上一篇
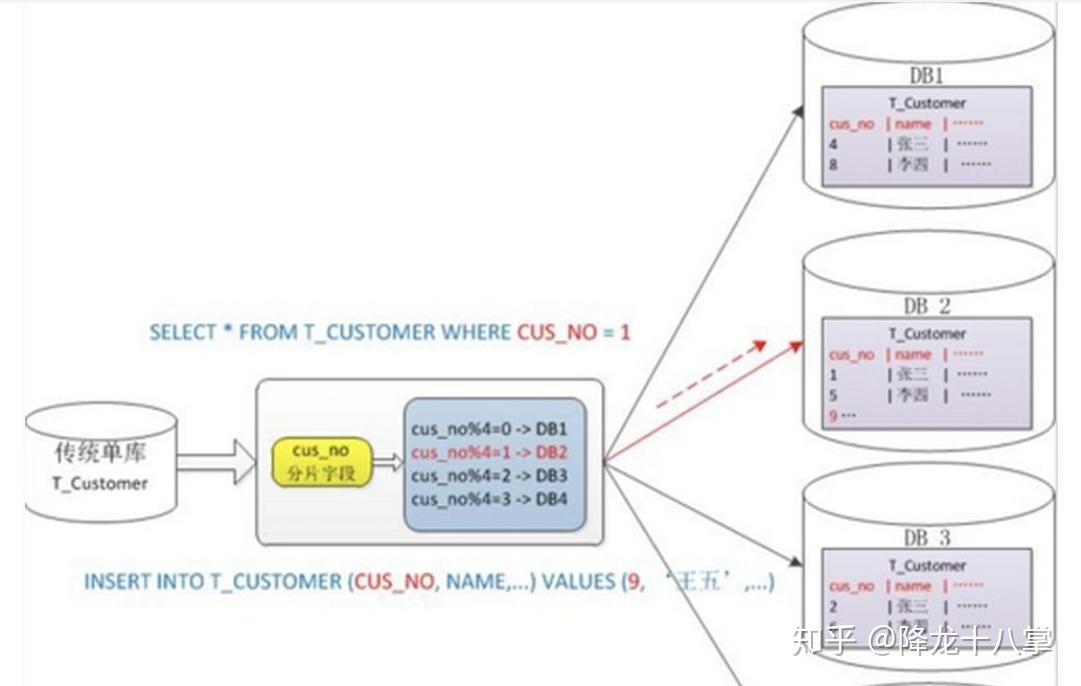
分布式存储多数据副本技术
分布式存储多数据副本技术通过在多节点保存 数据副本,提升系统可靠性与可用性,副本机制保障单点故障时数据不丢失,支持快速恢复,同时优化读写性能,平衡负载,确保服务连续性
分布式存储多数据副本技术详解
在分布式存储系统中,多数据副本技术是保障数据可靠性、可用性和持久性的核心技术之一,通过在不同节点或存储设备上保留多个数据副本,系统能够应对硬件故障、网络分区、人为误操作等问题,同时提升读写性能,以下从技术原理、实现方式、优缺点及应用场景等方面展开详细分析。
核心概念与目标
数据副本的定义
数据副本是指在分布式存储系统中,同一份数据被存储在多个物理节点或存储设备上的拷贝,副本的数量通常称为副本因子(Replication Factor),例如副本因子为3表示每份数据有3个副本。核心目标
- 容错性:单个节点故障时,其他副本可继续提供服务。
- 高可用性:通过负载均衡提升读写性能。
- 数据持久性:防止数据因硬件损坏或人为错误而丢失。
副本类型与分类
分布式存储系统的副本技术可根据存储策略和更新机制分为以下几类:
| 分类维度 | 类型 | 特点 |
|---|---|---|
| 存储完整性 | 全量副本(Full Replication) | 每个副本包含完整数据,适用于小规模数据或高一致性需求。 |
| 增量副本(Delta Replication) | 仅同步变化量(如日志、差异块),减少网络传输开销。 | |
| 纠删码(Erasure Coding) | 将数据分割为多个块并生成冗余校验码,存储效率高于全量副本(如HDFS采用)。 | |
| 更新一致性 | 同步副本(Sync Replication) | 写操作需等待所有副本确认,强一致性但延迟较高。 |
| 异步副本(Async Replication) | 写操作立即返回,副本后台同步,高可用但可能存在短暂数据不一致。 | |
| 角色分配 | 主从副本(Master-Slave) | 一个主副本负责写入,从副本跟随复制,适合读多写少场景。 |
| 多主副本(Multi-Master) | 所有副本均可接受写入,需解决冲突(如基于版本号或时间戳)。 |
一致性模型与冲突解决
在多副本环境中,一致性模型决定了数据在多个副本之间的同步规则,常见模型包括:

强一致性(Strong Consistency)
- 定义:所有副本在任何时刻均保持一致,读操作总能返回最新写入的数据。
- 实现方式:同步复制(如Paxos、Raft协议)、分布式事务(如两阶段提交)。
- 缺点:性能受限于最慢的副本节点,可能降低可用性。
最终一致性(Eventual Consistency)
- 定义:允许短时间内存在数据不一致,但最终通过同步机制达成一致。
- 适用场景:社交媒体、日志系统等对实时性要求不高的场景。
- 典型算法:DNS缓存、Amazon Dynamo的“矢量时钟”(Vector Clock)。
