上一篇
hive的数据存储
Hive依托HDFS存储数据,表结构对应文件目录,数据存为文本文件,按分区和桶组织,支持压缩与
Hive的数据存储机制详解
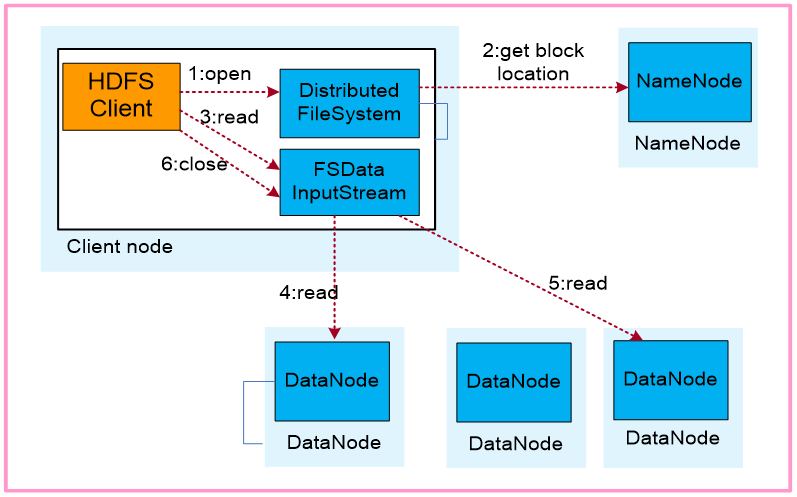
Hive作为基于Hadoop的数据仓库工具,其核心优势之一在于能够高效管理大规模数据的存储与查询,与传统关系型数据库不同,Hive并未直接操作数据文件,而是通过抽象的表结构映射到HDFS(Hadoop Distributed File System)中的文件和目录,以下从多个维度解析Hive的数据存储原理与实践。
Hive与HDFS的深度绑定
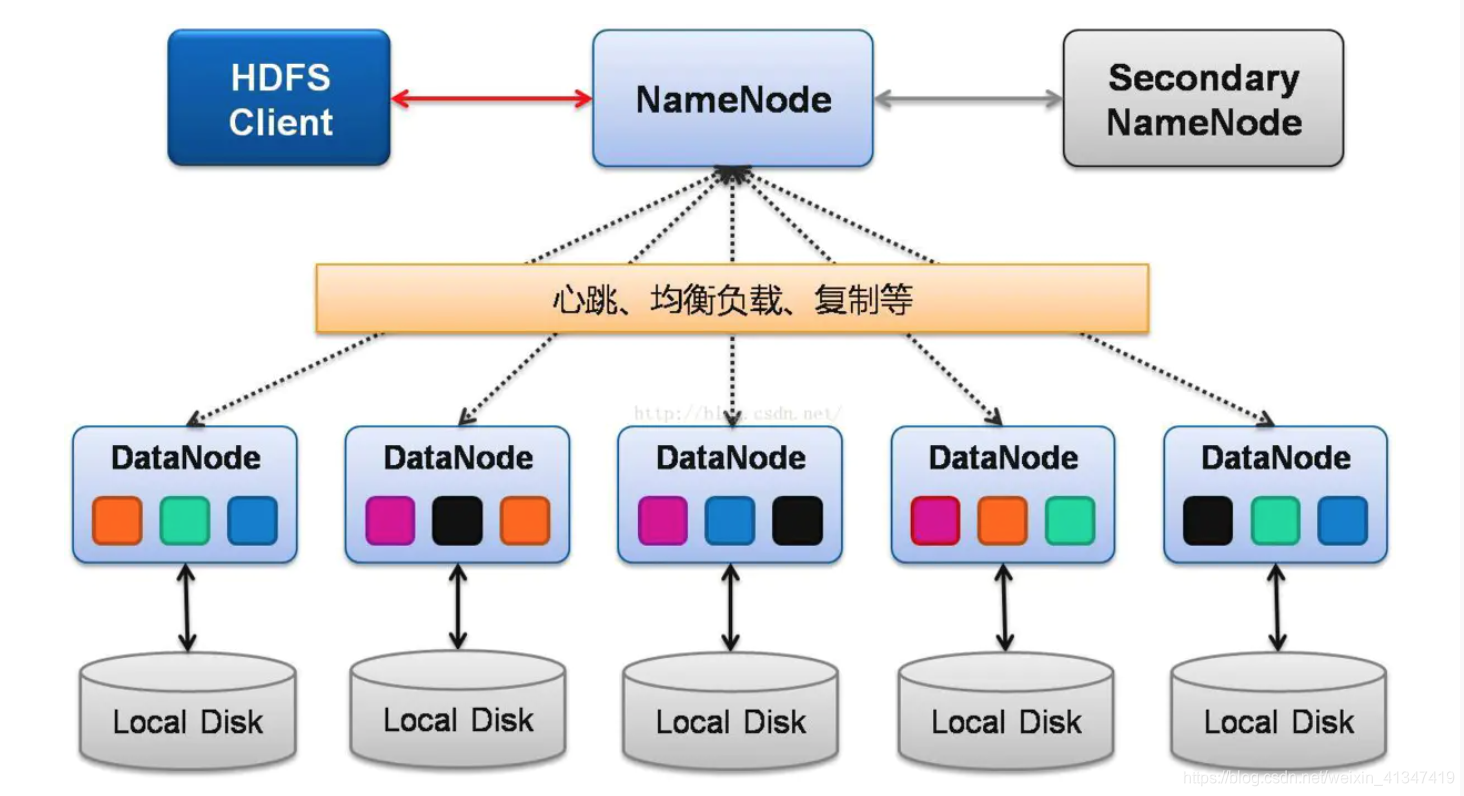
Hive的数据存储完全依赖HDFS,所有表数据、元数据(除SerDe库外)均以文件形式存储在HDFS中,这种设计使得Hive天然具备Hadoop生态的分布式存储能力,但也意味着其存储特性与HDFS紧密相关。
| 特性 | HDFS影响 |
|---|---|
| 数据分块 | 默认128MB分块,多副本存储(默认3份) |
| 目录层级 | 数据库对应HDFS目录,表对应子目录 |
| 文件合并 | 小文件问题需通过CombineHint或INSERT OVERWRITE优化 |
| 存储格式 | 需兼容HDFS文件系统(如ORC/Parquet需依赖相应库) |
典型路径示例:/user/hive/warehouse/database_name.db/table_name/
分区表会进一步生成partition_column=value/子目录。
Hive表的物理存储结构
Hive支持多种表类型,不同表类型的存储方式存在差异:
| 表类型 | 存储特点 |
|---|---|
| 内部表 | 数据和元数据均存储在HDFS中,删除表时数据一并删除 |
| 外部表 | 仅元数据存储在Hive MetaStore,数据保留在HDFS,适合与其他工具共享数据 |
| 分区表 | 按分区字段生成子目录,查询时可裁剪扫描范围(如dt=2023-10-01) |
| 桶表 | 基于哈希分配数据到多个文件,优化JOIN和采样操作 |
文件命名规则:
Hive会为每个数据文件生成唯一ID,part-m-00000.orc(m表示Map任务编号,00000为文件序号)
数据存储格式选择
Hive支持多种数据存储格式,不同格式在性能、压缩率和功能上各有优劣:

| 格式 | 特点 | 适用场景 |
