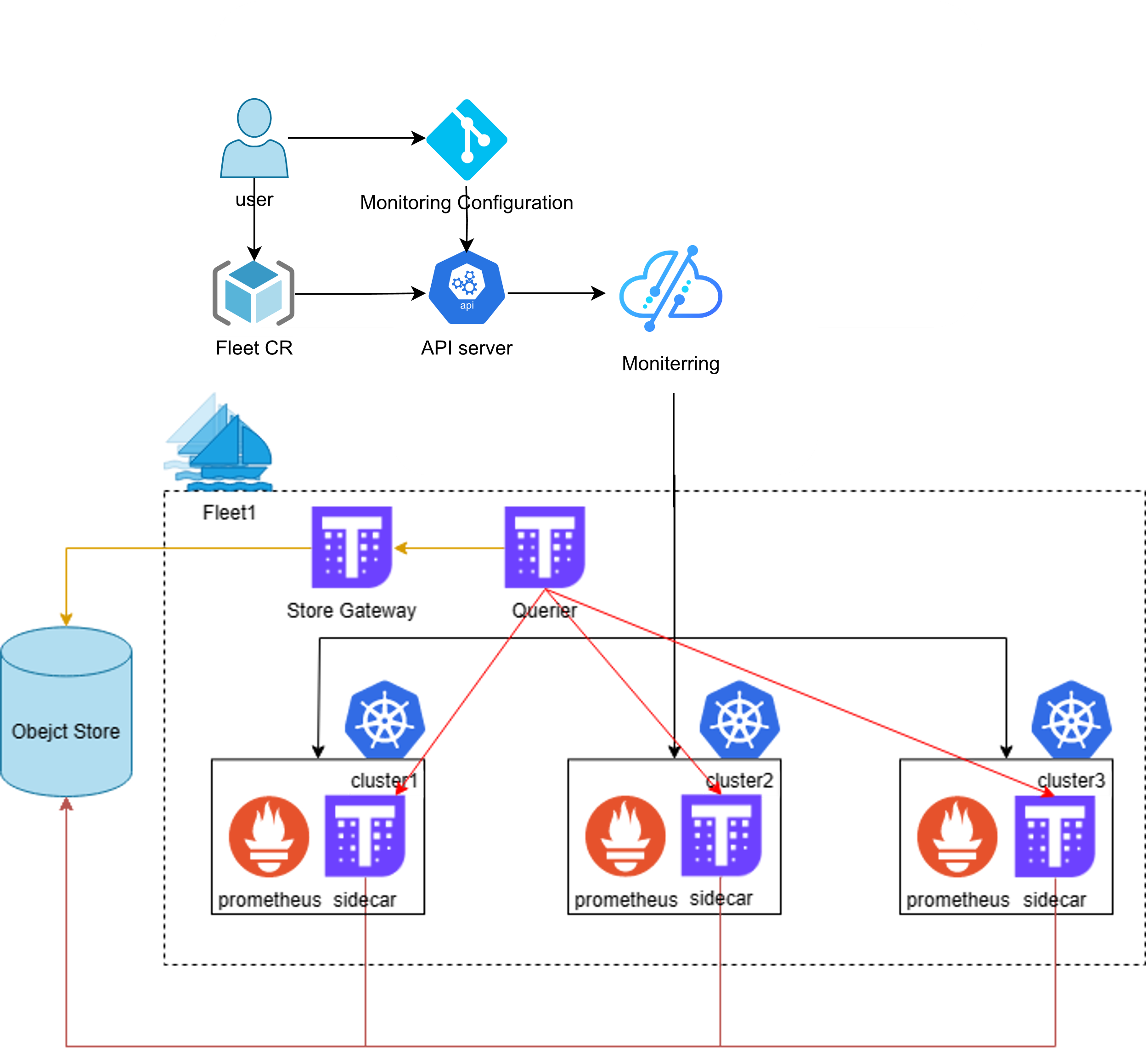
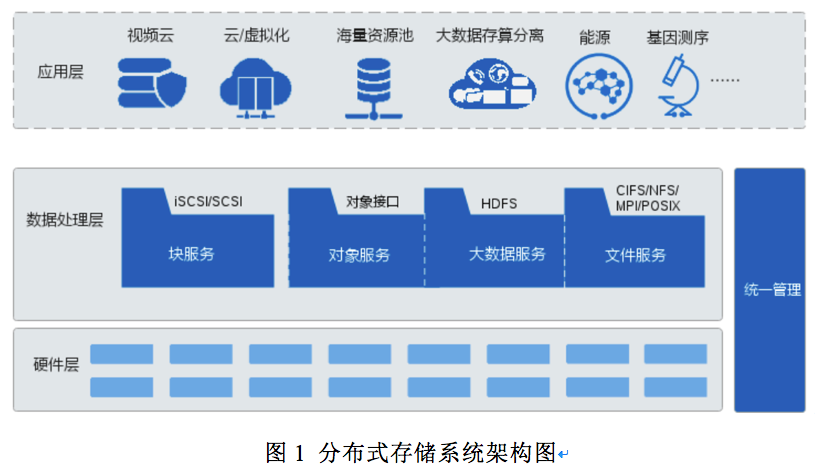
上一篇
分布式文件存储的相关文章推荐
分布式文件存储通过数据分片、冗余备份和一致性协议实现高可用与扩展性,适用于大数据、云计算场景,推荐阅读《Ceph分布式存储实战》《HDFS权威指南》等技术解析文章,或探讨CAP权衡、纠删码优化的实践案例,助你理解架构设计与性能
分布式文件存储相关文章推荐与深度解析
分布式文件存储是现代云计算、大数据和人工智能领域的核心技术之一,其设计目标在于解决海量数据存储的扩展性、可靠性和经济性问题,以下是精选的分布式文件存储领域核心文章推荐,涵盖理论基础、系统实现、优化技术及应用场景,并附详细解析与学习路径建议。
基础理论与核心概念
《The Google File System (GFS)》
- 作者:Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung
- 来源:SOSP’03(操作系统原理峰会)
- :
GFS是Google早期提出的分布式文件系统,针对大规模数据处理场景设计,文章详细阐述了GFS的三大核心目标:- 扩展性:通过分块存储(64MB默认块大小)和Master-Chunker架构支持PB级存储。
- 高可用性:采用数据块多副本(默认3份)和Master节点主备切换机制。
- 宽松一致性:引入”租约”机制,允许延迟写入以提高性能。
- 学习价值:理解分布式文件系统的底层设计逻辑,尤其是权衡一致性与性能的工程实践。
《HDFS: The Hadoop Distributed File System》
