上一篇
hive直接追加数据库
在Hive中,可通过创建外部表关联数据目录或使用分区表动态追加数据,实现直接向数据库追加,避免手动
Hive直接追加数据库的实现原理与操作指南
核心概念解析
Hive直接追加数据(Direct Append)是指在不删除原有数据或中断服务的情况下,将新数据持续写入目标表的操作,该功能依赖于Hive的ACID(原子性、一致性、隔离性、持久性)特性,需配合事务表使用,与传统的”覆盖写入”模式相比,直接追加可保障数据完整性,避免因并发写入导致的数据冲突。

实现前提条件
| 配置项 | 说明 |
|---|---|
| %ignore_a_3%.txn.manager | 必须设置为true(启用事务管理器) |
| hive.support.concurrency | 需设置为true(支持并发操作) |
| hive.strict.checks.append | 控制追加数据的严格性(建议保持true) |
| hive.compactor.initiator.on | 设置自动清理(建议设置为true) |
| zookeeper.session.timeout | 需大于hive.txn.timeout(通常设置为30000ms以上) |
注意:Hive 2.x及以上版本才支持完整的ACID事务,需配合Apache ZooKeeper进行元数据管理。
操作流程详解
创建事务表
CREATE TABLE user_logs (
uid STRING,
action STRING,
timestamp BIGINT
)
PARTITIONED BY (dt STRING)
STORED AS ORC
TBLPROPERTIES ('transactional'='true');直接追加数据
-非分区表追加
INSERT INTO TABLE user_logs VALUES ('A001', 'login', 1625097600);
-分区表追加(需开启动态分区)
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
INSERT INTO TABLE user_logs PARTITION(dt='2023-10-01') VALUES ('A002', 'purchase', 1625097700);批量追加优化
// 使用HiveJDBC进行批量追加
Connection conn = DriverManager.getConnection(jdbcUrl);
Statement stmt = conn.createStatement();
stmt.execute("SET hive.batch.size=2000"); // 设置批处理大小
for(Record record : records){
stmt.addBatch("INSERT INTO TABLE user_logs VALUES (?, ?, ?)");
}
stmt.executeBatch();关键参数调优
