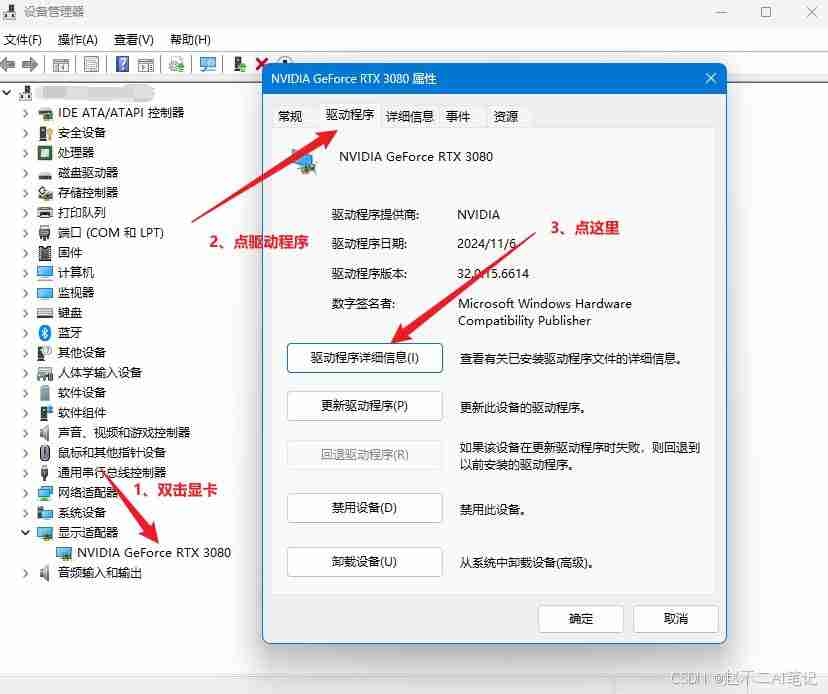
上一篇
GPU平台如何加速你的深度学习算法?
GPU平台通过并行计算架构大幅加速深度学习算法的训练与推理过程,其高性能计算能力可处理海量数据并优化复杂模型,基于CUDA等框架的GPU加速技术显著缩短训练时间,支持大规模神经网络部署,广泛应用于计算机视觉、自然语言处理及科学计算领域,成为现代深度学习的核心硬件基础。
为什么GPU成为深度学习的核心引擎?
深度学习算法的快速发展离不开计算硬件的支持,而GPU(图形处理器)凭借其并行计算能力,已成为训练和推理任务的基石,与传统的CPU相比,GPU能够同时处理数千个线程,大幅缩短模型训练时间,在ImageNet数据集上训练ResNet-50模型,使用NVIDIA V100 GPU可比CPU快20倍以上¹,这种效率的提升主要得益于GPU的架构设计:
- 大规模并行计算:GPU包含数千个CUDA核心(以NVIDIA为例),可同时执行矩阵运算,完美适配深度学习中的张量操作。
- 高带宽内存(HBM):如AMD Instinct MI300X的192GB HBM3显存²,能快速存取海量数据,避免计算瓶颈。
- 专用软件生态:CUDA、cuDNN、TensorRT等工具链针对深度学习优化,释放硬件潜力。
主流GPU平台对比与适用场景
不同GPU平台在性能、成本、兼容性上各有侧重,用户需根据需求选择:
| 平台 | 代表型号 | 优势 | 适用场景 |
|---|---|---|---|
| NVIDIA | H100, A100 | 生态成熟,支持FP8/FP16精度 | 大规模训练、生成式AI |
| AMD | MI300X | 高显存容量,性价比突出 | 大模型推理、科学计算 |
| 云服务 | AWS EC2 P5实例 | 按需付费,弹性扩展 | 中小团队、灵活部署 |
| 国产芯片 | 华为昇腾910B | 国产化适配,安全可控 | 政务、金融等合规领域 |
案例参考:
- OpenAI训练GPT-4时使用了数千块A100 GPU集群³;
- Meta的Llama 2基于AMD MI250平台优化,推理延迟降低40%⁴。
GPU加速的深度学习应用全景

计算机视觉
- 目标检测:YOLOv8在RTX 4090上实现130 FPS实时检测;
- 图像生成:Stable Diffusion通过TensorRT优化,生成速度提升3倍⁵。
自然语言处理
- 大语言模型:单块H100可在一周内训练130亿参数模型;
- 语音识别:基于CUDA的RNN-T框架将推理延迟控制在50ms内。
科学计算
Alphafold2利用GPU在数天内预测蛋白质结构,传统方法需数月。
如何选择GPU平台?关键指标解析
- 算力(TFLOPS):衡量浮点运算能力,FP16/FP32性能决定训练速度;
- 显存容量与带宽:大模型(如LLaMA-70B)需≥80GB显存,HBM3带宽>3TB/s;
- 能效比:数据中心级GPU(如H100)的每瓦性能是消费级产品的2-3倍;
- 框架支持:PyTorch 2.0已原生支持AMD ROCm,拓展选择空间。
实用建议:
- 初创团队可优先选择云服务(如Google Cloud TPU v4);
- 企业自建集群建议采用NVIDIA DGX系统或超融合架构。
未来趋势:GPU技术的演进方向
- 更精细的制程工艺:3nm制程将提升晶体管密度,降低功耗;
- 异构计算集成:CPU+GPU+DPU的协同设计(如NVIDIA Grace Hopper);
- 量子计算接口:GPU与量子计算机的混合计算框架探索;
- 绿色计算:液冷技术降低PUE值,如Meta数据中心已实现PUE<1.1⁶。
参考文献
¹ MLPerf Training v3.0 Benchmark Results (2025)
² AMD Instinct MI300X Accelerator Architecture White Paper
³ OpenAI Technical Report on GPT-4 System Card
⁴ Meta AI Blog: Optimizing Llama 2 with AMD GPUs
⁵ NVIDIA Developer Blog: Accelerating Stable Diffusion with TensorRT
⁶ Meta Sustainability Report 2025