上一篇
分布式与大数据存储
分布式存储通过多节点协同实现数据分片与冗余,提升大数据存储的扩展性、可靠性及处理效率,支撑海量
核心技术与实践解析
分布式存储基础
分布式存储通过将数据分散存储在多个节点上,结合网络通信和冗余机制实现高可用性与扩展性,其核心目标是解决传统集中式存储的容量瓶颈、单点故障和性能限制问题,典型特征包括:
- 数据分片(Sharding):将数据拆分为多个片段,分布到不同节点。
- 冗余备份:通过副本或纠删码保障数据可靠性。
- 去中心化管理:采用分布式算法协调节点间的数据一致性。
CAP定理是分布式系统的理论基础,指出在一致性(Consistency)、可用性(Availability)、分区容忍性(Partition Tolerance)三者中最多只能同时满足两项,实际应用中需根据业务场景权衡:
- CP模式(如ZooKeeper):优先保证数据一致性,适用于金融交易。
- AP模式(如DynamoDB):允许临时不一致,适合社交应用。
- CA模式:仅在无网络分区时成立,实际场景较少。
大数据存储需求分析
大数据场景对存储系统提出更高要求,主要体现在:
| 需求维度 | 具体要求 |
|——————–|—————————————————————————–|
| 数据规模 | 支持EB级存储,横向扩展能力(如从100TB扩展到10PB) |
| 数据类型 | 结构化(SQL)、半结构化(JSON)、非结构化(图片/视频)混合存储 |
| 访问模式 | 高频写入(日志流)、批量分析(MapReduce)、实时查询(OLAP)混合负载 |
| 成本控制 | 单位存储成本低于$0.05/GB,运维自动化率>90% |
| 延迟要求 | 热数据访问延迟<10ms,冷数据访问<1s |
核心架构设计
现代分布式存储系统通常包含三层架构:
存储层:
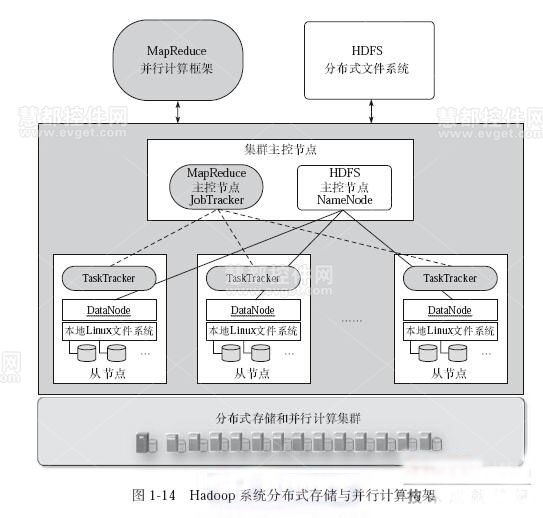
- 分布式文件系统:HDFS(块存储,128MB默认块大小)、Ceph(统一存储)、GlusterFS(POSIX兼容)
- 对象存储:MinIO(S3兼容)、Ceph RADOS Gateway(多协议支持)
- 新型存储引擎:Apache Cassandra(宽表数据库)、HBase(列式存储)
计算层:
- 离线计算:Hadoop MapReduce、Spark(内存迭代)
- 实时计算:Flink(流批一体)、Storm(低延迟流处理)
- 查询引擎:Impala(MPP架构)、Presto(SQL-on-Hadoop)
管理层:

- 元数据管理:采用Raft协议实现分布式一致性(如Ceph MON)
- 资源调度:Kubernetes+HDFS实现存储容器化编排
- 监控体系:Prometheus+Grafana实现全链路监控
主流技术对比
| 系统名称 | 架构特点 | 数据一致性 | 扩展性 | 典型场景 |
|---|---|---|---|---|
| Hadoop HDFS | 主从架构,块存储 | 强一致性(写时同步) | 横向扩展至千节点 | 离线批处理(日志分析) |
| Ceph | CRUSH算法,统一存储接口 | 最终一致性 | 动态扩缩容 | 云存储、混合云 |
| GlusterFS | Btrfs底层,POSIX兼容 | 异步复制 | 线性扩展 | 文件服务器替代 |
| MinIO | S3协议,Go语言实现 | 版本化一致性 | 容器化部署 | 云原生应用 |
