
上一篇
分布式数据库连接
分布式数据库连接通过透明访问、弹性扩展保障业务连续性,利用容错机制与智能调度实现高可用及负载均衡,同步优化数据一致性
分布式数据库连接技术详解
分布式数据库连接的核心概念
分布式数据库通过将数据分散存储在多个节点上实现高可用性和扩展性,其连接机制与传统单机数据库存在显著差异,连接过程需要解决网络延迟、数据分片定位、事务一致性等核心问题,典型的分布式数据库连接流程包含以下环节:
| 步骤 | 描述 | 关键技术 |
|---|---|---|
| 客户端初始化 | 建立初始TCP连接,完成认证 | SSL/TLS加密、Token认证 |
| 路由决策 | 根据分片规则定位目标节点 | 哈希分片、范围分片、目录服务 |
| 连接池分配 | 复用已有连接或创建新连接 | 智能连接池、动态扩容 |
| 请求转发 | SQL解析与执行计划生成 | 查询路由器、SQL改写引擎 |
| 结果聚合 | 合并多节点返回结果 | 流式处理、并行计算 |
分布式数据库连接架构类型
不同架构的连接实现方式存在本质区别:
客户端直连架构
- 特点:客户端直接连接各分片节点
- 优势:无单点瓶颈,天然负载均衡
- 挑战:需维护多节点连接,复杂事务处理困难
- 适用场景:简单读写分离、无跨分片事务场景
代理层架构
- 典型实现:MySQL Proxy、Cobar、MyCAT
- 工作机制:
- SQL解析:识别DML/DDL/事务语句
- 路由计算:基于分片键计算目标节点
- 协议转换:适配不同数据库方言
- 性能瓶颈:代理节点易成单点故障,需集群化部署
中间件架构
- 代表产品:ShardingSphere、Vitess
- 核心功能:
- 动态分片:支持范围/哈希/列表分片策略
- 事务管理:实现GTID追踪与XA事务协调
- 读写分离:基于负载的智能路由决策
- 优势:对应用透明,支持复杂查询下推
分布式事务连接处理
分布式事务连接需要解决CAP定理下的一致性难题,主流方案对比如下:
| 方案 | 一致性等级 | 性能开销 | 实现复杂度 | 典型应用 |
|---|---|---|---|---|
| 两阶段提交(2PC) | 强一致 | 高(锁资源) | 中 | 金融交易系统 |
| TCC(Try-Confirm-Cancel) | 最终一致 | 中 | 高 | 电商订单处理 |
| XA协议 | 强一致 | 极高 | 高 | 传统银行系统 |
| BASE理论 | 最终一致 | 低 | 低 | 社交媒体Feed流 |
2PC实现要点:

- 准备阶段:协调者冻结所有参与者资源
- 提交阶段:原子性提交所有节点
- 补偿机制:超时回滚未确认节点
TCC实现要点:
- Try阶段:预留资源并锁定
- Confirm阶段:正式提交事务
- Cancel阶段:释放预留资源
连接池优化策略
分布式场景下的连接池需要特殊优化:
动态连接池
- 基于LRU算法淘汰空闲连接
- 实时监控节点负载调整池大小
- 支持跨数据中心的连接复用
智能路由策略
- 地理位置感知:优先选择同区域节点
- 实时负载感知:通过心跳检测获取节点负载
- SQL特征感知:根据查询类型选择最优节点
超时控制机制
- 分级超时设置:
- 网络超时:500ms基础值
- 查询超时:根据数据量动态调整
- 事务超时:默认3秒可配置
- 熔断降级:自动切换到只读副本
典型分布式数据库连接特性
| 数据库 | 连接协议 | 事务支持 | 路由方式 | 最大连接数 |
|---|---|---|---|---|
| Cassandra | CQL原生 | 最终一致 | 哈希分片 | 3万+/节点 |
| CockroachDB | PostgreSQL兼容 | 强一致 | 范围分片 | 1千+/节点 |
| TiDB | MySQL协议 | 强一致 | 混合分片 | 5千+/节点 |
| Azure Cosmos DB | SQL/SDK | 多模型一致 | 分区键 | 弹性扩展 |
| Amazon Aurora | MySQL/PostgreSQL | 强一致 | 主从复制 | 150万+ |
连接故障处理机制
常见故障场景及应对策略:
网络分区
- 自动重试:指数退避算法(最多3次)
- 读写分离:只读请求切换到从节点
- Paxos协议:保证元数据一致性
节点宕机
- 快速故障转移:5秒内切换到备用节点
- 数据重建:基于Raft协议同步数据
- 连接迁移:客户端无感知切换
连接泄漏
- 心跳检测:每分钟验证连接有效性
- 资源回收:超过60秒空闲自动关闭
- 限流保护:单节点连接数阈值报警
性能优化实践
批量连接复用
- 采用Netty长连接复用机制
- 管道化处理多个请求
- 减少TCP三次握手开销
SQL路由优化
- 预编译路由缓存:命中率可达90%+
- 动态路由学习:根据执行计划调整策略
- 索引感知路由:优先选择有本地索引的节点
异步连接管理
- Reactor模式事件驱动
- 连接建立/释放异步化
- 内存池复用Buffer对象
FAQs
Q1:分布式数据库连接池参数如何设置?
A:关键参数包括:
- 最大连接数:按节点数×(CPU核数/2)估算
- 空闲超时:建议300-600秒
- 测试间隔:每分钟发送心跳包
- 初始化大小:节点数×2基准值
需结合压测结果调整,建议启用动态扩容功能。
Q2:跨数据中心的分布式数据库如何优化连接?
A:可采用:
- 地理感知路由:优先访问本地数据中心
- 异步复制优化:设置合理的复制延迟阈值
- 压缩传输:启用Wire Protocol压缩(如ZSTD)
- 连接预热:提前建立跨区备用
相关文章

CRT如何连接数据库命令,提出了一个具体而明确的问题,即如何使用CRT工具连接到数据库。它没有过多的修饰词,直接指向了主题,即CRT工具与数据库连接的命令或方法。同时,它也符合文章的主要内容,因为文章详细介绍了使用CRT连接数据库的步骤和命令。此外,这个标题也具有一定的吸引力,因为它是针对那些需要使用CRT连接数据库的用户,这些用户可能会对这个标题产生兴趣并进一步阅读文章。

程序连接数据库mysql数据库连接_数据库连接
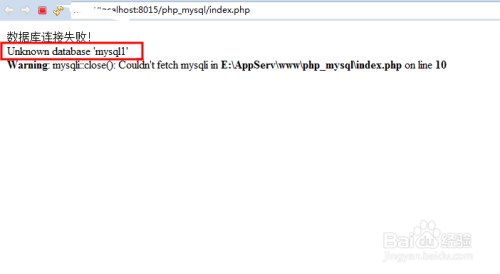
dw php连接mysql数据库连接_上传MySQL数据库连接驱动
如何正确配置并上传MySQL数据库连接驱动以确保MySQL数据库连接串的稳定连接?
客户端连接数据库连接服务器_数据库连接
pb 连接云服务器的数据库连接_数据库连接
客户端通过服务器连接数据库连接_数据库连接
dw怎么用mysql连接数据库连接_数据库连接








