
上一篇
如何高效实现存储图算法以优化数据处理性能?
存储图算法通过邻接矩阵、邻接表等数据结构实现图的表示与操作,权衡时间与空间复杂度,邻接矩阵适用于快速查询但空间消耗大,邻接表节省内存但访问效率较低,需根据图规模、应用场景及操作需求选择最优方案。
邻接矩阵(Adjacency Matrix)
邻接矩阵是图存储的最基础形式,适用于稠密图(边数接近顶点数平方的图),其原理是通过二维数组表示顶点之间的连接关系。
- 存储方式
假设图有n个顶点,矩阵为n×n的二维数组matrix,若顶点i和顶点j之间存在边,则matrix[i][j] = 1(无权图)或matrix[i][j] = 权重(带权图);否则为0或特殊标记。 - 优点
- 查询任意两顶点是否相邻的时间复杂度为
O(1)。 - 易于实现图遍历、最短路径算法(如 Floyd-Warshall)。
- 查询任意两顶点是否相邻的时间复杂度为
- 缺点
- 空间复杂度为
O(n²),对稀疏图浪费大量空间。 - 添加或删除顶点时效率低。
- 空间复杂度为
示例
以下为无向图的邻接矩阵表示:
A B C D
A 0 1 1 0
B 1 0 1 1
C 1 1 0 0
D 0 1 0 0 邻接表(Adjacency List)
邻接表通过链表或数组存储每个顶点的邻居,适用于稀疏图,是实际应用最广泛的方式。
- 存储方式
使用一个主数组(或哈希表)保存所有顶点,每个顶点对应一个链表(或动态数组),链表中存储该顶点的所有邻接顶点。 - 优点
- 空间复杂度为
O(n + m)(n为顶点数,m为边数),显著节省空间。 - 易于遍历某个顶点的所有邻居(如 BFS、DFS)。
- 空间复杂度为
- 缺点
- 查询两顶点是否相邻需遍历链表,最坏时间复杂度为
O(n)。 - 难以实现需要快速矩阵操作的算法。
- 查询两顶点是否相邻需遍历链表,最坏时间复杂度为
示例
无向图的邻接表表示:
A -> [B, C]
B -> [A, C, D]
C -> [A, B]
D -> [B] 压缩存储:CSR与CSC
针对超大规模图(如社交网络、网页链接图),邻接表可能因指针开销占用过多内存,此时可采用压缩稀疏行(Compressed Sparse Row, CSR)或压缩稀疏列(CSC)格式。
- CSR存储原理
offsets数组:记录每个顶点邻居的起始位置。neighbors数组:按顺序存储所有邻居顶点。weights数组(可选):存储边权重。
示例
顶点数n=4,边数为5的图:
offsets = [0, 2, 5, 7, 8]
neighbors = [1, 2, 0, 2, 3, 0, 1, 1] 边列表(Edge List)
边列表直接存储所有边的信息,通常用于需要按边遍历的场景(如 Kruskal 最小生成树算法)。
- 存储方式
使用数组保存每条边的三元组:[起点, 终点, 权重]。 - 优点
- 结构简单,适合动态增删边。
- 空间复杂度为
O(m)。
- 缺点
查询顶点邻居需遍历整个列表,效率低。
示例
带权图的边列表:
[(A, B, 3), (A, C, 2), (B, D, 5), (C, B, 1), (D, C, 4)] 十字链表(Orthogonal List)
十字链表是邻接表与逆邻接表的结合,专为有向图设计,可快速获取顶点的入边和出边。
- 存储方式
每个顶点包含两个链表:一个指向所有出边,另一个指向所有入边。 - 优点
- 支持高效查询顶点的入度和出度。
- 适用于需要反向遍历的算法(如 Kosaraju 强连通分量算法)。
- 缺点
实现复杂,空间开销较高。
如何选择存储方式?
- 稠密图 vs 稀疏图
邻接矩阵适合稠密图,邻接表或CSR适合稀疏图。 - 算法需求
- 频繁查询顶点间是否相邻:邻接矩阵。
- 频繁遍历邻居:邻接表或CSR。
- 内存限制
超大规模图优先考虑压缩格式(CSR/CSC)。
应用场景
- 社交网络分析:邻接表或CSR(查询用户好友)。
- 地图导航:邻接矩阵(计算最短路径)。
- 推荐系统:边列表(处理用户-物品关系)。
注意事项
- 若图需要频繁修改结构(如动态增删顶点),邻接表或边列表更灵活。
- 对无权图可省略权重字段以节省空间。
引用说明 参考《算法导论》(Thomas H. Cormen 等)、清华大学《数据结构(C语言版)》教材,并结合图数据库(如Neo4j)的存储实践总结。
相关文章

