上一篇
分布式存储软件自动修复
分布式存储软件通过数据冗余与校验,自动检测并修复损坏数据,保障系统稳定性与
分布式存储软件自动修复技术详解
与核心概念
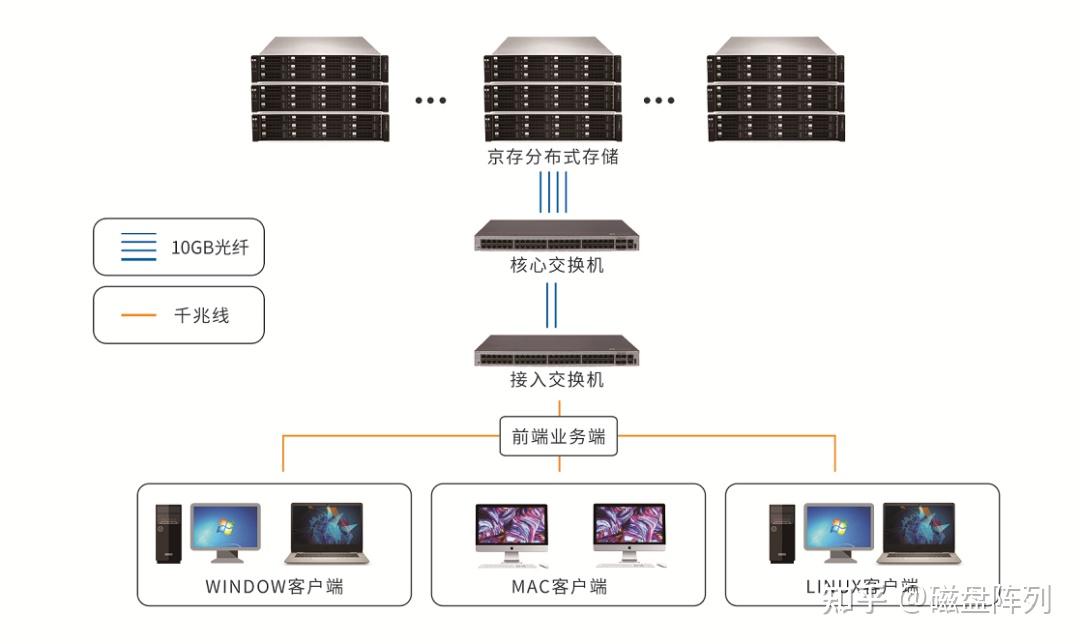
分布式存储系统通过将数据分散存储在多个节点上实现高可用性和扩展性,硬件故障、网络分区或软件异常等问题可能导致数据丢失或服务中断。自动修复(Auto-Healing)机制通过实时监测、故障诊断和数据恢复,保障系统在无人干预情况下维持数据完整性和服务连续性,其核心目标包括:
- 数据冗余重构:在节点失效时自动重建数据副本。
- 故障隔离与恢复:快速定位故障源并触发修复流程。
- 资源优化:平衡修复开销与系统性能。
自动修复的核心组件
| 组件 | 功能描述 |
|---|---|
| 健康监测模块 | 实时采集节点状态(CPU、内存、磁盘、网络)、数据完整性校验(如哈希值比对)。 |
| 故障检测引擎 | 基于阈值触发(如心跳超时)、异常模式识别(如RAID校验错误)判断故障。 |
| 决策与调度中心 | 根据策略选择修复方式(如副本重建、数据迁移),分配任务优先级。 |
| 数据修复执行器 | 调用存储协议(如擦除码、RAID)恢复数据,或从存活节点复制副本。 |
| 元数据管理 | 维护数据分布映射表、修复日志,支持版本回滚与冲突解决。 |
关键技术实现
数据冗余策略

- 副本机制:如HDFS的3副本策略,通过存活节点复制数据,修复时需计算最小带宽消耗路径(如最短传输树算法)。
- 纠删码(Erasure Coding):如Ceph的CRUSH算法,将数据编码为k+m块(如k=4数据块+m=2校验块),允许m个节点故障后仍可恢复数据,修复复杂度随m值指数级上升,需优化解码算法(如Gaussian Elimination加速)。
故障检测算法
- 主动心跳检测:节点定期发送心跳信号,超时则标记为失效(如ZooKeeper的会话机制)。
- 被动数据校验:通过SCSI校验、ECC内存纠错或应用层CRC检测数据错误,Ceph使用PG(Placement Group)的CRC校验发现数据块损坏。
自愈策略分类
| 策略类型 | 适用场景 | 优缺点 |
|—————-|————————————|——————————————|
| 立即修复 | 关键业务数据、低容忍度场景 | 修复及时但可能占用大量带宽和计算资源。 |
| 延迟修复 | 非核心数据、系统负载高峰时段 | 减少资源竞争,但延迟恢复可能扩大故障影响。|
| 分级修复 | 混合云环境或异构存储节点 | 根据节点性能动态调整修复优先级。 |修复带宽优化
- 拓扑感知调度:利用网络拓扑信息(如SDN控制器)选择最优数据传输路径,减少跨机架/数据中心流量。
- 增量修复:仅传输损坏数据块而非全量副本,例如通过rsync算法差异同步。
