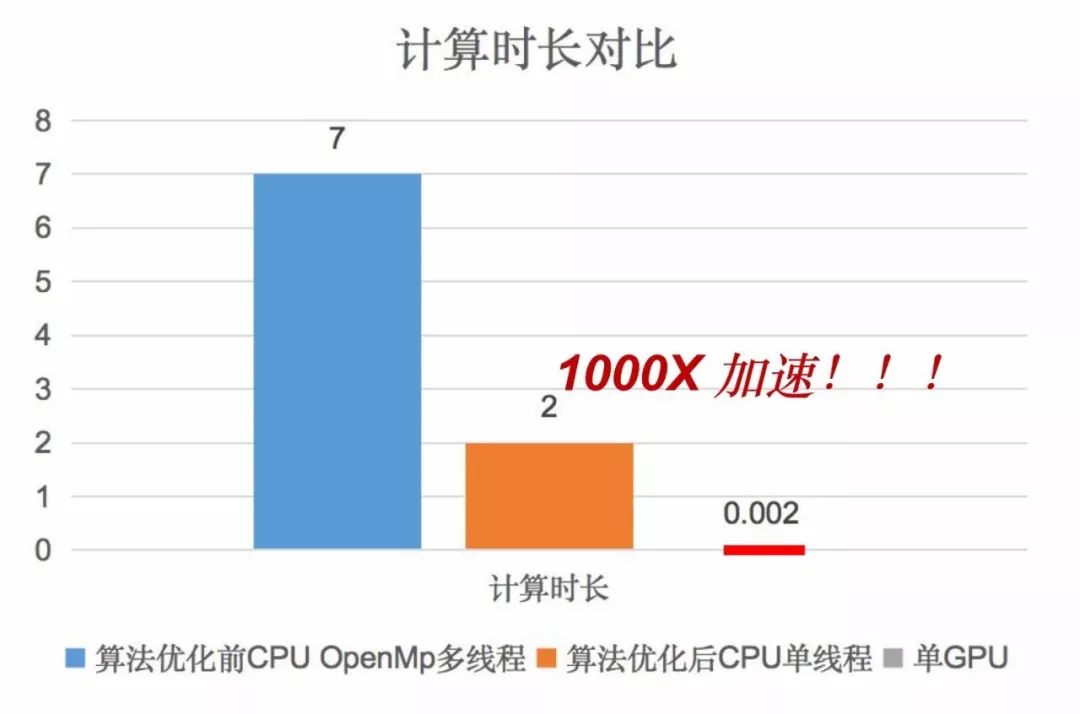
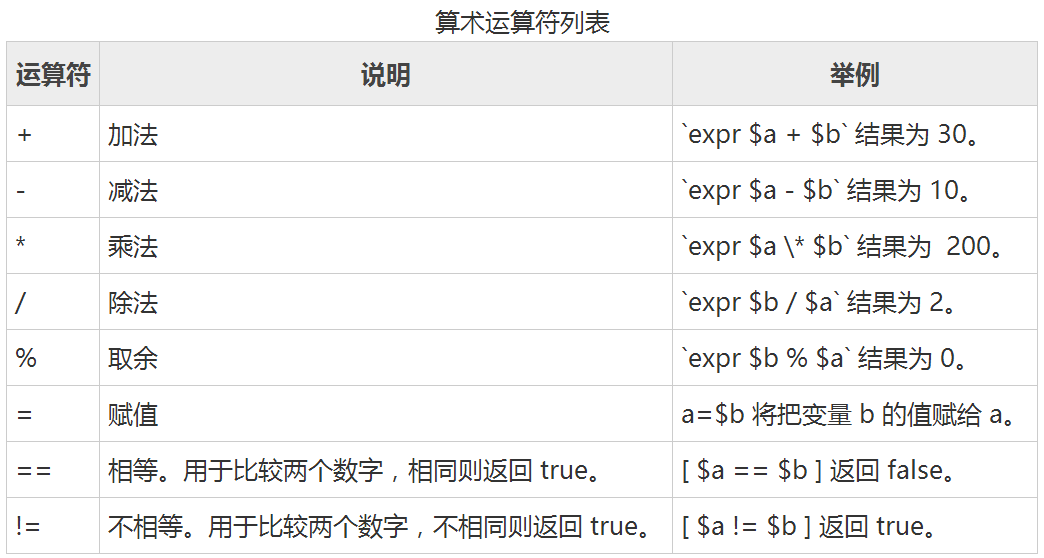
上一篇
如何利用GPU运算库API优化计算性能?
