上一篇
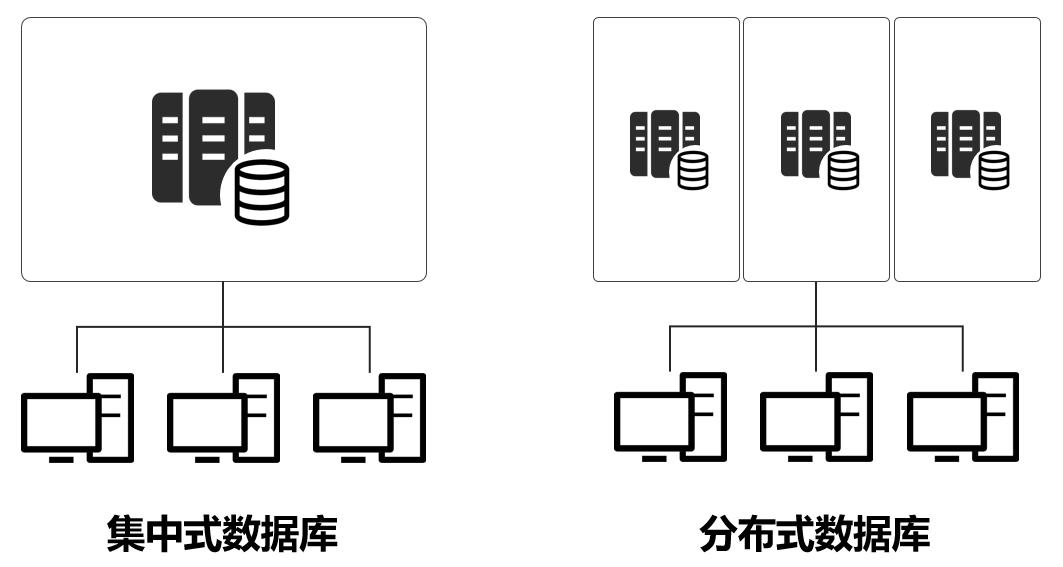
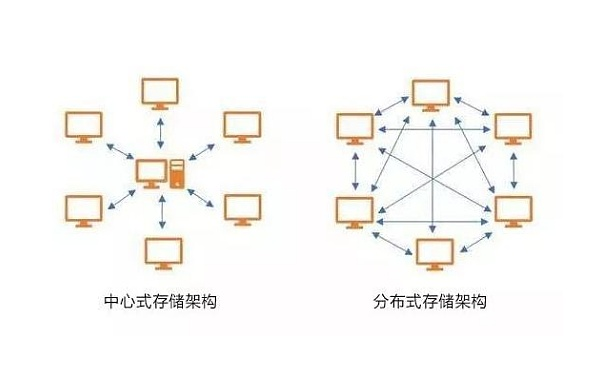
分布式存储与计算概念
分布式存储将数据分散存储于多节点,保障高可用与扩展性;分布式计算将任务拆解至多节点并行处理,提升效率,二者结合实现海量数据高效处理,具备容错、弹性伸缩能力,支撑云计算、
分布式存储与计算概念详解
分布式存储核心概念
分布式存储是一种通过多台服务器协同工作,将数据分散存储在多个节点上的技术体系,其核心目标是解决传统集中式存储的容量瓶颈、性能限制和单点故障问题,以下是分布式存储的关键特征:
| 特性 | 说明 |
|---|---|
| 数据分片 | 将大数据集拆分为多个小块(Shard),分布存储在不同节点 |
| 冗余备份 | 通过副本机制(如3副本)或纠删码技术实现数据容错 |
| 扩展性 | 支持横向扩展(Scale-out),通过增加节点提升存储容量和吞吐量 |
| 负载均衡 | 采用哈希算法或一致性哈希实现数据均匀分布 |
| 元数据管理 | 通过元数据服务器(如HDFS NameNode)记录数据块位置和映射关系 |
核心技术组件:
- 分片策略:范围分片(按数据范围划分)、哈希分片(按关键字哈希值划分)、目录分片(按目录结构划分)
- 副本机制:同步复制(强一致性)、异步复制(高可用性)、链式复制(多跳传输)
- 一致性协议:Paxos、Raft协议保障元数据一致性,CAP定理下的权衡(一致性/可用性/分区容忍)
- 存储引擎:HDFS(块存储)、Ceph(对象存储)、Cassandra(NoSQL存储)
分布式计算核心概念
分布式计算指将大规模计算任务分解为多个子任务,分配到多个计算节点并行处理的技术体系,其核心价值在于突破单节点算力限制,实现超大规模数据处理。

| 核心要素 | 技术实现 |
|---|---|
| 任务分解 | MapReduce模型(分-map-结果合并)、Spark RDD(弹性分布式数据集) |
| 资源调度 | YARN资源管理器、Kubernetes容器调度、Mesos分布式资源管理 |
| 通信机制 | RPC远程过程调用、消息队列(Kafka)、共享内存(Redis) |
| 容错机制 | 任务重试、Checkpoint检查点、数据流水线快照 |
| 计算模式 | 批处理(Hadoop)、流处理(Flink)、图计算(Pregel)、内存计算(Spark) |
典型计算框架对比:
| 框架 | 计算模型 | 延迟 | 吞吐量 | 适用场景 |
|---|---|---|---|---|
| Hadoop MapReduce | 离线批处理 | 高 | 高 | ETL、日志分析 |
| Spark | 内存迭代计算 | 中 | 极高 | 机器学习、交互式分析 |
| Flink | 流式实时计算 | 低 | 中 | 实时监控、事件驱动处理 |
| Dask | 并行计算库 | 中 | 可扩展 | 科学计算、Python生态 |
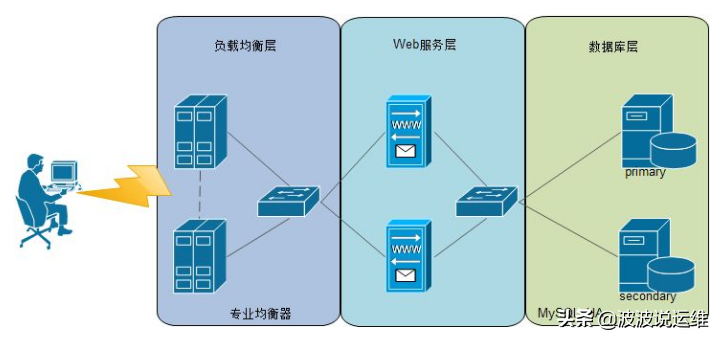
分布式存储与计算的协同架构
现代大数据系统通常采用存储与计算分离的架构,通过以下方式实现协同:
graph TD
A[客户端] --> B{元数据服务}