典型挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 修复风暴(Repair Storm) | 采用配额限制(如每秒修复任务数≤10%)、优先级队列(关键数据优先)缓解资源争抢。 |
| 脑裂问题(Split-Brain) | 引入仲裁机制(如Quorum EPAX),通过多数节点共识判断故障节点状态。 |
| 数据一致性风险 | 使用分布式事务(如两阶段提交协议)确保修复过程中的数据强一致性。 |
| 异构存储兼容性 | 抽象存储接口(如CSI标准),支持不同后端(SSD/HDD/对象存储)的统一修复。 |
主流系统实现对比
| 系统 | 冗余策略 | 故障检测方式 | 修复触发机制 | 特点 |
|---|---|---|---|---|
| Ceph | Replicated & EC | PG CRC校验 | Monitor自动检测并通知OSD | 支持动态扩缩容,修复策略灵活。 |
| HDFS | 3副本模型 | NameNode心跳监控 | DataNode失效后由NN触发复制 | 依赖中心化元数据管理,扩展性受限。 |
| Glacier | 纠删码 | 周期性数据审计 | 异步后台修复 | 冷存储优化,修复延迟容忍度高。 |
| MinIO | Erasure Code | SDK嵌入健康检查 | 客户端SDK触发EC重建 | 适合云原生场景,轻量化设计。 |
性能优化实践
- 并行修复:将大文件拆分为多个Shard,并行恢复不同分片(如MapReduce模型)。
- 缓存预热:预加载热门数据到内存,减少修复时IO瓶颈。
- 资源隔离:为修复任务设置独立资源池(如CPU cgroup、网络QoS队列)。
未来发展趋势
- AI驱动预测性修复:通过机器学习分析历史故障模式,提前迁移高风险数据(如TensorFlow的LSTM预测节点失效)。
- Serverless修复:利用FaaS框架动态调度修复任务,按实际消耗计费。
- 跨域协同修复:在混合云环境中实现多厂商存储设备的统一修复(如Kubernetes CSI插件)。
FAQs
Q1:自动修复是否会影响正常业务性能?
A1:可能产生以下影响:
- 带宽竞争:修复任务与用户读写共享网络资源,可通过限速(如Throttling)或专用通道(如RDMA)缓解。
- IO负载:并发修复多个数据块可能导致磁盘IO飙升,建议使用闲时修复或SSD缓存加速。
- 解决方案:优先级调度(如Kubernetes的PriorityClass)和资源配额控制是关键。
Q2:如何防止修复过程中出现二次故障?
A2:需构建多层防护机制:
- 修复前校验:确认源数据完整性(如校验和比对),避免从损坏节点复制数据。
- 断点续传:记录修复进度,网络中断后可从中断点继续。
- 版本回滚:若修复后数据不一致,通过事务日志回滚到修复前状态。
- 模拟测试:在非生产环境预演修复流程,验证策略