
上一篇
https开头的网站如何采集
使用Scrapy/BeautifulSoup等工具,配置SSL证书验证,添加User-Agent和Cookies,处理重定向,检查robots协议,模拟
HTTPS网站采集核心要点
理解HTTPS协议特性
- 加密传输:数据采用SSL/TLS加密,无法直接抓取明文内容
- 证书验证:客户端会校验服务器SSL证书有效性
- 握手过程:包含证书交换和密钥协商过程
主流采集工具适配方案
| 工具类型 | 处理方式 | 示例代码 | 注意事项 |
|---|---|---|---|
| Python requests | verify=False跳过验证 | requests.get(url, verify=False) | 存在安全风险,建议指定自定义CA证书 |
| Scrapy框架 | 设置DOWNLOADER_CLIENT_CERT | 在settings.py配置证书路径 | 需配合Crawlera等中间件使用 |
| Node.js Axios | 设置rejectUnauthorized: false | javascript axios.get(url, { httpsAgent: new https.Agent({ rejectUnauthorized: false }) }) | 生产环境慎用 |
| Java HttpClient | 禁用证书校验 | HttpClient.create().setSslContext(NoopSocketFactory.getDefault()) | 需处理证书信任存储 |
| PhantomJS/Selenium | 自动处理证书 | 直接访问HTTPS地址 | 依赖浏览器内核证书库 |
SSL证书处理方案
graph TD
A[证书问题] --> B{自建证书库}
A --> C{使用公共CA}
B --> D[下载站点证书]
D --> E[导入本地证书库]
C --> F[使用certifi库]
F --> G[自动更新CA证书]
E --> H[配置工具使用本地库]
H --> I[设置verify=本地证书路径]高级采集场景处理
- 单向证书网站:
import certifi session = requests.Session() session.verify = certifi.where() # 使用certifi内置CA库
- 自签名证书网站:
# 下载证书并添加到信任列表 openssl s_client -showcerts -connect example.com:443 < /dev/null | openssl x509 > server.crt
- 中间人代理采集:
sequenceDiagram participant Browser participant MitmProxy participant TargetServer Browser->>MitmProxy: HTTPS请求 MitmProxy->>TargetServer: 转发请求 TargetServer-->>MitmProxy: 返回响应 MitmProxy-->>Browser: 转发响应(解密后)
常见问题与解决方案
问题1:requests库出现CERTIFICATE_VERIFY_FAILED错误
解决方案:

- 安装certifi库并指定CA文件:
import certifi response = requests.get('https://example.com', verify=certifi.where()) - 更新系统CA证书(Linux):
sudo update-ca-certificates
问题2:Scrapy框架无法采集HTTPS页面
解决方案:
- 安装
pyopenssl和cryptography库 - 配置
settings.py:DOWNLOADER_CLIENT_CERT = (cert_path, key_path) DOWNLOAD_HANDLERS = { 'https': 'scrapy.core.downloader.handlers.http.HttpDownloadHandler', } - 启用
scrapy-user-agents中间件模拟真实浏览器
相关技术扩展
| 技术领域 | 推荐工具 | 适用场景 |
|---|---|---|
| 动态渲染采集 | Puppeteer/Playwright | 需要执行JS的页面 |
| 分布式采集 | Scrapy-Redis | 大规模数据采集 |
| 反反爬虫 | mitmproxy | 分析网站防护机制 |
| 数据存储 | MongoDB/Elasticsearch | 结构化 |
相关文章

https开头的网站安全吗

由于本站全新链接内容无法直接访问,我无法得知文章的具体内容。但是,我可以基于常见的与HTTPS和CDN相关的主题为您创建一个原创的疑问句标题,,如何确保使用CDN时HTTPS连接的安全性?,假设文章讨论的是在使用内容分发网络(CDN)服务时保持HTTP Secure(HTTPS)连接的安全最佳实践。如果文章内容与此相关,那么这个标题可以很好地概括文章的主旨。如果文章内容是关于其他具体方面,请提供更多信息,以便我能提供一个更加精确的标题。
火车头怎么采集网址,wordpress火车头采集(火车头采集器如何采集文章)

DataWorks中M 开头的是 map 阶段,这种 J 开头的 是 shuffle 阶段吗?

什么是以M开头的域名和以$开头的对象名称?
配置了https_直播配置了HTTPS证书,为什么HTTPS访问失败?
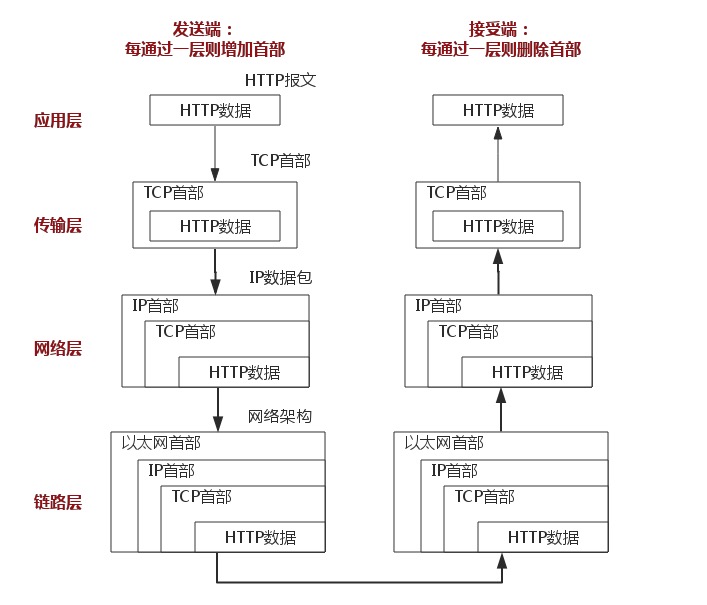
http和https协议(https协议)

wordpress开启ssl(WordPress开启https)








