上一篇
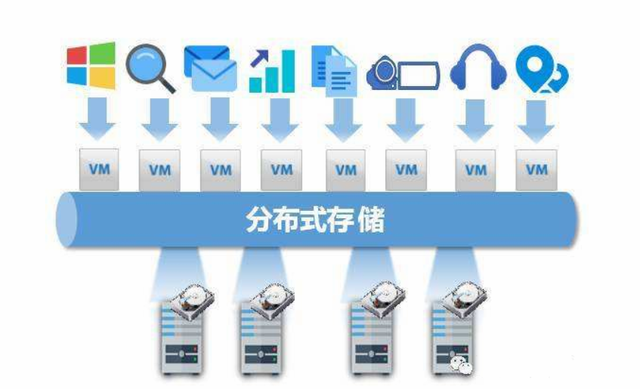
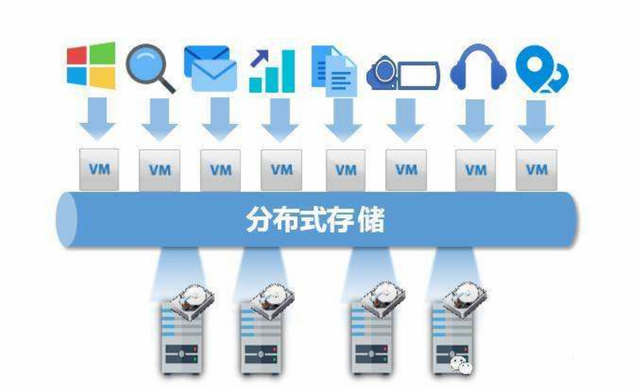
分布式文件存储的特点
分布式文件存储具备高扩展性、冗余备份、数据分片与并行处理能力,支持横向扩容,保障高可用与容错,通过元
分布式文件存储的特点详解
分布式文件存储是一种通过将数据分散存储在多个节点上,并通过网络进行协同管理的存储架构,它广泛应用于云计算、大数据、人工智能等领域,具有高可靠性、高扩展性和高性能等优势,以下从多个维度详细分析其核心特点:
高可靠性与容错性
分布式文件存储通过数据冗余和故障转移机制确保数据的持久性,即使部分节点发生故障,系统仍能正常运行。
| 特性 | 具体实现 | 示例 |
|---|---|---|
| 数据冗余 | 通过副本(如HDFS的3副本机制)或纠删码(Erasure Coding)实现数据冗余。 | HDFS默认保存3个副本,容忍单节点故障。 |
| 自动故障恢复 | 节点故障时,系统自动重建丢失的副本或数据块。 | Ceph集群中OSD故障后自动触发数据重分布。 |
| 心跳检测与健康检查 | 定期检测节点状态,快速隔离故障节点。 | GlusterFS通过心跳机制监控节点存活状态。 |
技术细节:
- 副本策略:简单易实现,但存储开销高(如3副本占用300%空间)。
- 纠删码:将数据分割为多个块并生成校验块,存储效率更高(如Reed-Solomon算法),但计算复杂度较高。
- CAP定理权衡:在分布式系统中,通常优先保证
AP(可用性与分区容错),牺牲一致性(最终一致)。
高扩展性
分布式文件存储支持动态扩展,能够轻松应对数据量增长和性能需求变化。

| 扩展类型 | 实现方式 | 优势 |
|---|---|---|
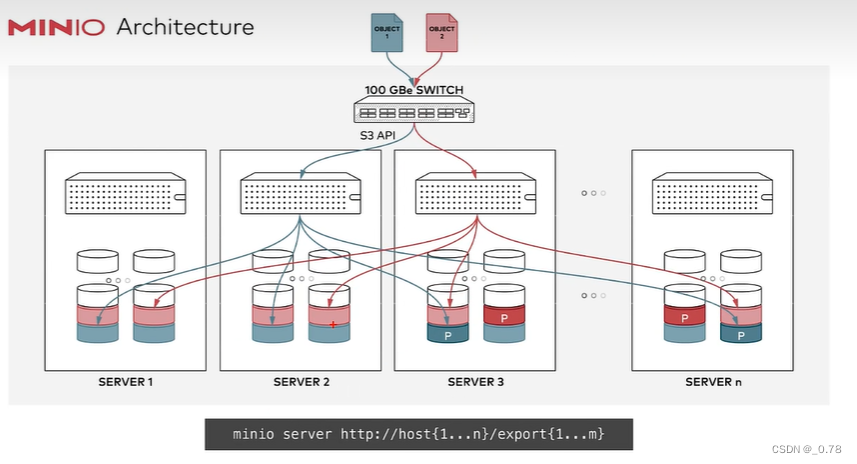
| 横向扩展(Scale-Out) | 通过增加普通节点提升容量和性能,无需停机。 | 成本低,扩展无上限(如Ceph、MinIO)。 |
| 纵向扩展(Scale-Up) | 升级单节点硬件(如磁盘、内存),但受限于物理极限。 | 适用于小规模或传统存储(如NAS)。 |
典型场景:
- EB级数据存储:互联网公司(如阿里云OSS、腾讯COS)通过数千节点构建存储集群。