| 参数 | 默认值 | 调优建议 |
|---|---|---|
| hive.txn.txns.threshold | 10000 | 根据集群负载调整(建议5000-20000) |
| hive.txn.timeout | 60000ms | 复杂业务可提升至120000ms |
| hive.compactor.delta.num.threshold | 10 | 高频追加场景建议设为5 |
| hive.auto.convert.sortmerge | true | 大表追加时保持true以优化查询性能 |
常见问题处理
追加失败处理流程
graph TD
A[追加失败] --> B{检查事务状态}
B -->|未提交| C[执行ROLLBACK]
B -->|已提交| D[检查HDFS文件]
D --> E[文件存在]
E --> F[修复文件元数据]
D --> G[文件不存在]
G --> H[检查日志排查网络问题]数据一致性验证
-验证记录数 SELECT COUNT() FROM user_logs WHERE dt='2023-10-01'; -验证最新偏移量 DESCRIBE EXTENDED user_logs PARTITION(dt='2023-10-01');
性能优化策略
- 合并小文件:设置
hive.merge.mapfiles=true和hive.merge.mapredfiles=true - 预分区处理:使用
INSERT OVERWRITE预先生成分区目录结构 - 索引优化:对频繁追加的字段建立COMPACT索引
- 资源隔离:通过
hive.query.max.temp.disk.space.per.node限制单节点IO负载
与其他系统的集成方案
| 数据源 | 集成方式 |
|---|---|
| Kafka | 使用CREATE TABLE ... STORE AS KAFKA创建Kafka源表 |
| Flume | 配置Flume Sink为Hive Transactional Table |
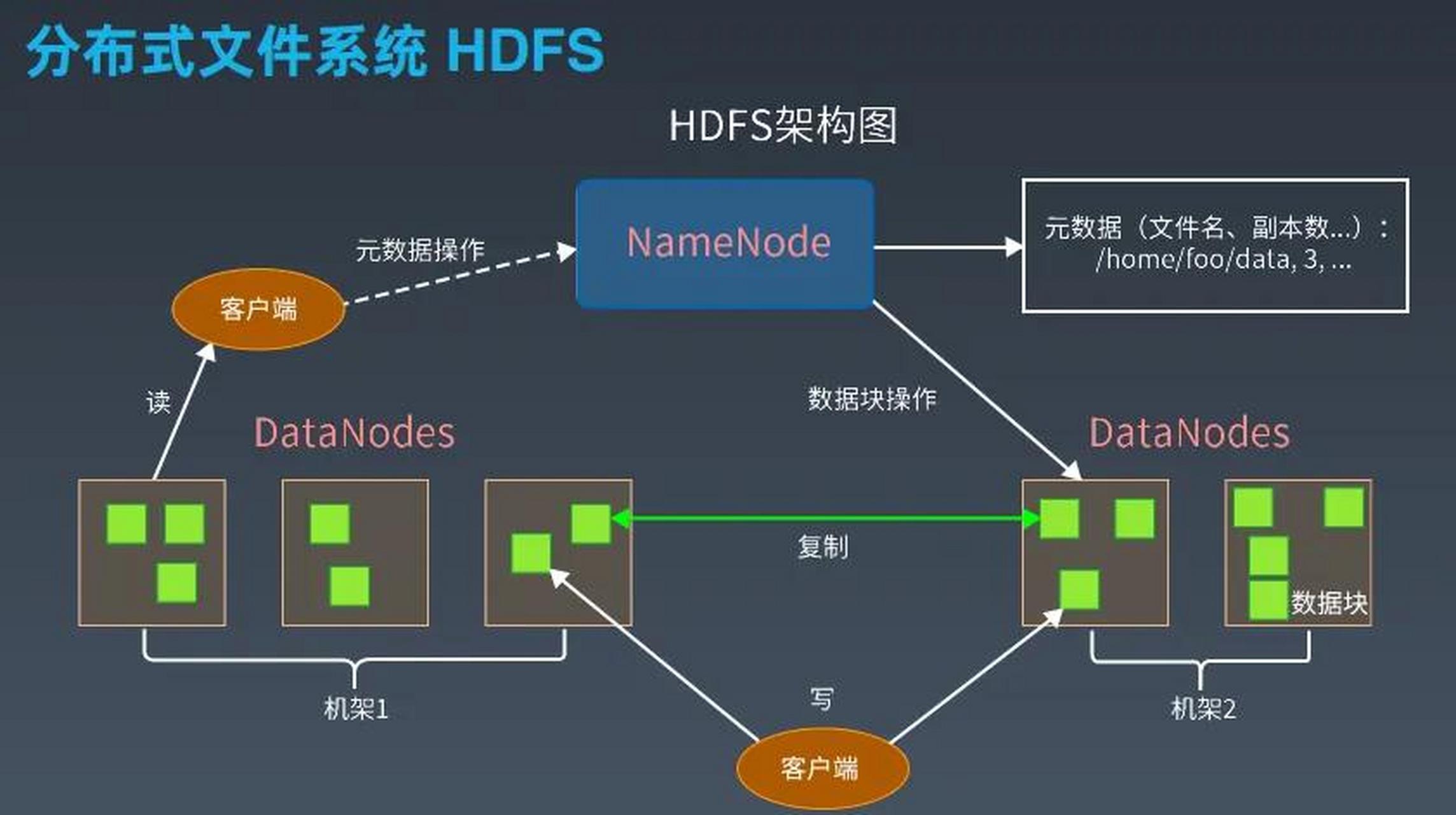
| HDFS | 通过LOAD DATA INPATH结合hive.exec.source.mode=append实现 |
| 关系型数据库 | 使用Sqoop导入时添加--append参数并确保目标表为事务表 |
FAQs
Q1:直接追加失败后如何恢复?
A1:若事务未提交,可通过SHOW TRANSACTIONS查看未完成事务,执行ROLLBACK回滚;若已提交但数据异常,需使用MSCK REPAIR TABLE修复元数据,并通过ALTER TABLE ... RECOVER PARTITIONS恢复分区。
Q2:开启严格模式对追加有什么影响?
A2:当hive.strict.checks.append=true时,系统会校验主键约束和分区路径合法性,例如向包含uid主键的表追加重复记录时会被拒绝,但能保证数据唯一性,建议在生产