上一篇
个性化推荐网站
个性化推荐网站通过数据收集与算法分析,构建用户画像并实时反馈优化,实现精准内容推送,有效提升
技术原理、应用场景与发展趋势
%ignore_a_3%系统的核心概念
个性化推荐系统是通过分析用户行为、兴趣偏好及上下文环境,自动为用户提供定制化内容的服务,其核心目标是解决信息过载问题,提升用户体验与商业价值,典型应用场景包括电商商品推荐(如亚马逊)、内容推送(如Netflix、抖音)、广告投放(如Google Ads)等。
关键技术分类:
| 推荐算法类型 | 原理 | 适用场景 |
|——————|———-|————–|
| 协同过滤(CF) | 基于用户相似性或物品相似性 | 用户行为数据丰富场景(如电商) |based推荐 | 基于物品特征与用户画像匹配 | 冷启动问题缓解(如新闻推荐) |
| 混合推荐 | 结合多种算法优势 | 复杂业务场景(如视频平台) |
| 深度学习推荐 | 神经网络建模用户-物品关系 | 大规模数据处理(如TikTok) |
技术实现路径
数据采集与预处理
- 显性数据:用户评分(如豆瓣)、收藏/点赞行为。
- 隐性数据:浏览时长、点击顺序、购物车行为。
- 上下文数据:时间、地点、设备类型。
- 清洗流程:去重、归一化、缺失值填充。
特征工程
- 用户侧特征:人口属性(年龄、性别)、历史行为序列。
- 物品侧特征:品类、价格、内容标签(如电影题材)。
- 交叉特征:用户-物品交互特征(如购买频率矩阵)。
模型训练与优化
- 传统算法:
- 用户CF:计算用户相似度(余弦相似度、Jaccard指数)。
- 物品CF:基于物品共现矩阵(如亚马逊”购买此商品的人还买了”)。
- 深度学习模型:
- 矩阵分解(ALS、SVD++):解决稀疏矩阵问题。
- 神经协同过滤(NCF):使用神经网络捕捉非线性关系。
- 序列模型(RNN/Transformer):建模用户行为时序(如淘宝”猜你喜欢”)。
- 传统算法:
实时反馈与迭代

- 在线AB测试:对比不同算法效果(CTR、转化率)。
- 带宽控制与长尾内容的曝光平衡。
- 负反馈机制:用户屏蔽操作的权重调整。
典型应用场景分析
| 领域 | 推荐目标 | 核心技术 | 挑战 |
|---|---|---|---|
| 电商(如亚马逊) | 跨品类商品推荐 | 协同过滤+知识图谱 | 冷启动、动态库存匹配 |
| 视频平台(如Netflix) | 个性化剧集推荐 | 深度学习+时序模型 | 内容长尾挖掘、续播预测 |
| 新闻资讯(如今日头条) | 即时热点推送 | 内容聚类+LR模型 | 时效性与用户兴趣平衡 |
| 音乐流媒体(如Spotify) | 歌单生成 | 音频特征提取+MBRNN | 风格多样性保障 |
案例:Netflix推荐系统
- 技术栈:
- 混合模型:矩阵分解(基础)+ 深度学习(视频标签嵌入)。
- 上下文感知:根据观看设备(TV/手机)调整推荐策略。
- 离线计算:每日批量更新模型,实时服务使用缓存。
- 效果指标:
- CTR提升:通过多臂菠菜机算法优化曝光策略。
- 留存率:基于用户生命周期阶段动态调整推荐强度。
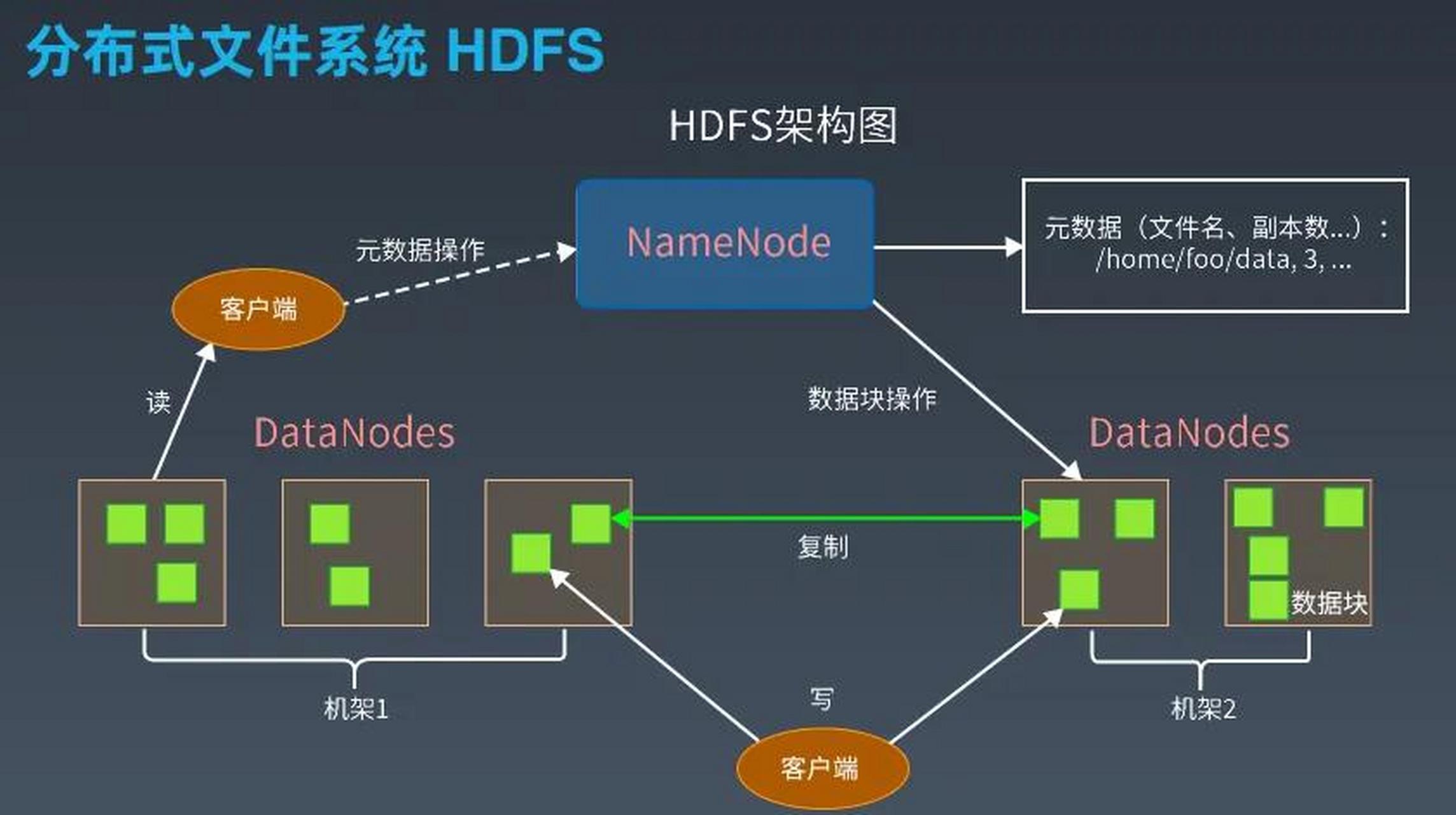