B --> C[存储节点集群]
B --> D[计算任务调度器]
D --> E[计算节点集群]
C -.-> E
E --> F[网络存储]- 元数据层:管理文件目录结构和数据块位置(如HDFS NameNode)
- 存储层:提供数据读写服务(如HDFS DataNode、Ceph OSD)
- 计算层:执行分布式计算任务(如YARN NodeManager、Spark Executor)
- 网络层:通过高速网络(RDMA、Infiniband)实现节点间数据传输
关键技术挑战与解决方案
| 挑战类型 | 具体问题 | 解决方案 |
|---|---|---|
| 数据一致性 | 分布式环境下的数据同步延迟 | 采用Raft协议实现线性一致性,引入版本向量(Version Vector)冲突检测 |
| 故障恢复 | 节点宕机导致任务中断 | 实施心跳检测机制,采用Speculative Task推测执行实现任务重试 |
| 性能瓶颈 | 网络IO成为系统吞吐量限制 | 使用RDMA远程直接内存访问,部署Alluxio内存缓存层优化数据访问 |
| 安全隔离 | 多租户环境下的资源争用 | 引入cgroups进行资源配额管理,使用Kerberos认证和Ranger权限控制 |
| 成本优化 | 存储计算资源利用率不均衡 | 采用Serverless架构动态扩缩容,使用Spot Instance降低空闲资源浪费 |
典型应用场景对比
| 场景类型 | 存储需求 | 计算需求 | 推荐方案组合 |
|---|---|---|---|
| 大数据分析 | PB级冷数据存储 | 批量处理、SQL查询 | HDFS+Hive/Impala |
| 实时数仓 | TB级热数据存储 | 低延迟OLAP分析 | Kafka+ClickHouse/Druid |
| AI训练 | 高吞吐小文件存储 | GPU加速分布式训练 | Ceph+Kubeflow/PyTorch Lightning |
| 边缘计算 | 断网容忍的数据持久化 | 轻量级实时处理 | IPFS+EdgeX Foundry |
| 混合云 | 跨云数据一致性 | 多云任务调度 | MinIO+Kubernetes联邦集群 |
技术演进趋势
- 存储计算融合:通过NVMe-oF实现存储卸载计算,SmartNIC卡进行近存储处理
- 新型存储介质:基于Apache Iceberg的湖仓一体架构,支持ACID事务的S3对象存储
- 计算范式革新:Serverless FaaS(函数即服务)与DAG(有向无环图)任务编排结合
- 能效优化:使用PUE(电源使用效率)指标优化数据中心能耗,采用潮汐存储技术
- 安全增强:基于零信任架构的TEE(可信执行环境)和全同态加密计算
FAQs:
Q1:分布式存储和分布式计算的主要区别是什么?
A:分布式存储侧重数据的可靠持久化和高效访问,解决”存哪里”的问题;分布式计算关注任务的并行执行和资源调度,解决”怎么算”的问题,存储更强调数据冗余和持久性,计算更注重任务分解和执行效率。
Q2:如何应对分布式系统中的网络分区故障?
A:可采用以下策略:
- 使用Raft/Paxos协议保证元数据一致性
- 部署多活数据中心实现跨地域容灾
- 配置熔断机制优先保证核心服务可用性
- 采用CRDT(冲突自由复制数据类型)处理