFS | Swift |
|---|---|---|---|---|
| 写入性能 | 客户端流水线并发 | SDK并行上传 | N/A | 分段式多线程上传 |
| 读取性能 | 数据本地性优化 | 智能预取算法 | 客户端缓存加速 | CDN集成优化 |
| 扩展瓶颈 | NameNode内存限制 | CRUSH计算开销 | 哈希冲突处理 | 分区器单点压力 |
| 小文件处理 | HFT(Hadoop Filesystem Truncate) | 归并容器技术 | 前端合并策略 | 延迟删除机制 |
典型应用场景选择建议
大数据处理场景
- 优先选择HDFS:与Hadoop生态深度整合,支持MapReduce数据本地性
- 次选Ceph:通过S3接口兼容,支持EC编码节省存储空间
混合云存储场景
- 推荐Swift/Ceph:提供标准S3 API,支持跨云迁移
- 需注意版本控制和生命周期管理策略
传统企业级NAS替代
- GlusterFS:原生支持POSIX语义,兼容现有应用
- Ceph FUSE模块:通过FUSE实现文件系统挂载
冷数据归档场景
- 推荐纠删码模式(EC):Ceph/Swift均支持
- 需配置分层存储策略(冷热数据分离)
关键参数配置参考表
| 系统参数 | HDFS建议值 | Ceph建议值 | GlusterFS建议值 | Swift建议值 |
|---|---|---|---|---|
| 块/对象大小 | 128MB | 64MB-5GB | 64KB-128MB | 1MB-5GB |
| 副本数量 | 3 | 2-EC(8,4) | 2-4 | 3 |
| 客户端缓存 | 启用短路局部读 | 预取阈值500MB | auto_pin_time=30m | slo_dau=72h |
| 平衡阈值 | 33 | crush tunables | self-heal-daemon | container_sync |
常见问题解决方案
数据倾斜问题
- HDFS:运行balancer命令手动均衡
- Ceph:调整CRUSH bucket权重
- GlusterFS:开启自动修复(geo-replication)
- Swift:增加环分区数(part_power=N)
元数据瓶颈突破
- HDFS:升级NameNode硬件或启用HA模式
- Ceph:部署MDS for CephFS或使用RADOS网关
- GlusterFS:拆分卷(volume split)
- Swift:增加Account/Container层级数量
FAQs
Q1:如何判断应该选择对象存储还是块存储?
A:对象存储适合非结构化数据(如日志、图片),支持无限扩展和HTTP API;块存储适合数据库、虚拟机等需要低延迟随机读写的场景,可根据数据类型和访问模式选择,现代系统如Ceph可同时支持两种接口。
Q2:分布式文件系统出现数据不一致如何处理?
A:首先检查网络分区是否恢复,然后进行数据校验(如Ceph的scrub操作),对于强一致性要求场景,可启用写Quorum机制;允许最终一致性的场景可通过版本控制或后台数据
相关文章

ppt文件存储格式意思_存储格式
格式化一词在计算机领域通常指的是对存储设备(如硬盘、USB驱动器等)进行的一种操作,该操作会删除设备上的所有数据,并设置一个全新、干净的文件系统。这个过程通常用于清理干扰、修复文件系统错误或准备将设备出售或赠与其他人。,原创疑问句标题,,格式化操作究竟意味着什么?,为何我们需要对存储设备执行格式化?,格式化后的数据能否恢复?,格式化过程中发生了什么技术变化?,如何安全地进行格式化以避免数据泄露?
