上一篇
分布式存储系统例子
分布式存储系统如HDFS、Ceph、MinIO,支持海量数据冗余存储与
Hadoop Distributed File System (HDFS)
架构原理
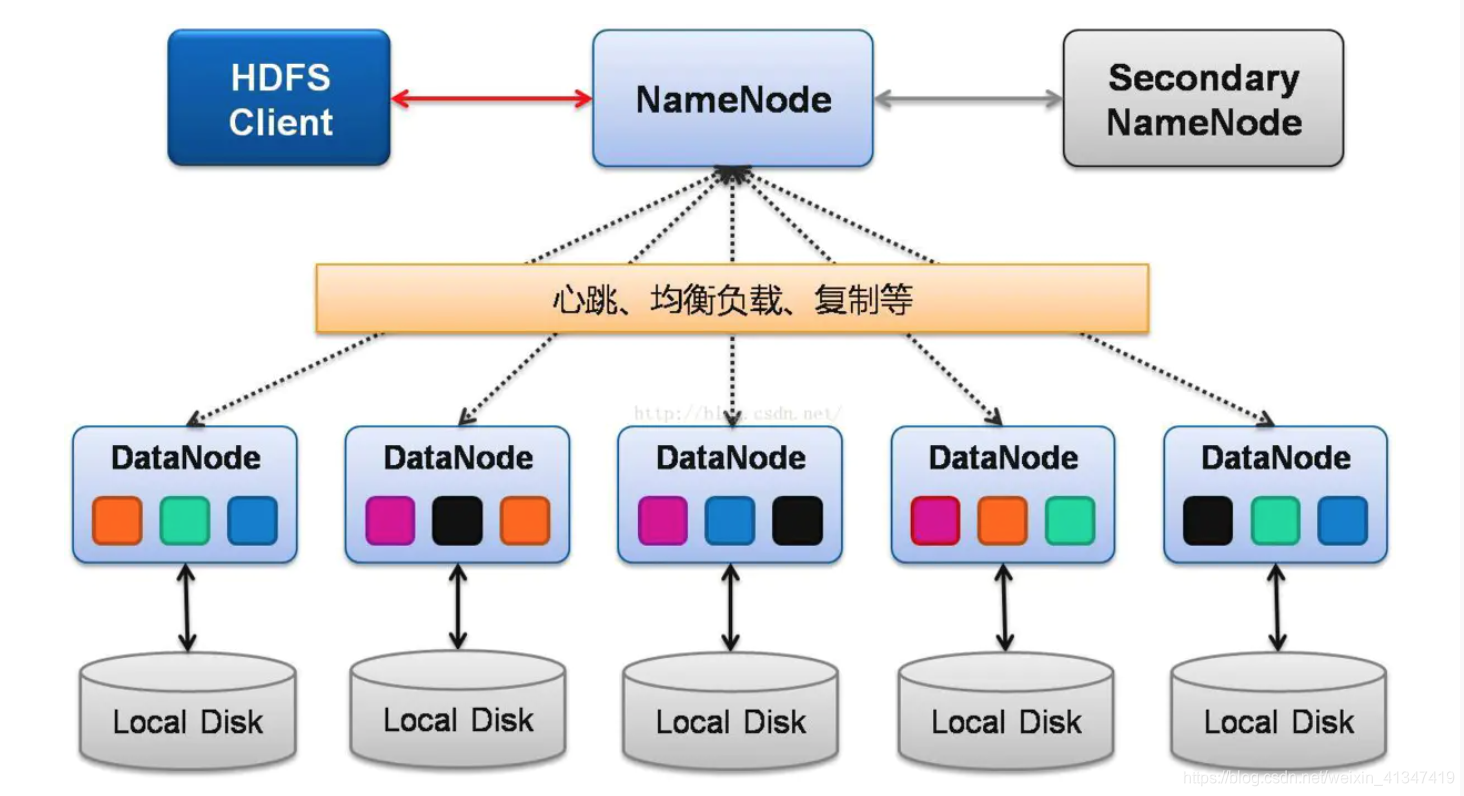
HDFS是Hadoop生态的核心组件,采用主从架构:
- NameNode:管理元数据(文件目录、块位置)
- DataNode:存储实际数据块(默认128MB)
- Secondary NameNode:辅助元数据检查点
核心技术
| 特性 | 实现方式 |
|———————|———————————-|
| 数据分块 | 将大文件切分为固定大小的数据块 |
| 副本机制 | 默认3副本,跨机架分布 |
| 容错处理 | 心跳检测机制监控DataNode状态 |
| 一致性模型 | 最终一致性(放宽强一致性要求) |
适用场景
大规模离线数据分析(如日志处理)、温冷数据存储,典型应用包括互联网公司用户行为分析、基因测序数据处理等。
Ceph分布式存储系统
创新设计
Ceph通过统一的存储架构实现对象、块和文件存储:
- CRUSH算法:基于概率的分布式数据布局算法,替代传统中心化元数据管理
- Monitor集群:维护集群状态映射表(Cluster Map)
- OSD守护进程:负责数据存储和恢复
- RADOS网关:提供RESTful接口兼容Swift/S3协议
性能优势
| 指标 | 传统方案对比 |
|———————|———————————|
| 扩展性 | 线性扩展至数千节点 |
| 硬件利用率 | 支持异构存储介质混合部署 |
| 数据均衡速度 | 动态权重调整实现秒级再平衡 |
典型应用
OpenStack云平台默认存储后端、自动驾驶数据湖存储、运营商级PB级存储系统。

Amazon S3(对象存储)
架构特性
- 全局命名空间:所有桶(Bucket)共享扁平化命名空间
- 版本控制:支持对象版本管理和瞬态复制
- 存储级别:标准型、低频访问型、归档型分层存储
- 事件驱动:通过Lambda@Edge实现边缘计算触发
安全机制
| 层级 | 实现方式 |
|———————|———————————|
| 身份验证 | IAM角色/策略精细化权限控制 |
| 传输加密 | HTTPS强制+客户侧密钥加密 |
| 数据持久性 | 跨区域异步复制保障99.9999999%可用性 |
应用场景
海量非结构化数据存储(如社交媒体图片)、备份与恢复、静态网站托管、大数据分析源数据池。
Google Spanner(分布式数据库)
核心突破
- TrueTime API:结合GPS卫星和原子钟实现全球纳秒级时间同步