|---|---|---|
| TextFile | 纯文本格式,无Schema约束,磁盘占用大 | 简单日志分析、临时数据 |
| SequenceFile | 二进制键值对格式,支持压缩,磁盘占用较小 | 中等规模数据批处理 |
| ORC | 列式存储,高压缩比,支持复杂类型和索引,读写性能均衡 | 大数据分析、OLAP场景 |
| Parquet | 列式存储,更高压缩率,支持嵌套结构,但部分功能依赖Trino/Spark | 云原生存储、深度学习数据集 |
| Avro | 动态Schema,支持嵌套结构,但Hive支持有限 | 多源数据融合 |
性能对比(以1TB数据扫描为例):
| 格式 | 扫描时间 | 存储大小 |
|————–|————–|————–|
| TextFile | 120s | 500GB+ |
| ORC | 45s | 120GB |
| Parquet | 38s | 100GB |
分区与桶策略
分区(Partitioning)
- 按业务维度(如日期、地区)划分子目录,减少全表扫描
- 动态分区需开启
hive.exec.dynamic.partition=true - 最佳实践:分区粒度需平衡(过细导致元数据膨胀,过粗降低查询效率)
桶(Bucketing)
- 通过
CLUSTERED BY哈希分桶,将数据均匀分配到多个文件 - 典型配置:
CLUSTERED BY (user_id) INTO 10 BUCKETS - 优势:优化JOIN操作(相同桶号的文件可并行处理)
- 通过
分区 vs 桶对比表:
| 维度 | 分区 | 桶 |
|—————-|——————————|———————————|
| 数据分布 | 业务维度(如时间、地域) | 哈希值(均匀分布) |
| 查询优化 | 裁剪扫描范围 | 加速JOIN/GROUP BY |
| 元数据开销 | 分区列存储在MetaStore | 无额外元数据 |
存储优化策略
文件合并
- 小文件问题会导致Map任务过多,可通过以下方式优化:
SET hive.merge.mapfiles = true; -自动合并小文件 SET hive.merge.size.per.task = 256000000; -触发合并阈值(256MB)
- 小文件问题会导致Map任务过多,可通过以下方式优化:
压缩配置
- 文件级别压缩:
