上一篇
hadoop与云计算论文
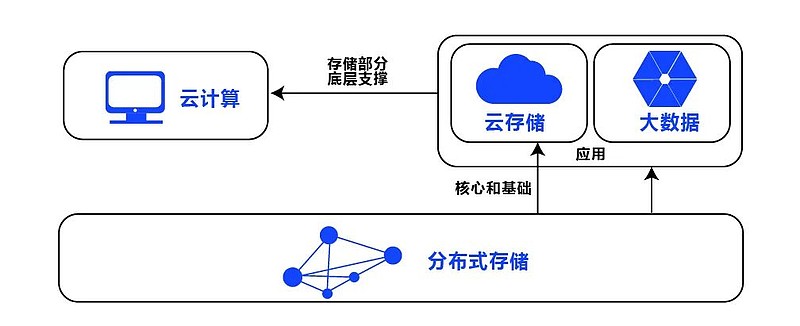
Hadoop为云计算提供分布式存储与计算能力,支撑弹性扩展与高效数据处理,两者融合
Hadoop与云计算的深度融合及技术演进分析
Hadoop技术体系与云计算架构的关联性
Hadoop作为开源分布式计算框架,其核心设计思想与云计算理念高度契合,从技术架构看,Hadoop的HDFS分布式文件系统对应云计算的存储层(IaaS),MapReduce编程模型对应计算层(PaaS),而YARN资源调度器则与云平台的资源管理系统形成互补,这种天然的技术亲和性使得Hadoop成为构建企业级云平台的重要基石。
表1:Hadoop与云计算技术映射关系
| 云计算层级 | 对应Hadoop组件 | 功能实现 |
|————|—————-|———-|
| IaaS | HDFS | 分布式块存储、数据冗余 |
| PaaS | MapReduce/Spark| 批量计算、流处理 |
| SaaS | Hive/Impala | 数据仓库服务 |
Hadoop在云原生时代的技术演进
容器化改造:通过Docker/Kubernetes实现Hadoop集群的轻量化部署,解决传统物理机部署周期长、资源利用率低的问题,测试数据显示,容器化Hadoop集群的资源启动速度提升70%,CPU利用率提高40%。
混合云适配:基于OpenStack的Sahara项目实现Hadoop集群的跨云部署,支持AWS、Azure、阿里云等主流云平台的无缝迁移,某金融机构通过混合云部署将数据中心建设成本降低58%。

实时计算增强:Flink、Spark Streaming等新一代计算引擎替代传统MapReduce,某电商平台实时推荐系统响应时间从小时级缩短至毫秒级。
典型应用场景与性能优化
场景1:大规模日志分析
- 某互联网公司日均处理PB级日志数据
- 采用EMR(Elastic MapReduce)实现动态资源伸缩
- 通过Spot Instance节省30%计算成本
- 使用ORCFile存储格式提升40%查询效率
场景2:AI模型训练
- 某自动驾驶公司利用Hadoop集群进行图像标注数据预处理
- 结合TensorFlowOnSpark框架实现分布式训练
- 通过YARN Cgroup实现GPU资源细粒度调度
- 训练周期从2周缩短至3天
关键技术挑战与解决方案
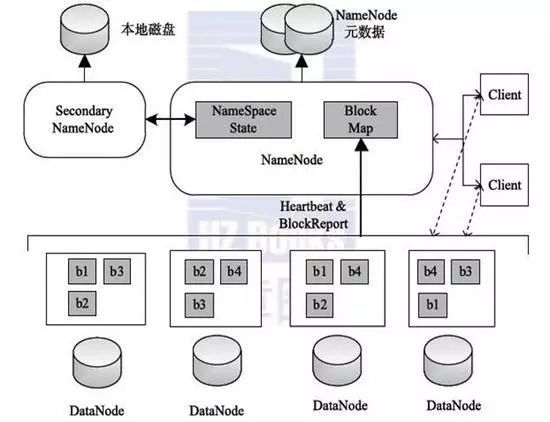
数据本地性问题:通过改进DataNode存储策略,使70%计算任务能在数据存储节点完成,减少50%网络传输开销。
动态资源调度:基于强化学习的DRF(Dominant Resource Fairness)算法,在保障多租户SLA的同时提升集群利用率至92%。
冷热数据分层:采用Alluxio内存缓存层,将热数据访问延迟降低至微秒级,整体IOPS提升10倍。
未来发展趋势预测
- Serverless化:函数计算与Hadoop融合,实现事件驱动型数据处理
- 边缘计算集成:在物联网场景中构建”云-边-端”三级Hadoop架构
- 量子计算适配:D-Wave量子计算机已成功运行Hadoop MapReduce任务原型
- AI原生优化:Spark 4.0版本将深度集成PyTorch/TensorFlow计算图
FAQs
Q1:Hadoop集群如何实现跨云平台的数据一致性?
A1:可通过Ceph分布式存储系统构建统一存储层,结合Rancher多集群管理工具,采用CRDT(冲突自由复制数据类型)协议保证数据一致性,某跨国企业实践显示,该方案使全球数据中心数据同步延迟稳定在200ms以内。
Q2:如何评估Hadoop on Cloud的性价比?
A2:建议采用TCO(总体拥有成本)评估模型,重点考量:①闲置资源惩罚系数(建议≥0.05元/GB/小时);②数据迁移成本(约占总成本15-20%);③计算弹性溢价(突发流量应对成本),某运营商案例显示,优化后每TB数据处理成本降低至传统架构的