- 作者:Quoc Thai, Sanjay Ghemawat, etc.
- 来源:MSST’10(微软学术峰会)
- :
HDFS是Hadoop生态的基石,文章对比了HDFS与GFS的异同:
| 特性 | GFS | HDFS |
|—————|———————|——————–|
| 块大小 | 64MB | 128MB(可配置) |
| 元数据存储 | In-Memory + 持久化 | 基于XML的FsImage |
| 副本策略 | 固定3副本 | 机架感知策略 |
| 客户端交互 | 专用API | 兼容POSIX接口 | - 学习价值:掌握分布式文件系统在开源社区的实现差异,以及如何通过机架感知优化数据局部性。
系统实现与架构优化
《Ceph: A Scalable, High-Performance Distributed File System》
- 作者:Sage Weil, Wendy Wang, etc.
- 来源:SC’12(超级计算大会)
- :
Ceph通过CRUSH算法实现数据分布,其创新点包括:- 对象存储底层:将文件映射为PG(Placement Group)中的对象,支持RADOS抽象层。
- 无中心点设计:Monitor集群维护状态,Client直接与OSD(对象存储守护进程)交互。
- 动态扩展:支持自动重平衡,新增节点时仅需迁移少量数据。
- 学习价值:学习如何通过算法(CRUSH)和架构设计(无单点故障)实现高扩展性。
《SeaweedFS: A Simple and Efficient Distributed File System for Big Data》
- 作者:Christopher Antila, et al.