- 弹性伸缩:Kubernetes中Persistent Volume自动绑定分布式存储,根据Pod需求动态扩容。
高性能与低延迟
通过数据分片、负载均衡和并行处理优化读写性能。
| 优化策略 | 技术实现 | 效果 |
|---|---|---|
| 数据分片(Sharding) | 将大文件拆分为固定大小的数据块(如HDFS的128MB块),分布到不同节点。 | 并行读写,提升吞吐量。 |
| 负载均衡 | 采用一致性哈希(如Ceph的CRUSH算法)或轮询策略分配数据。 | 避免热点节点,均衡IO压力。 |
| 缓存加速 | 使用LRU缓存(如Ceph的Cache Pool)或集成外部缓存系统(如Redis)。 | 降低读延迟,加速热点数据访问。 |
性能对比:
- 传统SAN/NAS:受限于单控制器性能,IOPS通常在万级。
- 分布式存储:通过并行处理可达到百万级IOPS(如Ceph在SSD集群中实测数据)。
成本优化
通过软硬件结合降低总体拥有成本(TCO)。
| 成本类型 | 优化手段 | 示例 |
|---|---|---|
| 硬件成本 | 使用廉价PC服务器(如JBOD)、混合存储介质(HDD+SSD)。 | 蚂蚁ZOLOT存储基于自研服务器降低成本。 |
| 运维成本 | 自动化运维(如Ceph的ceph-deploy工具)、故障自愈减少人工干预。 | GitHub使用MinIO降低运维复杂度。 |
| 能耗成本 | 冷热数据分层存储(如温数据存SSD,冷数据存HDD)或离线归档(如Glacier)。 | 阿里云OSS对低频访问数据收取更低费用。 |
数据管理与安全性
提供细粒度权限控制、加密和合规性支持。
| 功能 | 实现方式 | 标准/协议 |
|---|---|---|
| 权限管理 | 基于ACL(Access Control List)或RBAC(Role-Based Access Control)控制访问。 | NFS v4 ACL、S3策略。 |
| 数据加密 | 传输层加密(TLS/SSL)、静态加密(AES-256)。 | FIPS 140-2合规性。 |
| 审计与合规 | 记录操作日志(如Ceph的Ceph Log)并支持审计接口。 | GDPR、HIPAA合规性。 |