系统架构设计
!个性化推荐系统架构图
(注:图示为典型分层架构,含数据层、算法层、服务层)
核心模块:
- 日志采集层:埋点收集用户行为(JavaScript事件监听)。
- 实时处理层:Flink/Spark Streaming处理秒级行为数据。
- 特征存储层:Redis/HBase存储高维稀疏特征。
- 模型服务层:TensorFlow Serving部署推理模型。
- 策略决策层:规则引擎(Drools)控制曝光逻辑。
效果评估体系
| 指标类别 | 典型指标 | 优化方向 |
|---|---|---|
| 精准度 | Precision@K | 特征工程优化 |
| 召回率 | Recall@K | 算法融合 |
| 多样性 | HHI指数 | 探索-利用平衡 |
| 新颖性 | Novelty | 挖掘 |
| 商业价值 | GMV/CPM | 动态出价模型 |
常用评估方法:
- 离线评估:基于历史数据的召回率@10、NDCG指标。
- 在线AB测试:对照组与实验组的留存率对比。
- 长期LTV评估:用户生命周期价值分析。
挑战与解决方案
冷启动问题
- 方案:
- 新用户:引导填写兴趣标签+热门内容试探。
- 新物品:内容相似度匹配+专家标注。
- 混合方法:Facebook的EdgeRank算法结合社交关系。
- 方案:
数据稀疏性
- 应对策略:
- 矩阵填充:使用AutoRec模型补全缺失值。
- 迁移学习:跨领域知识迁移(如图书推荐经验应用于电影)。
- 元学习:MetaLearning优化小样本训练。
- 应对策略:
隐私合规
- 技术手段:
- 差分隐私:在模型训练中添加噪声(Apple的差分隐私实践)。
- 联邦学习:边缘设备本地训练+参数聚合(谷歌Gboard输入法)。
- 数据脱敏:用户ID哈希化处理。
- 技术手段:
未来发展趋势
多模态融合推荐:
- 结合文本(评论分析)、图像(封面识别)、语音(搜索词)多维度数据。
- 跨模态对齐技术:CLIP模型实现图文联合表征。
因果推理应用:
- 通过反事实推断解决”曝光偏差”问题(如淘宝的Causal Graph学习)。
- 长期价值评估:考虑推荐动作对用户生命周期的影响。
可解释性推荐:
- 特征重要性排序(SHAP值可视化)。
- 规则可读化:Amazon的”因为您购买了…”解释逻辑。
边缘计算优化:
- 移动端本地模型推理(TFLite Micro)。
- P2P推荐网络:用户间直接共享热门内容(BitTorrent式分发)。
FAQs
Q1:如何快速搭建一个初级个性化推荐系统?
A:可参考以下三步路径:
- 数据采集:集成埋点SDK(如阿里云Analytics),收集用户点击/购买事件。
- 简易模型:使用Surprise库实现基于ItemCF的推荐,或调用AWS Personalize服务。
- 效果验证:通过Jupyter Notebook进行离线评估,关注准确率@5指标。
Q2:如何防止推荐系统造成”信息茧房”?
A:需从三方面干预:
- 算法层面:加入多样性约束项(如Google的Novelty Search算法)。
- 策略层面:强制插入热门/冷门内容(抖音的”探索”频道)。
- 交互设计:提供”不感兴趣”