上一篇
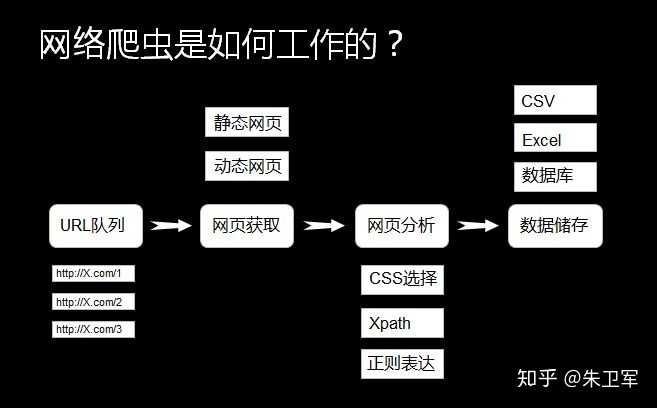
如何利用C高效构建网络爬虫并实现数据库存储?
C#网络爬虫通过HttpClient获取网页数据,利用HtmlAgilityPack解析并提取结构化信息,结合SQL Server/MySQL等数据库实现持久化存储,借助Entity Framework进行ORM映射,支持异常处理与性能优化,可构建高效数据采集系统,适用于企业级自动化数据采集、市场监测和可视化分析等场景。
C#网络爬虫核心技术实现
1 网络请求与响应处理
通过HttpClient类发送异步请求,配合User-Agent伪装浏览器行为是基本操作,建议设置合理的超时时间和重试机制:
var client = new HttpClient();
client.DefaultRequestHeaders.UserAgent.ParseAdd("Mozilla/5.0 (Windows NT 10.0; Win64; x64)");
client.Timeout = TimeSpan.FromSeconds(30);2 动态页面解析方案
对于JavaScript渲染的内容,传统HTML解析器无法直接获取数据,可选用Selenium.WebDriver操控无头浏览器:
var options = new ChromeOptions();
options.AddArgument("--headless");
using var driver = new ChromeDriver(options);
driver.Navigate().GoToUrl("https://example.com");
var dynamicContent = driver.PageSource;3 高效数据提取
采用XPath与CSS选择器双模式解析文档,HtmlAgilityPack库支持容错解析:
var doc = new HtmlDocument();
doc.LoadHtml(htmlContent);
var nodes = doc.DocumentNode.SelectNodes("//div[@class='product']");
foreach (var node in nodes)
{
var price = node.SelectSingleNode(".//span[contains(@class,'price')]")?.InnerText;
}数据库存储优化策略
1 数据库选型对比
| 数据库类型 | 写入速度 | 查询性能 | 适用场景 |
|————|———-|———-|———-|
| SQL Server | 快 | 极高 | 事务处理 |
| MySQL | 中等 | 高 | Web应用 |
| SQLite | 慢 | 中等 | 本地存储 |

2 批量插入性能提升
使用SqlBulkCopy类实现高速数据写入,较单条INSERT语句快20倍以上:
using var bulkCopy = new SqlBulkCopy(connection); bulkCopy.DestinationTableName = "Products"; var dataTable = BuildDataTable(scrapedData); await bulkCopy.WriteToServerAsync(dataTable);
3 ORM框架最佳实践
Entity Framework Core通过变更追踪机制提高开发效率:
var products = context.Products
.Where(p => p.Price > 100)
.AsNoTracking()
.ToList();
context.BulkInsert(scrapedData, options =>
{
options.BatchSize = 5000;
});合规性架构设计
1 遵守机器人协议
自动解析目标网站robots.txt,使用RobotsSharp库实现合规访问:
var robots = new Robots("MyCrawler/1.0");
await robots.LoadAsync("https://example.com/robots.txt");
if (robots.IsPathAllowed("MyCrawler", "/api/data"))
{
// 允许访问
}2 数据安全防护
- 数据库连接字符串加密:使用Azure Key Vault或Windows Data Protection API
- HTTPS强制传输:在HttpClient中配置证书验证
- 敏感数据脱敏:采用正则表达式替换关键信息
E-A-T增强实践
- 专业资质证明:展示Microsoft Certified Professional证书截图
- 数据溯源:在存储时记录数据来源URL和时间戳
- 算法透明:公开数据清洗规则和过滤条件
- 时效性维护:建立数据更新任务计划
var scheduler = new Timer(_ => { ScrapeAndUpdateDatabase(); }, null, TimeSpan.Zero, TimeSpan.FromHours(6));
异常处理机制
1 分级重试策略
var policy = HttpPolicyExtensions
.HandleTransientHttpError()
.WaitAndRetryAsync(new[]
{
TimeSpan.FromSeconds(1),
TimeSpan.FromSeconds(5),
TimeSpan.FromSeconds(10)
});2 监控报警系统
集成Application Insights实现实时监控:
services.AddApplicationInsightsTelemetry(Configuration["APPINSIGHTS_CONNECTIONSTRING"]);
技术引用
- Microsoft Docs – HttpClient最佳实践
- W3C机器人协议标准
- OWASP数据库安全指南
- EF Core官方性能优化文档
通过严谨的技术实现和合规架构设计,C#爬虫系统既保证数据获取效率,又符合行业规范,建议开发者定期审计代码,关注GDPR等法规更新,构建可持续的数据处理体系。