ORC默认支持Zlib/Snappy,TEXTFILE需显式设置SET hive.exec.compress.output = true; -启用输出压缩 SET avro.output.codec = org.apache.hadoop.io.compress.SnappyCodec; -ORC压缩算法
- 传输压缩:启用
hive.server2.thrift.resultset.binary.transport=true减少网络开销
- 文件级别压缩:
索引加速
- Hive原生支持
COMPACTED和BITMAP索引:CREATE INDEX idx_order_id ON TABLE orders (order_id) AS 'COMPACTED'; -紧凑索引 ALTER TABLE users ADD INDEX idx_uid (uid) AS 'BITMAP'; -位图索引
- 注意:索引需配合语法使用,且会增加写操作开销
- Hive原生支持
数据生命周期管理
分区归档
- 历史分区可通过
ALTER TABLE DROP IF EXISTS PARTITION删除,或迁移至冷存储(如HDFS归档节点)
- 历史分区可通过
数据清理策略
- 使用
TRUNCATE TABLE清空表数据(保留表结构) - 通过
INSERT OVERWRITE覆盖旧数据,触发文件合并
- 使用
与外部工具集成
- 结合
Apache Oozie或Airflow实现定期分区清理 - 使用
HDFS ACL或Ranger控制数据访问权限
- 结合
FAQs
Q1:Hive是否支持事务(ACID)?
A1:Hive 0.14+版本支持ACID事务,需满足以下条件:
- 启用
hive.support.concurrency=true和hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager - 使用
ORC格式并开启transactional=true - 表需设置为
TRANSACTIONAL,CREATE TRANSACTIONAL TABLE orders (id BIGINT) STORED AS ORC;
Q2:如何监控Hive表的存储占用?
A2:可通过以下方式查看存储信息:
- HDFS命令:
hdfs dfs -du -h /path/to/table查看目录大小 - Hive命令:
SHOW TBL PROPERTIES table_name('totalSize')获取表总大小 - Web UI:通过Hadoop NameNode