冲突解决机制
- 版本控制:为每个副本添加版本号,冲突时选择最新版本。
- 时间戳排序:以服务器时间为准,优先保留较新数据。
- 应用层合并:通过业务逻辑处理冲突(如购物车合并)。
容错与恢复机制
副本失效检测
- 心跳机制:定期发送心跳包检测节点存活状态。
- 数据校验:通过哈希值或校验码验证副本完整性。
数据恢复流程
- 主动修复:当检测到副本丢失时,自动从其他副本复制数据。
- 被动修复:由管理员手动触发恢复操作。
典型容错策略
| 策略 | 说明 |
|——————-|————————————————————————–|
| 主备切换 | 主副本故障时,从副本升级为主节点,适用于主从架构。 |
| Paxos/Raft协议 | 通过分布式选举保证副本组的一致性,适用于多主场景(如ZooKeeper、Etcd)。 |
| 纠删码重构 | 当部分副本损坏时,通过校验码计算恢复原始数据(如Ceph、Azure Blob Storage)。 |
性能优化与权衡
网络开销优化
- 差异同步:仅传输变化部分(如增量副本)。
- 压缩与去重:减少数据传输量(如ZFS文件系统的去重功能)。
一致性与可用性的平衡
- CAP定理:在分布式系统中,一致性(Consistency)、可用性(Availability)、分区容忍性(Partition Tolerance)最多同时满足两项。
- 实践选择:
- 金融系统:优先强一致性(如同步复制)。
- 互联网应用:优先高可用性(如异步复制+最终一致性)。
读写性能优化
- 读优化:通过负载均衡将读请求分散到多个副本。
- 写优化:采用批量写入或流水线复制减少延迟。
应用场景与案例
| 场景 | 技术选型 | 原因 |
|---|---|---|
| 云存储服务 | 纠删码 + 异步复制(如AWS S3) | 低成本存储,高可用性。 |
| 数据库复制 | 主从复制 + Paxos协议(如MySQL Group Replication) | 强一致性,支持高并发读写。 |
| 大数据分析 | 全量副本 + HDFS三副本机制 | 数据本地化处理,减少网络传输。 |
| 边缘计算 | 最终一致性 + 版本控制(如CDN缓存) | 低延迟访问,容忍短时间不一致。 |
FAQs
问题1:如何确定分布式存储系统的副本数量?
答:副本数量需综合考虑以下因素:
- 容错需求:至少需要
副本因子 > 最大可容忍故障节点数。 - 存储成本:更多副本意味着更高的硬件和网络开销。
- 性能要求:读密集型场景可通过增加副本提升并发能力。
建议默认副本因子为3(如HDFS、Cassandra),关键业务可配置为5或更高。
问题2:异步复制可能导致数据丢失吗?如何避免?
答:是的,异步复制存在窗口期(写入主副本后但未同步到从副本时),若主节点故障可能导致数据丢失,解决方案包括:
- 同步复制关键数据:对高优先级数据启用同步复制。
- WAL(Write-Ahead Log):在主节点本地持久化日志,确保故障后可恢复。
- 混合策略:结合同步和异步复制(如