
上一篇
hadoop与大数据处理
Hadoop通过HDFS实现分布式存储,MapReduce支持并行计算,高效处理海量数据,具高扩展性与可靠性,广泛应用于数据分析
Hadoop与大数据处理:核心技术与应用场景解析
Hadoop与核心架构
Hadoop是由Apache基金会开发的开源分布式计算框架,专为大规模数据处理设计,其核心优势在于高可靠性、可扩展性和容错性,能够处理PB级甚至EB级数据,Hadoop生态系统包含多个关键组件,其中最核心的是HDFS(分布式文件系统)、MapReduce(分布式计算模型)和YARN(资源调度器)。
| 组件 | 功能 |
|---|---|
| HDFS | 分布式存储系统,将大文件拆分为块(Block),冗余存储确保数据可靠性。 |
| MapReduce | 分布式计算模型,通过“分而治之”处理海量数据,支持并行计算。 |
| YARN | 资源管理器,负责集群资源分配与任务调度,支持多种计算框架(如Spark)。 |
HDFS:分布式存储的基石
HDFS采用主从架构,包含一个NameNode(元数据管理)和多个DataNode(实际数据存储节点),其核心特性包括:
- 块存储:默认将数据拆分为128MB或256MB的块,分布存储在不同节点。
- 副本机制:每个数据块默认存储3份副本,分布在不同机架内,防止硬件故障导致的数据丢失。
- 一次写入,多次读取:优化读性能,适合流式数据处理。
示例:假设一个1GB的文件上传至HDFS,会被拆分为8个128MB的块(若块大小为128MB),每个块存储3份副本,分别位于不同节点。
MapReduce:分布式计算模型
MapReduce是一种编程模型,将任务分为两个阶段:
- Map阶段:输入数据被切片后,由多个Map任务并行处理,生成键值对。
- Reduce阶段:对Map输出的键值对进行聚合(如求和、计数),生成最终结果。
经典案例:WordCount(统计文本中单词出现次数)。

- Map任务:读取文本行,拆分单词并输出
<word, 1>。 - Reduce任务:汇总相同单词的值(如
<hello, [1,1,1]>→<hello, 3>)。
局限性:
- 磁盘IO密集型,依赖中间结果落地,性能低于内存计算框架(如Spark)。
- 仅支持线性数据流,复杂任务需多层MapReduce嵌套。
YARN:资源管理的革新
YARN将资源管理(CPU、内存)与任务调度分离,引入ResourceManager(全局资源协调)和NodeManager(节点资源监控),其优势包括:
- 多租户支持:同一集群可运行不同类型任务(如MapReduce、Spark作业)。
- 动态资源分配:根据任务需求灵活分配容器(Container),提升集群利用率。
Hadoop生态系统与工具链
Hadoop生态包含多种工具,覆盖数据存储、计算、管理等场景:
| 工具 | 功能 | 典型应用场景 |
|---|---|---|
| Pig | 数据流脚本语言,简化MapReduce编程。 | ETL(提取、转换、加载)任务。 |
| Hive | 数据仓库工具,支持SQL查询。 | 数据分析、报表生成。 |
| HBase | 分布式NoSQL数据库,支持随机读写。 | 实时数据查询(如日志分析)。 |
| Sqoop | 数据导入导出工具(如MySQL与HDFS间传输)。 | 数据迁移、同步。 |
| ZooKeeper | 分布式协调服务(如配置管理、命名服务)。 | 集群状态监控、Leader选举。 |
Hadoop在大数据处理中的优势与挑战
优势:
- 可扩展性:通过添加普通PC服务器即可扩展存储与计算能力。
- 成本低廉:依赖廉价硬件,避免单点故障。
- 生态成熟:工具链完善,社区活跃。
挑战:
- 性能瓶颈:MapReduce依赖磁盘IO,实时性差(延迟较高)。
- 运维复杂:需管理大量节点,配置调优难度高。
- 存储成本:HDFS存储冗余(3份副本)导致空间利用率较低。
Hadoop与Spark的对比
| 维度 | Hadoop(MapReduce) | Spark |
|---|---|---|
| 计算模型 | 磁盘IO密集型,依赖中间结果落地。 | 内存计算为主,支持迭代式算法。 |
| 性能 | 适合批量处理,延迟高。 | 延迟低,适合流处理、机器学习。 |
| 编程接口 | Java/Python,API相对底层。 | 支持Scala/Python/SQL,API更友好。 |
| 适用场景 | 离线批处理(如日志分析)。 | 实时分析、迭代计算(如深度学习)。 |
Hadoop的典型应用场景
互联网用户行为分析:
- 日志数据量巨大(TB~PB级),需通过MapReduce统计UV/PV、用户路径等。
- HDFS存储原始日志,Hive/Pig进行清洗与分析。
金融风控:
- 海量交易数据实时处理,结合HBase实现低延迟查询。
- Spark on YARN进行欺诈检测模型的训练与推理。
医疗健康:
- 基因测序数据存储于HDFS,通过MapReduce比对分析。
- Hive管理患者信息表,支持SQL查询。
物联网(IoT):
- 设备传感器数据流式写入Kafka,通过Spark Streaming实时处理。
- HDFS长期存储历史数据,供机器学习训练使用。
未来趋势与技术演进
- 混合部署:Hadoop与Spark、Flink等框架共存,互补短板。
- 云原生化:Hadoop逐渐迁移至云平台(如AWS EMR、Azure HDInsight),降低运维成本。
- AI融合:Hadoop存储为AI模型提供数据基础,Spark/Flink支持模型训练。
FAQs
Q1:Hadoop是否已过时?为什么企业仍在使用?
A1:Hadoop并未过时,但其定位发生变化,作为分布式存储(HDFS)和批处理(MapReduce)的基础设施,Hadoop仍广泛用于数据湖构建、冷数据存储等场景,企业选择Hadoop的原因包括:
- 成熟稳定,适合大规模数据长期存储。
- 生态工具链完整,与Hive、Spark等兼容。
- 云厂商提供托管服务(如EMR),降低运维复杂度。
Q2:如何判断业务场景应选择Hadoop还是Spark?
A2:需根据业务需求权衡:
- 选择Hadoop:离线批处理任务(如日志分析)、超大规模数据存储、对实时性要求低的场景。
- 选择Spark:需要内存计算的任务(如机器学习)、流处理(实时数据分析)、迭代式算法(如PageRank)。
- 混合使用:通过YARN整合资源,Hadoop负责存储与批处理,S
相关文章