- Paxos协议变种:多副本共识算法保障强一致性
- Schema灵活:支持关系模型与NoSQL灵活模式混合
性能参数
| 指标 | 数值表现 |
|———————|——————————|
| 读写延迟 | <10ms(99百分位) |
| 事务吞吐量 | 百万级QPS(分区水平扩展) |
| 数据一致性 | 全球范围强一致性保证 |
应用案例
谷歌内部广告系统元数据管理、金融级交易记录存储、跨国企业ERP系统核心数据库。
MinIO(云原生对象存储)
轻量化设计
- 100%兼容S3 API:支持AWS签名v4认证
- 零配置部署:单二进制文件启动即用
- Kubernetes原生:通过Operator实现弹性扩缩容
- GPU加速:支持NVIDIA卸载加速数据压缩
性能对比
| 测试场景 | MinIO v4.0 vs Ceph v17 |
|———————|—————————-|
| 单节点吞吐量 | 12.6GB/s vs 8.2GB/s |
| 对象延迟(P99) | 4.2ms vs 6.8ms |
| 存储密度 | 42TB/柜 vs 36TB/柜 |
适用领域
容器化环境持久化存储、AI训练数据集管理、边缘计算节点本地缓存。
技术选型对比表
| 系统类型 | 最佳适用场景 | 关键限制 |
|---|---|---|
| HDFS | 大数据批处理 | 低延迟需求场景不适用 |
| Ceph | 混合存储(块/对象/文件) | 初始配置复杂度较高 |
| S3 | 互联网级对象存储 | 存储成本随访问频率波动 |
| Spanner | 全球分布式事务处理 | 需深度依赖Google云生态 |
| MinIO | 私有云S3兼容存储 | 生产环境需强化监控告警体系 |
FAQs
Q1:如何判断业务是否需要分布式存储?
A1:当出现以下特征时建议采用:
- 单节点存储容量接近上限(如PB级数据)
- 读写并发量超过千级QPS
- 需要跨地域灾备或多活架构
- 存在非结构化数据占比超过60%
- 业务要求7×24小时不间断服务
Q2:分布式存储系统常见性能瓶颈有哪些?
A2:主要瓶颈及优化方向:
| 瓶颈类型 | 典型表现 | 优化方案 |
|———————|—————————-|———————————-|
| 网络带宽 | 跨机房复制延迟增高 | 部署RDMA网络/压缩传输算法 |
| 元数据服务 | NameNode成为性能拐点 | 引入MDS多活或Raft协议改造 |
| 磁盘IO瓶颈 | 顺序写性能衰减 | 采用ZNSA(Zoned Named Space)SSD |
| 垃圾回收效率 | 删除对象残留过多 | 实施异步