上一篇
分布式存储试题
分布式存储通过数据分片、冗余备份、一致性协议、负载均衡及容错机制
分布式存储试题解析与核心知识点梳理
基础概念与核心目标
分布式存储系统通过将数据分散存储在多个节点上,实现数据的冗余备份、高可用性和可扩展性,其核心目标包括:
- 数据持久性:通过副本或纠删码保证数据不丢失。
- 高可用性:节点故障时仍能正常提供服务。
- 可扩展性:支持动态扩容和缩容。
- 性能优化:平衡读写延迟与吞吐量。
关键技术点:

- CAP定理:一致性(Consistency)、可用性(Availability)、分区容忍性(Partition Tolerance)三者不可兼得。
- 一致性模型:强一致性(如Raft协议)、最终一致性(如DNS系统)。
- 数据分片:哈希分片(Hash-based)或范围分片(Range-based)。
系统设计核心要点
设计分布式存储系统需考虑以下步骤:
| 设计阶段 | 关键任务 |
|——————–|—————————————————————————–|
| 需求分析 | 明确数据类型(结构化/非结构化)、访问模式(读多写少/读写均衡)、容灾等级。 |
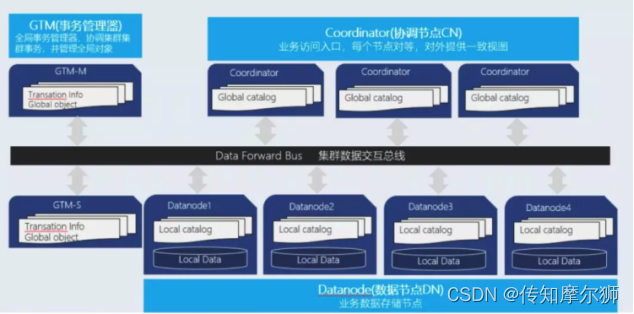
| 架构选择 | 选择集中式元数据(如HDFS)或去中心化元数据(如Ceph)。 |
| 数据分区 | 采用一致性哈希减少扩缩容时的数据迁移量。 |
| 副本策略 | 副本数(通常3个)与存储成本、容灾能力的权衡。 |
| 故障恢复 | 设计心跳检测机制(如Paxos选举)和自动数据重建流程。 |
典型架构对比:
| 系统名称 | 元数据管理 | 数据分片方式 | 适用场景 |
|————–|———————–|———————–|—————————|
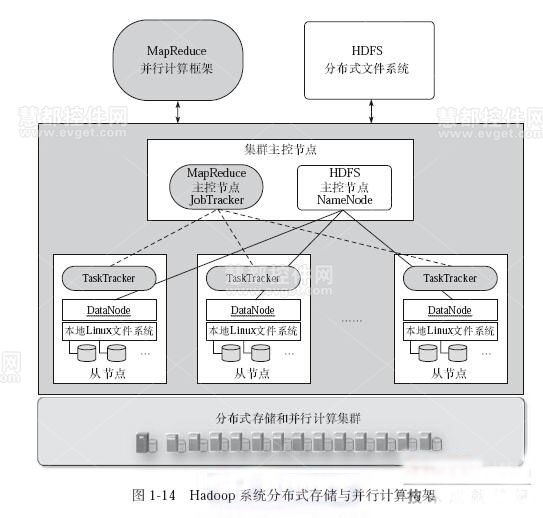
| HDFS | 单NameNode(中心化) | 固定大小块(128MB) | 大文件存储(如日志分析) |
| Ceph | CRUSH算法(去中心化) | 动态对象分片 | 块存储、对象存储混合场景 |
| MinIO | 分布式元数据(ETCD) | 按对象哈希分片 | 云原生对象存储(兼容S3) |
性能优化策略
- 数据分片优化:
- 热点数据预分片(如按用户ID哈希分片)。
- 动态负载均衡(如一致性哈希虚拟节点)。
- 缓存机制:
- 客户端本地缓存(LRU策略)。
- 边缘节点缓存(如CDN分层缓存)。
- 压缩与编码:
- 使用Zstandard压缩算法降低存储空间。
- 纠删码(如Reed-Solomon)替代副本(空间效率提升50%)。
- 热点数据处理:
- 分片内副本优先级调度(热点数据优先缓存)。
- 异步复制转同步复制(如支付宝交易数据双写机制)。
容错与一致性保障
- 副本机制:
- 主从副本(Master-Slave):强一致性但写入延迟高。
- 多主副本(Multi-Master):允许临时不一致,依赖冲突检测。
- 纠删码策略:
- RS编码(Reed-Solomon):k=10数据块+m=4校验块,容忍4节点故障。
- 对比副本存储:相同容灾能力下存储开销降低40%。
- 故障检测与恢复:
- 心跳超时阈值(如3秒未响应判定节点失效)。
- 数据重建流程:优先从存活副本复制,不足时触发纠删码恢复。
经典面试题解析
| 问题 | 考察点 | 解答要点 |
|---|---|---|
| CAP定理中如何选择? | 系统设计决策能力 | 根据业务场景取舍:金融交易选CP(牺牲分区容忍),社交平台选AP。 |
| 如何解决数据倾斜? | 分片策略与负载均衡 | 虚拟节点扩展、范围分片优化、动态迁移热数据。 |
| 如何保障强一致性? | 分布式协议理解 | 使用Raft/Paxos协议同步元数据,2PC解决事务一致性。 |
| 副本数设置为多少? | 成本与可靠性的权衡 | 3副本(成本适中,容忍单点故障),重要数据采用5副本。 |
| 扩容时如何保持服务? | 数据迁移与版本控制 | 逐步迁移数据、双写新旧节点、Victory CRB(变更不中断服务)。 |
真实案例分析
- HDFS写入流程:
- 客户端向NameNode请求上传。
- DataNode1~DataNode3创建块副本。
- ACK确认后返回成功,若任一副本失败则重试。
- Ceph CRUSH算法:
- 输入对象ID → 计算虚拟桶 → 映射到OSD节点。
- 优势:避免传统哈希分片导致的负载不均。
- MinIO S3兼容实现:
- 使用ETCD存储元数据,实现分布式锁。
- 客户端直连对象节点,绕过中心瓶颈。
FAQs
Q1:分布式存储与传统存储的核心区别是什么?
A1:分布式存储通过多节点协同实现以下特性:
- 扩展性:PB级存储容量,支持横向扩展。
- 高可用:副本或纠删码保证数据不丢失。
- 成本优化:使用廉价PC服务器,降低硬件投入。
- 地理分布:支持跨数据中心部署,实现异地容灾。
Q2:如何保障分布式存储中的数据一致性?
A2:根据业务需求选择以下方案:
- 强一致性:使用Raft协议同步元数据变更(如Ceph)。
- 最终一致性:允许短暂不一致,通过版本向量(Vector Clocks)解决冲突(如DynamoDB)。
- 混合策略:核心数据强一致,非核心数据最终一致(如支付宝账单与日志分离