大数据处理hadoop_SQL on Hadoop
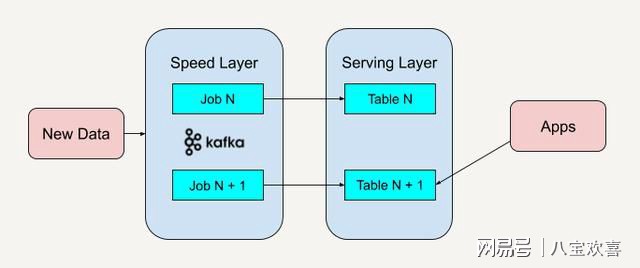
如何利用MapReduce和Hadoop实现高效的SQL on Hadoop处理?
服务器15核通常指的是拥有15个中央处理器(CPU)核心的服务器。在多核处理器架构中,一个物理处理器可以包含多个核心,每个核心能够独立执行任务。因此,一个15核的服务器意味着它有15个这样的处理单元,可以并行处理任务,提高计算效率和多任务处理能力。,这样的服务器配置适合于需要高计算性能和并行处理能力的应用场景,例如大数据处理、科学模拟、复杂的数据分析、以及为大量用户提供服务的高性能网站和应用等。

安装hadoop_SQL on Hadoop

Hadoop Jar包冲突影响Flink作业提交?如何解决MapReduce与Hadoop的兼容性问题?

kafka 存储hadoop_SQL on Hadoop
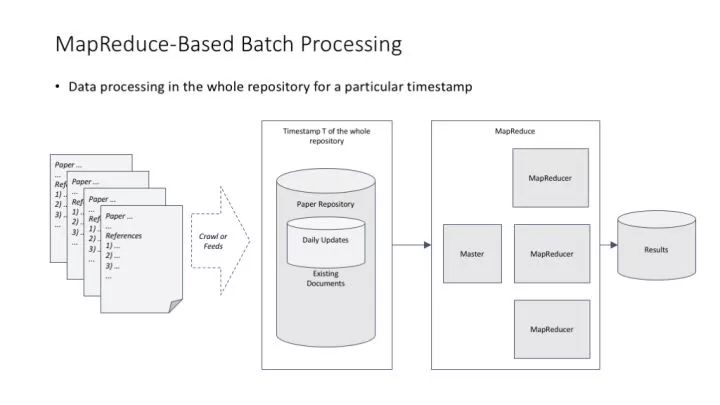
MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。

hadoop的hdfs对大数据处理的意义