GPU运算库的API提供高效并行计算接口,支持开发者调用GPU硬件资源加速复杂运算,主流库如CUDA、OpenCL、ROCm等,通过预置函数简化并行编程,优化深度学习、科学模拟等场景性能,兼具跨平台兼容性及多语言绑定能力,降低异构计算开发门槛。
GPU运算库的API:开发者必备的高性能计算工具
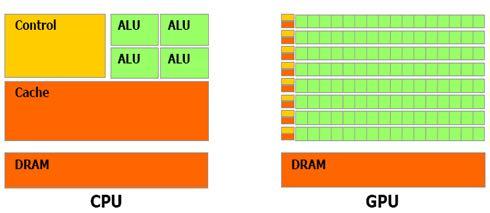
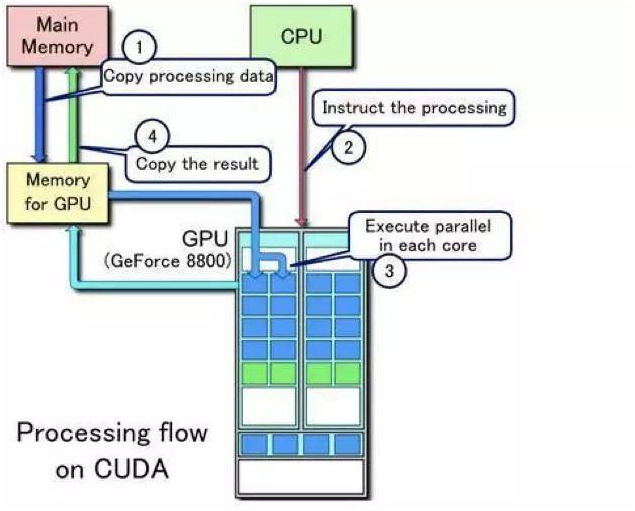
在人工智能、科学模拟、图形渲染等领域,GPU(图形处理器)凭借其并行计算能力已成为加速复杂任务的核心硬件,而要让GPU发挥最大性能,合理选择并利用GPU运算库的API是关键,本文将深入解析主流GPU运算库的API特性、适用场景及最佳实践,帮助开发者高效实现计算目标。

主流GPU运算库API概览
CUDA(Compute Unified Device Architecture)
- 开发者:NVIDIA
- 核心功能:专为NVIDIA GPU设计的并行计算平台,提供C/C++、Python等语言的API接口,支持从底层硬件到高级算法的全栈优化。
- 适用场景:深度学习训练与推理(如TensorFlow、PyTorch)、科学计算(如分子动力学模拟)、实时图形渲染。
- 核心API示例:
cudaMalloc(&device_ptr, size); // GPU内存分配 kernel<<<grid, block>>>(args); // 启动GPU内核函数
- 优势:生态完善、工具链齐全(Nsight、CUDA Toolkit)、性能优化文档丰富。
- 局限:仅支持NVIDIA GPU。
OpenCL(Open Computing Language)
- 开发者:Khronos Group
- 核心功能:跨平台、跨厂商的异构计算框架,支持CPU、GPU、FPGA等多种设备。
- 适用场景:跨硬件加速(如AMD/NVIDIA/Intel GPU)、嵌入式系统、移动端优化。
- 核心API示例:
clCreateBuffer(context, CL_MEM_READ_ONLY, size, NULL, &err); // 创建缓冲区 clEnqueueNDRangeKernel(queue, kernel, 2, NULL, global_size, local_size, 0, NULL, NULL); // 执行内核
- 优势:跨平台兼容性强、适合多设备协同计算。
- 局限:性能优化需针对不同硬件手动调优,生态工具较少。
ROCm(Radeon Open Compute)
- 开发者:AMD
- 核心功能:AMD GPU的开放计算平台,对标CUDA,支持HIP(Heterogeneous-Compute Interface for Portability)语言,可兼容部分CUDA代码。
- 适用场景:AMD GPU加速的深度学习(如PyTorch ROCm版)、高性能计算集群。
- 核心API示例:
hipMalloc(&d_ptr, size); // 内存分配(语法与CUDA高度相似) hipLaunchKernelGGL(kernel, grid, block, 0, 0, args); // 启动内核
