上一篇
分布式数据库能干什么
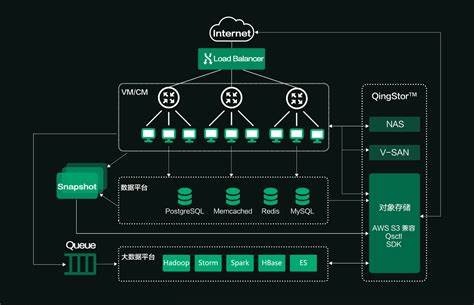
分布式数据库通过数据分片与多副本复制,实现海量数据存储、高并发处理及容错能力,支持水平扩展与负载均衡,适用于大规模数据处理、高可用系统构建,保障数据
分布式数据库的核心功能与能力
分布式数据库通过将数据分散存储在多个节点上,结合分布式计算和网络通信技术,解决了传统单机数据库在容量、性能、可靠性等方面的瓶颈,以下是其核心功能与应用场景:
海量数据存储与高效扩展
| 能力 | 说明 |
|---|---|
| 水平扩展(Scale-Out) | 通过增加节点实现存储和计算能力的线性扩展,支持PB级数据存储。 |
| 数据分片(Sharding) | 将数据按规则(如哈希、范围、列表)拆分到不同节点,均衡负载。 |
| 自动负载均衡 | 动态调整数据分布,避免热点节点,提升资源利用率。 |
典型场景:
- 大型电商平台(如淘宝、京东)处理亿级商品和用户数据。
- 社交网络(如微博、Facebook)存储用户动态、评论等非结构化数据。
- 物联网(IoT)设备日志的长期归档与分析。
高可用性与容灾能力
| 能力 | 说明 |
|---|---|
| 数据冗余与副本机制 | 通过主从复制、Paxos/Raft协议等实现数据多副本存储,保证单点故障不丢数据。 |
| 自动故障转移 | 节点故障时,系统自动切换到备用节点,业务无感知。 |
| 跨地域容灾 | 数据同步到不同地理区域,应对自然灾害或区域性故障。 |
典型场景:
- 金融交易系统(如银行核心账务)要求99.999%的高可用性。
- 在线教育平台(如Coursera)在全球多个区域部署,保障服务连续性。
- 游戏服务器集群(如《原神》)实现全球玩家低延迟访问。
高性能与低延迟
| 能力 | 说明 |
|---|---|
| 就近读写 | 数据分片后,用户请求可路由到最近节点,减少网络传输延迟。 |
| 并行查询与计算 | 复杂SQL查询可拆解为多个子任务,在多个节点并行执行,提升响应速度。 |
| 缓存优化 | 结合Redis、Memcached等缓存层,加速热点数据访问。 |
典型场景:

- 瞬秒活动(如拼多多“百亿补贴”)需支撑每秒百万级订单写入。
- 实时数据分析(如抖音推荐算法)要求亚秒级响应。
- 工业物联网(如智能制造)需要毫秒级数据采集与处理。
多模型支持与混合负载
| 能力 | 说明 |
|---|---|
| ACID与BASE灵活切换 | 支持事务型(如银行转账)和最终一致性(如日志分析)场景。 |
| 多数据模型支持 | 兼容关系型(MySQL语法)、文档型(MongoDB)、时序数据等多种模型。 |
| 混合负载处理 | 同时支持OLTP(在线交易)和OLAP(分析查询)需求。 |
典型场景:
- 新零售平台(如盒马)同时处理交易订单和用户行为分析。
- 车联网系统需存储结构化传感器数据和非结构化视频日志。
- 政务系统整合关系型业务数据与JSON格式的审批流程。
分布式数据库的技术优势对比
| 维度 | 分布式数据库 | 传统单机数据库 |
|---|---|---|
| 容量上限 | 理论上无上限(依赖节点扩展) | 受限于硬件(通常TB级) |
| 故障恢复时间 | 分钟级(自动切换) | 小时级(依赖人工干预) |
| 成本效率 | 按需扩展,长期成本低 | 硬件升级成本高,资源浪费严重 |
| 地理分布能力 | 支持全球多活架构 | 受限于单机房或数据中心 |
| 复杂度 | 运维复杂,需专业团队 | 部署简单,适合小规模场景 |
分布式数据库的挑战与限制
数据一致性难题
- CAP定理权衡:需在一致性(Consistency)、可用性(Availability)、分区容忍性(Partition Tolerance)之间取舍,金融场景优先强一致性(如2PC协议),而社交应用可选择最终一致性。
- 解决方案:通过分布式事务协议(如TCC、Saga)、冲突检测与合并(CRDT)等技术优化。
运维复杂度
- 问题:节点扩容/缩容、数据迁移、监控调优需要专业化工具和团队。
- 典型工具:Apache Kafka(数据管道)、Prometheus(监控)、Kubernetes(容器编排)。
成本考量
- 硬件成本:服务器、网络设备、机房资源。
- 软件成本:开源数据库(如TiDB、CockroachDB)免费,但企业版(如Oracle Sharding)费用高昂。
- 隐形成本:运维人力、带宽消耗、数据冷存储。
分布式数据库的选型建议
根据业务需求选择合适产品:
| 场景 | 推荐数据库 | 关键特性 |
|————————-|——————————————–|———————————————|
| 高并发电商交易 | Alibaba OceanBase、Amazon Aurora | 强一致性、高吞吐、自动扩缩容 |
| 实时数据分析 | ClickHouse、Google Bigtable | 列式存储、向量化计算、低延迟 |
| 全球化多活架构 | CockroachDB、Azure Cosmos DB | 跨区域同步、多模型支持、低延迟 |
| 低成本日志存储 | Apache Cassandra、HBase | 高写入吞吐量、可配置一致性级别、压缩存储 |
FAQs
Q1:分布式数据库适合什么样的业务?
- 答案:适合数据量大(GB→PB)、高并发(每秒万级请求)、对可用性要求高(如7×24小时服务)的业务,例如电商、金融、游戏、物联网等,若业务数据量小且访问低频(如小型企业官网),单机数据库可能更经济。
Q2:如何判断是否需要从单机数据库迁移到分布式数据库?
- 答案:当出现以下情况时需考虑迁移:
- 单机存储接近上限(如MySQL单表超过TB)。
- 高峰期并发导致CPU/IO饱和(如促销活动)。
- 业务需要跨地域部署(如全球化服务)。
- 数据分片需求明显(如按用户ID划分数据)。