- 来源:GitHub开源项目文档(https://github.com/seaweedfs/seaweedfs)
- :
SeaweedFS针对低成本硬件优化,其特点包括:- 元数据分层:Volume层管理文件元数据,Master仅负责Volume分配。
- 数据分片策略:采用Consistent Hashing + 副本链(Replica Chain)减少跨节点写入。
- 轻量化部署:单节点可运行Master/Volume/Data节点,适合边缘计算场景。
- 学习价值:理解如何通过元数据分层和轻量化设计降低系统复杂度。
性能优化与前沿技术
《Scalable Meta-Data Management in MooseFS》
- 作者:Jacek Czarkowski, et al.
- 来源:EuroSys’13
- :
MooseFS通过分层元数据管理解决传统分布式文件系统的扩展瓶颈:- 主Master存储全局元数据(文件名→块ID映射)。
- ChunkServer本地维护块元数据(偏移量→数据地址)。
- 客户端缓存元数据,减少对Master的访问频率。
- 学习价值:掌握元数据分层缓存与分区管理的优化思路。
《Apollo: Efficient Multi-Cloud Storage via Block-Level Deduplication》
- 作者:Microsoft Research
- 来源:VLDB’21
- :
针对多云环境的存储成本问题,Apollo提出:- 块级去重:将数据切分为固定大小块(4KB),通过指纹哈希检测重复块。
- 跨云同步:利用LRU策略选择高频访问块优先同步至多个云服务商。
- 纠删码优化:根据网络带宽动态调整RS编码参数(如12/18 vs 8/16)。
- 学习价值:探索多云存储的成本优化与数据去重技术。
应用场景与案例分析
《Facebook’s Haystack: Lessons from a Petabyte-Scale Distributed File System》
- 作者:Facebook基础设施团队
- 来源:FB Engineering Blog(https://engineering.fb.com/2011/09/02/haystack/)
- :
Haystack为Facebook照片存储设计的系统,其独特设计包括:- 冷热点分离:高频访问文件(如热门图片)使用SSD缓存,冷数据存入HDD。
- 版本控制:通过Merkle Tree实现文件版本快速校验与回滚。
- 混合一致性:对用户上传文件采用强一致性,缩略图生成采用最终一致性。
- 学习价值:理解如何根据业务需求定制混合一致性模型。
《Building a Serverless Data Lake on AWS S3》
- 作者:AWS白皮书(https://aws.amazon.com/whitepapers/)
- :
通过S3构建无服务器数据湖的实践方案:
| 组件 | 功能 |
|—————|——————————|
| S3 | 存储原始数据与Parquet文件 |
| Glue | 数据目录与ETL调度 |
| Athena | 即时查询(Serverless SQL) |
| Step Functions| 工作流编排 | - 学习价值:学习云原生存储与Serverless计算的集成模式。
学习路径与资源推荐
| 阶段 | 推荐资源 |
|---|---|
| 基础入门 | 《分布式系统原理》(Andrew S. Tanenbaum)、MIT 6.824分布式系统课程 |
| 系统实践 | 开源项目源码(Ceph/HDFS/SeaweedFS)、Linux内核分布式存储模块分析 |
| 前沿追踪 | OSDI/FAST/NSDI等顶会论文、IEEE TSC期刊、云厂商技术白皮书(如阿里云EFS) |
FAQs
Q1:如何选择适合业务的分布式文件系统?
A1:需综合考虑以下因素:
- 数据特征:结构化数据可选HDFS,非结构化数据(如视频)适合Ceph。
- 一致性要求:金融交易需强一致性(如MooseFS),日志分析可接受最终一致性。
- 成本敏感度:公有云场景优先S3,私有部署可评估SeaweedFS或MinIO。
- 扩展性需求:EB级存储推荐Ceph,边缘计算场景可选轻量化系统(如SeaweedFS)。
Q2:学习分布式文件存储需要掌握哪些前置知识?
A2:建议分阶段学习:
- 基础:操作系统(文件系统、进程通信)、网络(TCP/IP、RPC)。
- 进阶:分布式算法(Paxos/Raft)、CAP定理、一致性哈希。
- 实践:熟悉Linux系统调用、Docker/K8s部署、Pro