分布式文件存储系统小文件处理
tif是什么格式文件?tif格式文件用什么方法打开
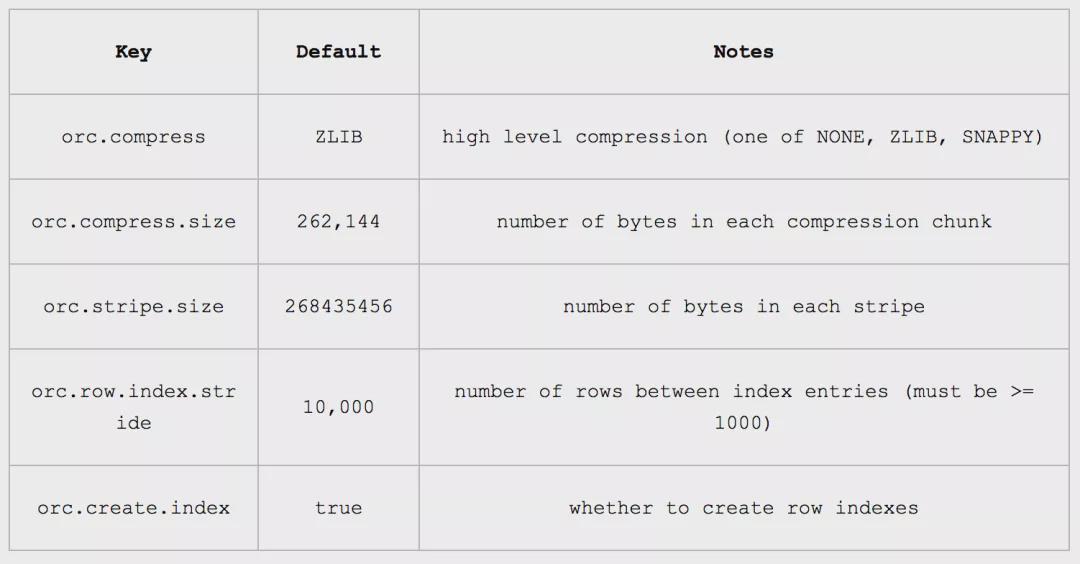
hive文件存储格式orc
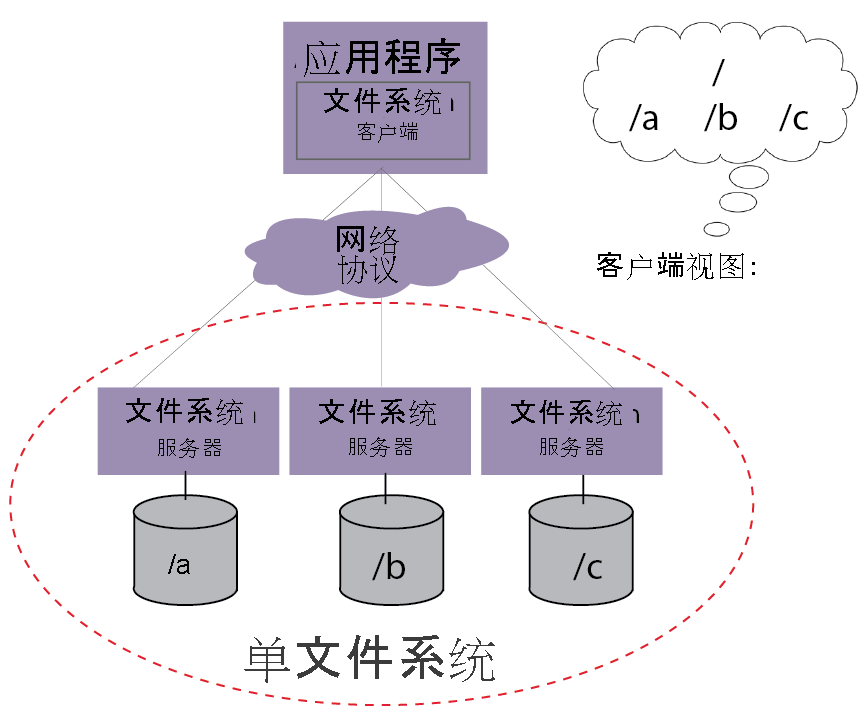
c 分布式文件存储
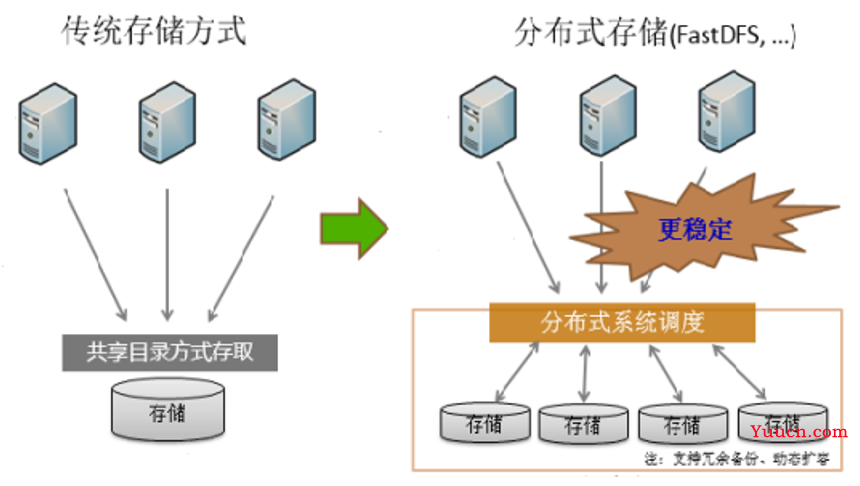
分布式文件存储系统是哪一个
分布式文件存储 开源