- 优势:开源免费、支持CUDA代码迁移。
- 局限:仅支持AMD显卡,社区生态仍在发展中。
Vulkan Compute
- 开发者:Khronos Group
- 核心功能:基于Vulkan图形API的计算扩展,兼顾图形渲染与通用计算。
- 适用场景:游戏引擎(如Unreal Engine)、实时图形与计算混合负载(如光线追踪)。
- 核心API示例:
// Vulkan计算着色器示例(GLSL语法) #version 450 layout(local_size_x = 64) in; void main() { /* 并行计算逻辑 */ } - 优势:低开销、高控制粒度,适合需要极致性能的场景。
- 局限:学习曲线陡峭,需熟悉Vulkan管线机制。
如何选择合适的GPU运算库?
- 硬件兼容性
NVIDIA GPU优先选择CUDA,AMD GPU选择ROCm,跨平台需求考虑OpenCL。
- 开发效率
CUDA和ROCm提供高级封装库(如cuBLAS、rocBLAS),适合快速开发;Vulkan需从底层实现。
- 性能需求
超低延迟应用(如实时渲染)推荐Vulkan;科学计算优先CUDA/ROCm。
- 社区支持
CUDA拥有最丰富的教程和开源项目;OpenCL和Vulkan依赖厂商文档。
优化GPU代码的最佳实践
- 内存管理
- 使用锁页内存(Pinned Memory)减少数据传输延迟。
- 避免频繁的CPU-GPU内存拷贝,利用异步操作(如CUDA Streams)。
- 内核设计
- 调整线程块(Block)和网格(Grid)大小,最大化GPU占用率。
- 减少分支预测(Branch Divergence),尽量使用向量化计算。
- 工具链辅助
- 使用NVIDIA Nsight或AMD ROCgdb调试性能瓶颈。
- 通过CUDA Profiler或Radeon GPU Profiler分析内核执行时间。
未来趋势:GPU计算的演进方向
- AI驱动的自动优化:编译器(如LLVM)结合机器学习,自动生成最优GPU代码。
- 跨平台统一接口:SYCL(基于C++的异构编程标准)试图整合CUDA/OpenCL/Vulkan。
- 量子计算协同:GPU加速量子模拟算法(如Quantum Monte Carlo)。
引用说明参考以下权威来源:
- NVIDIA CUDA官方文档(https://docs.nvidia.com/cuda/)
- Khronos Group OpenCL规范(https://www.khronos.org/opencl/)
- AMD ROCm开发者指南(https://rocm.docs.amd.com/)
- Vulkan Compute白皮书(https://www.khronos.org/vulkan/)
- IEEE论文《GPU Computing: Programming and Applications》(2022)
通过合理选择GPU运算库API,开发者能够充分释放硬件潜力,应对从科学研究到商业产品的多样化需求,建议结合项目实际,灵活运用上述工具与优化策略。