| Apache Cassandra | 环形拓扑,LSM树 | 可调一致性(QUORUM) | 无缝扩展 | IoT时序数据 |
关键技术实现
数据分片与副本机制:
- 哈希分片:一致性哈希减少重分配(如DynamoDB)
- 范围分片:按时间/ID分段(如TD-HBase)
- 副本策略:3副本(HDFS)、EC纠删码(Azure Blob)
元数据管理优化:
- 分层缓存:本地缓存+分布式缓存(Redis)
- 分区策略:按目录哈希分区(Ceph PG)
- 脑裂防护:Paxos/Raft协议实现选主
容错与恢复:
- 心跳检测:5秒间隔检测节点状态
- 自动重均衡:负载>85%触发数据迁移
- 快照机制:QoS策略保障恢复优先级
性能优化方案:
| 优化方向 | 技术手段 | 效果提升 |
|————–|—————————————|————————–|
| 网络传输 | RDMA(远程直接内存访问) | 延迟降低60% |
| 存储介质 | NVMe SSD+ZNS(分区命名空间) | IOPS提升10倍 |
| 计算存储分离| TiFlash(HTAP架构) | 查询延迟降低40% |
| 索引加速 | BloomFilter+LSM Tree | 写吞吐提升3倍 |
典型应用场景
互联网企业:
- 日志存储:Elasticsearch+HDFS冷热分层
- 用户画像:HBase+Spark实时更新标签
- 推荐系统:Cassandra存储特征向量
金融机构:
- 交易记录:Kafka持久化+Quorum机制
- 风控审计:Immutable Storage(不可改动存储)
- 报表分析:ClickHouse列式存储+向量化查询
科研领域:
- 基因测序:Ceph存储PB级CRISPR数据
- 气候模拟:BeeGFS并行文件系统
- LHC实验:XRootD协议传输PB/s级数据
物联网场景:
- 设备日志:TimescaleDB时序数据库
- 边缘计算:KubeEdge+Local Storage
- 视频监控:Ceph对象存储+FFmpeg转码
挑战与优化方向
数据一致性难题:
- 混合一致性模型:Google Spanner的TrueTime API
- PACELC定理演进:增加成本约束维度
- 多副本共识:Raft协议优化(etcd/TiKV)
扩展性瓶颈突破:
- 计算存储分离:AWS S3 Glacier架构
- 异构资源调度:Kubernetes Device Plugins
- 智能分片:AI预测热点数据分布
成本控制策略:
- 冷热数据分层:Azure Hot/Cool/Archive Tier
- 压缩算法:Zstandard(Facebook开源)替代Snappy
- 硬件优化:ARM服务器+QLC闪存组合
安全与合规:
- 加密传输:TLS 1.3+零信任架构
- 访问控制:SPIFFE/SPIRE身份验证
- 数据主权:多区域副本+本地化留存
FAQs
Q1:分布式存储与集中式存储的核心区别是什么?
A1:分布式存储通过多节点协同实现三大突破:①容量线性扩展(集中式存在单机上限);②故障域隔离(单节点故障不影响全局);③地理位置分散(支持跨数据中心部署),但需付出一致性维护和网络开销的代价。
Q2:如何选择适合业务的大数据存储系统?
A2:需评估四个维度:①数据特征(结构化/非结构化);②访问模式(高频写入/实时查询);③一致性要求(金融级强一致/互联网最终一致);④成本预算(开源方案/云服务),例如电商推荐系统适合Cassandra(高写入+水平扩展),医疗影像归档宜选Ceph(多协议支持