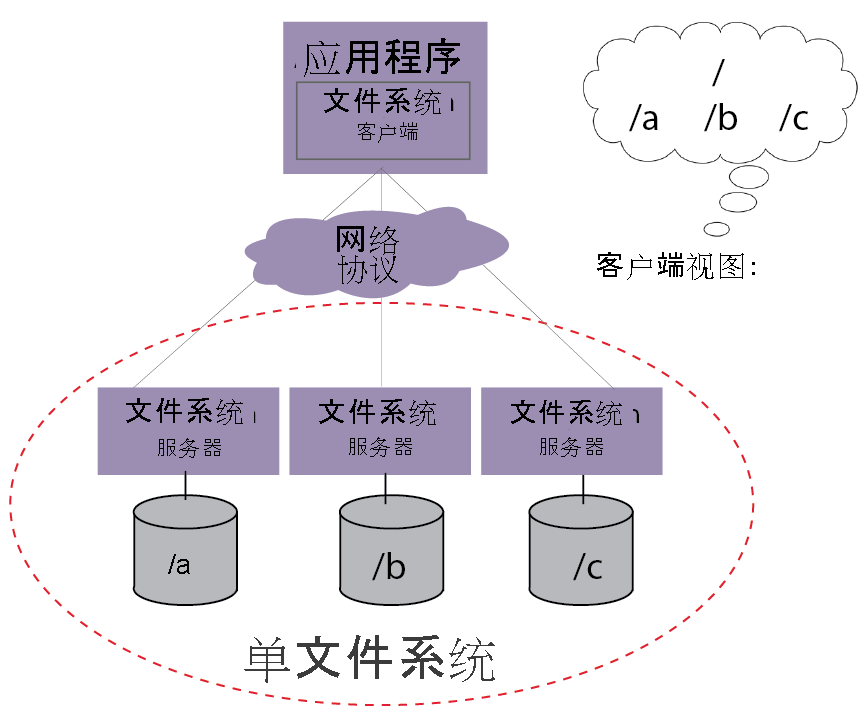
多协议支持与兼容性
支持主流文件协议,便于与传统系统集成。
| 协议类型 | 典型实现 | 应用场景 |
|---|---|---|
| POSIX兼容 | GlusterFS、BeeGFS支持标准POSIX接口。 | 科学计算、基因测序数据分析。 |
| S3兼容 | MinIO、Ceph Object Gateway模拟AWS S3 API。 | 云原生应用、备份归档。 |
| HDFS兼容 | Hadoop生态系统集成(如JuiceFS)。 | 大数据离线计算(MapReduce)。 |
FAQs
Q1:分布式文件存储适合哪些业务场景?
A1:
- 大规模数据存储:如互联网公司的用户日志、视频平台的内容库。
- 大数据分析:Hadoop、Spark等框架依赖分布式存储处理PB级数据。
- 云原生应用:容器化环境(如Kubernetes)需要动态扩展的存储后端。
- 灾备与归档:金融、医疗行业对数据长期保存和高可用性要求高。
Q2:分布式文件存储与对象存储有什么区别?
A2:
| 对比维度 | 分布式文件存储 | 对象存储 |
|——————–|——————————————–|——————————————|
| 数据模型 | 提供目录树结构,支持文件路径操作。 | 基于扁平化键值对(如S3的Object Key)。 |
| API接口 | 兼容POSIX、NFS等协议。 | 提供RESTful API(如S3的PUT/GET)。 |
| 适用场景 | 需要文件系统语义的场景(如媒体编辑)。 | 海量非结构化数据(如图片、日志)。 |
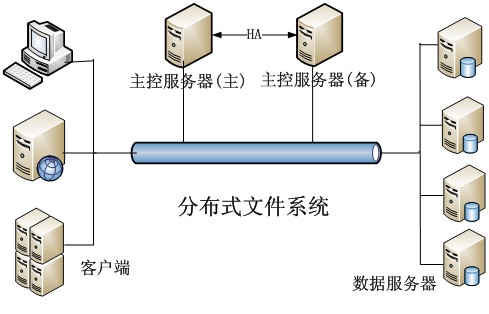
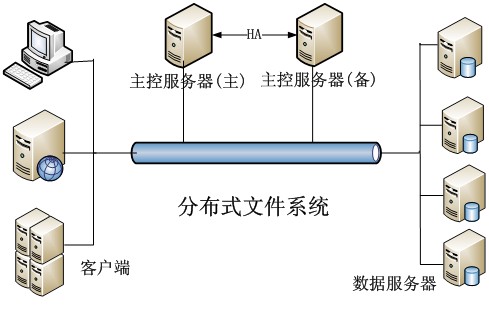
| 元数据管理 | 依赖独立元数据服务器(如Ceph Monitor)。 | 元数据内嵌在对象中,无集中式瓶颈。 |
分布式文件存储通过可靠性、扩展性、性能和成本的综合优化,成为现代数据基础设施的核心组件,其设计需平衡一致性、可用性和分区容错性(CAP定理),并根据业务需求选择适配的协议和冗余策略,随着硬件进步(如NVMe SSD、RDMA网络)和算法优化(如AI驱动的数据分布),分布式存储将进一步