上一篇
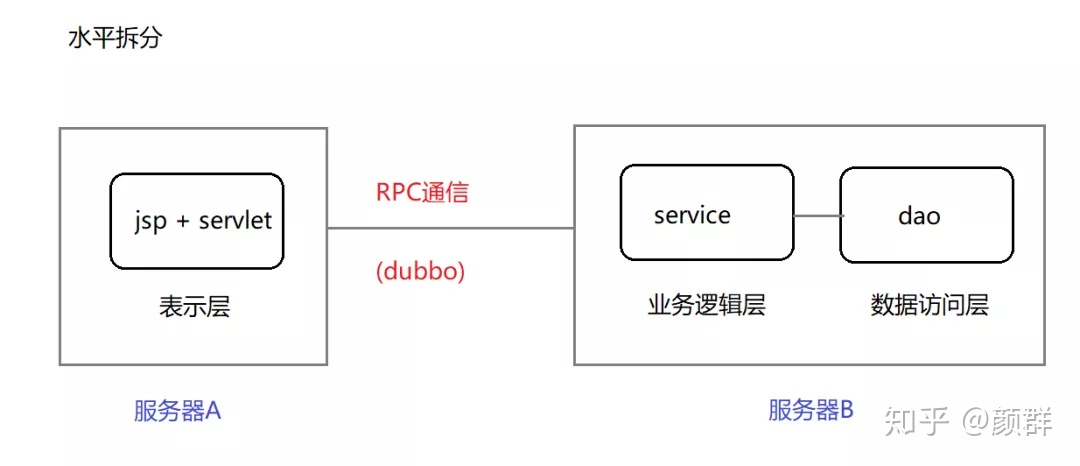
分布式存储和分布式处理
分布式存储分散数据至多节点,分布式处理并行任务于
分布式存储与分布式处理详解
核心概念与目标差异
| 维度 | 分布式存储 | 分布式处理 |
|---|---|---|
| 核心目标 | 实现海量数据的可靠存储与高效访问 | 完成大规模计算任务的并行执行 |
| 关键指标 | 数据持久性、容灾能力、读写性能 | 任务吞吐量、计算延迟、资源利用率 |
| 技术焦点 | 数据分片、副本机制、元数据管理 | 任务调度、负载均衡、计算资源分配 |
核心技术架构解析
(一)分布式存储关键技术
数据分片策略
- 哈希分片:通过一致性哈希算法实现数据均匀分布(如Ceph)
- 范围分片:按数据特征划分区间(如时间序列数据库)
- 示例:HDFS将文件切分为64MB块,通过NameNode管理元数据
冗余保护机制
| 方案类型 | 副本数 | 适用场景 | 典型实现 |
|———-|——–|————————-|——————-|
| 全量复制 | ≥3 | 高可用要求业务 | HDFS/FastDFS |
| 纠删编码 | 1.5n | 存储成本敏感型场景 | Ceph/Azure Blob |
| 混合模式 | 动态 | 冷热数据分层存储 | 阿里云OSS |元数据管理

- 集中式架构:单点瓶颈(如传统HDFS NameNode)
- 分布式架构:采用Raft协议实现元数据多副本同步(如Ceph MON)
(二)分布式处理关键技术
计算框架
- MapReduce:Google提出的离线批处理模型(Hadoop实现)
- Spark:基于内存的迭代式计算引擎,支持流批一体
- Flink:低延迟流处理框架,支持事件时间语义
任务调度系统
- YARN:Hadoop的资源管理系统,支持多租户隔离
- Mesos:Twitter开发的分布式资源调度器
- Kubernetes:容器化编排系统,支持自定义算子
状态管理
- 无状态设计:每任务独立运行(如MapReduce)
- 有状态计算:维护运算状态(如Flink Checkpoint)
典型应用场景对比
| 场景类型 | 分布式存储应用 | 分布式处理应用 |
|---|---|---|
| 互联网领域 | 用户画像数据存储(TB级) | 实时推荐系统(毫秒级响应) |
| 金融行业 | 交易流水日志归档(合规需求) | 反欺诈规则引擎(百万QPS处理) |
| 物联网 | 设备传感器数据持久化(PB级) | 设备异常检测(流式数据分析) |
| AI训练 | 训练数据集管理(多模态数据) | 分布式梯度计算(参数服务器架构) |
性能优化策略对比
(一)分布式存储优化
- 读写分离架构:采用主副本提升写入性能(如TiDB的Raft协议)
- 缓存加速:部署LRU缓存层(如Redis作为元数据缓存)
- 压缩算法:列式存储+LZ4压缩(HBase/Greenplum)
(二)分布式处理优化
- 数据本地性:计算任务向数据节点迁移(Yarn调度策略)
- 管道并行:多阶段任务流水线执行(Spark DAG优化)
- 自适应执行:基于运行时统计动态调整并行度(Flink)
容错机制实现对比
| 故障类型 | 存储系统应对方案 | 处理系统应对方案 |
|---|---|---|
| 节点宕机 | 自动副本重建(HDFS 3副本机制) | 任务重试(YARN AM重启) |
| 网络分区 | Paxos协议保证元数据一致(Ceph MON) | 心跳超时转移计算任务(Mesos) |
| 磁盘故障 | 热备盘自动替换(RAID6校验) | 中间结果持久化(Spark Lineage) |
技术选型决策树
graph TD
A[业务需求] --> B{数据密集型?}
B -->|是| C[选择分布式存储]
B -->|否| D{计算密集型?}
D -->|是| E[选择分布式处理]
D -->|否| F[混合架构]
C --> G[评估CAP权衡]
E --> H[选择计算框架]
F --> I[Lambda架构]发展趋势展望
- 存储处理一体化:S3 Select实现对象存储直接查询
- 边缘协同:CDN节点兼具存储计算能力(如Edge Computing)
- 硬件加速:FPGA/GPU集群提升异构计算效率
- Serverless化:FaaS框架支持自动扩缩容(AWS Lambda)
FAQs
Q1:分布式存储和分布式处理的主要区别是什么?
A:核心区别在于目标定位:分布式存储解决海量数据的可靠保存与访问问题,关注数据冗余、持久化等;分布式处理侧重于大规模计算任务的分解与协同执行,强调计算资源的调度优化,形象比喻,存储如同建设”数字仓库”,处理则是在仓库中建立”自动化生产线”。
Q2:什么场景需要同时使用分布式存储和处理?
A:典型场景包括:
- 大数据分析:先用分布式存储(如HDFS)保存PB级日志,再用Spark进行挖掘分析
- 实时数仓:Kafka持久化流数据,Flink进行窗口计算
- AI训练:MinIO存储训练样本,PyTorch分布式框架进行模型迭代
两者结合形成”存算分离”架构,既保证数据可靠性