如何选择合适的大数据计算框架和大容量数据库以优化数据处理性能?
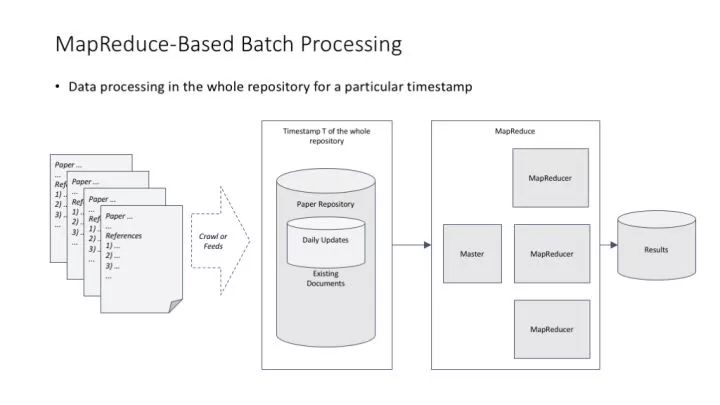
MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
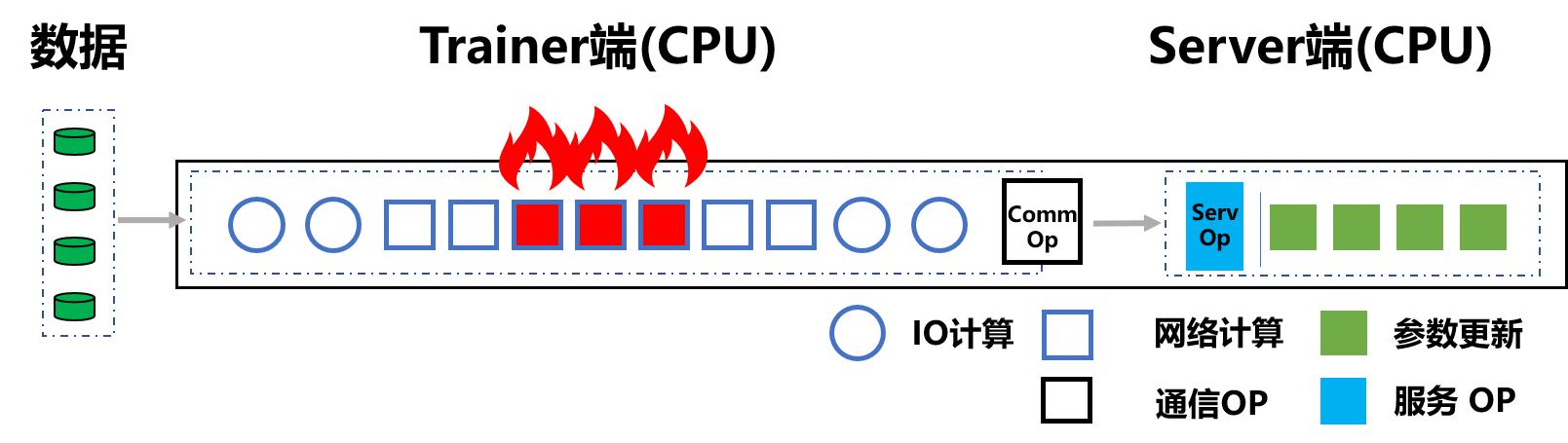
服务器15核通常指的是拥有15个中央处理器(CPU)核心的服务器。在多核处理器架构中,一个物理处理器可以包含多个核心,每个核心能够独立执行任务。因此,一个15核的服务器意味着它有15个这样的处理单元,可以并行处理任务,提高计算效率和多任务处理能力。,这样的服务器配置适合于需要高计算性能和并行处理能力的应用场景,例如大数据处理、科学模拟、复杂的数据分析、以及为大量用户提供服务的高性能网站和应用等。

如何有效结合MapReduce和分布式缓存(Redis)以优化数据处理性能?

如何将云控技术与MapReduce框架有效结合以优化数据处理性能?

如何高效配置阿里云服务器以优化大数据处理性能?
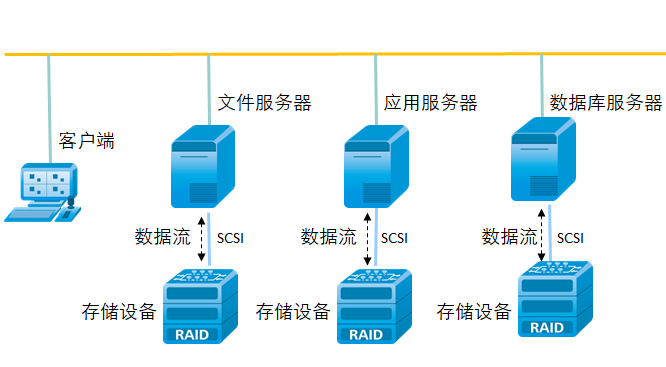
大数据服务器客户端如何优化数据处理性能?

离散傅里叶变换(DFT)是一种将时域信号转换为频域信号的数学工具。它通过傅里叶分析,把时间或空间域中的信号转换到频率域,从而揭示信号的频谱结构和变化规律。,基于DFT的原理和特性,我们可以提出以下疑问,,如何优化DFT算法以减少计算复杂度?,要学以致用,您可以思考如何运用快速傅里叶变换(FFT)算法来降低离散傅里叶变换(DFT)的计算复杂度。FFT通过递归分治策略将长序列分解为更短的序列,从而显著减少了乘法运算的次数。探索如何实现这一优化,并考虑其在实际信号处理中的应用。








