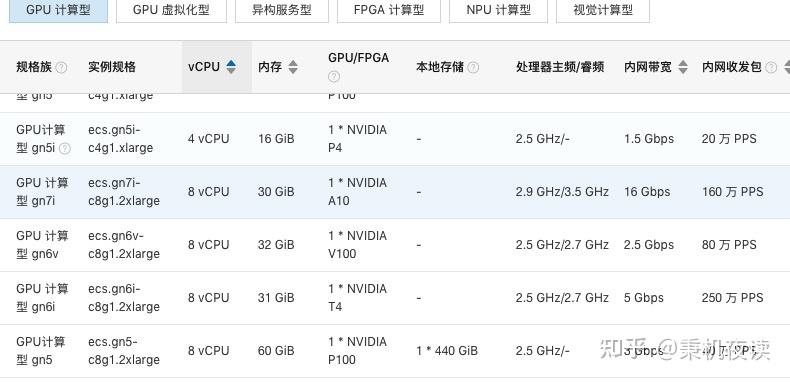
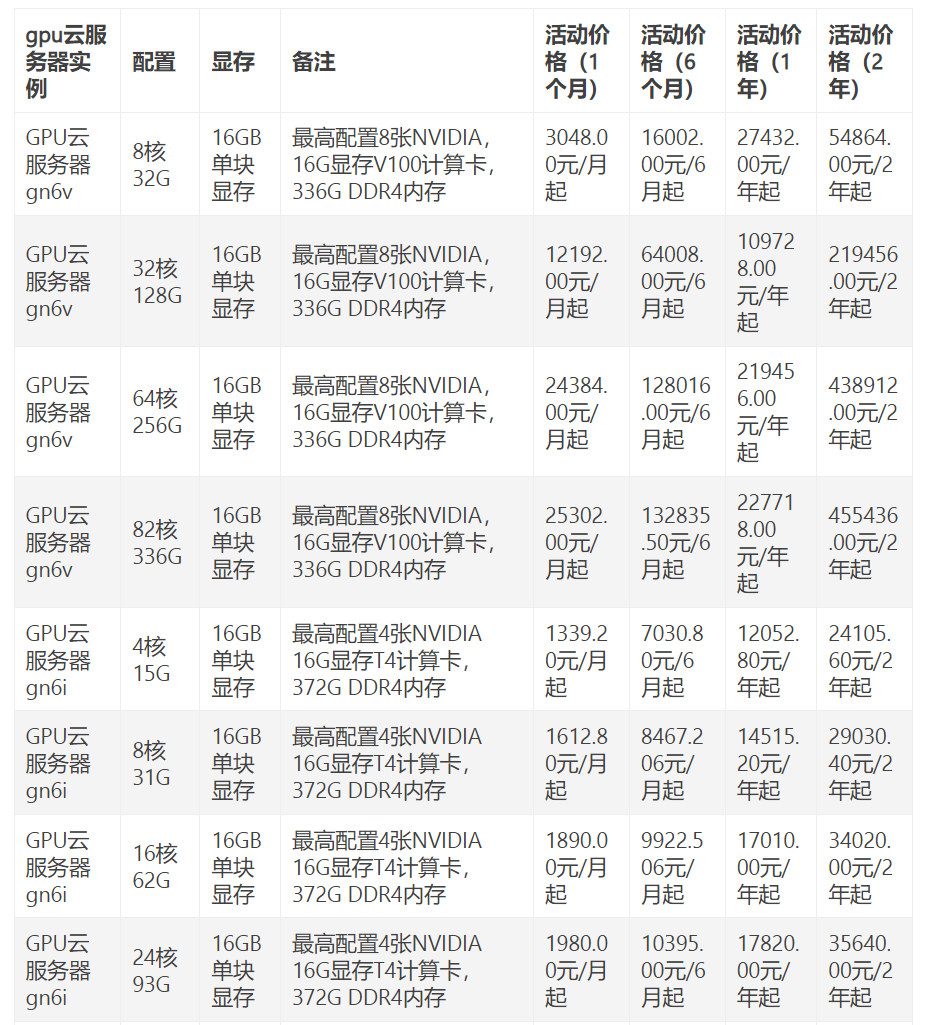
上一篇
GPU服务器实现如何提升你的项目计算效率?
GPU服务器通过集成高性能显卡和并行计算架构,为深度学习、科学模拟等场景提供加速支持,其设计需优化硬件配置、软件框架及散热系统,结合CUDA/OpenCL等并行计算平台,实现大规模数据高效处理,适用于训练复杂AI模型或实时图形渲染等计算密集型任务。
什么是GPU服务器?
GPU服务器是一种配备图形处理器(GPU)的高性能计算设备,专为处理大规模并行计算任务而设计,与传统的CPU服务器不同,GPU服务器通过多个核心同时执行任务,显著提升计算效率,尤其适用于人工智能、深度学习、科学模拟、图像渲染等对算力要求极高的场景。
GPU服务器的核心优势
- 并行计算能力
GPU拥有数千个计算核心,能够同时处理海量数据,特别适合矩阵运算、神经网络训练等任务,NVIDIA A100 GPU的单精度浮点算力可达19.5 TFLOPS,远超传统CPU。 - 加速复杂任务
在AI模型训练中,GPU可将耗时从数周缩短至几天甚至几小时,训练ResNet-50模型时,GPU的加速效率可达CPU的10倍以上。 - 高能效比
GPU在相同功耗下提供更高算力,降低数据中心运营成本,根据研究,GPU的每瓦性能比CPU高3-5倍。 - 灵活扩展性
GPU服务器支持多卡并行,通过NVLink或PCIe互联技术实现多GPU协同工作,满足超大规模计算需求。
GPU服务器的典型应用场景

- 人工智能与深度学习
训练大型语言模型(如GPT-4)、计算机视觉模型(如YOLO)等,依赖GPU的并行加速能力。 - 科学计算与仿真
气候模拟、基因测序、流体力学分析等科学领域,GPU可加速复杂方程的求解。 - 图形渲染与游戏开发
影视特效制作(如电影《阿凡达》)、3D建模、实时游戏引擎渲染均需GPU的高性能支持。 - 云计算与边缘计算
公有云服务商(如AWS、阿里云)提供GPU实例,满足企业弹性算力需求;边缘端GPU服务器支持实时推理(如自动驾驶)。
如何选择适合的GPU服务器?
- 明确需求与预算
- 训练AI模型:优先选择显存大(如24GB以上)、支持多卡并行的型号(如NVIDIA A100/H100)。
- 推理任务:注重能效比,可选择T4或A30等中端GPU。
- 图形渲染:需高显存带宽,如NVIDIA RTX 6000 Ada。
- 硬件配置
- GPU型号:根据任务类型选择(计算卡如Tesla系列,图形卡如Quadro系列)。
- CPU与内存:建议搭配多核CPU(如AMD EPYC或Intel Xeon)及大容量内存(≥128GB)。
- 存储与网络:NVMe SSD提升数据读取速度;100Gbps网络避免通信瓶颈。
- 软件生态兼容性
确保GPU支持主流框架(如TensorFlow、PyTorch)及CUDA/cuDNN库,避免开发环境冲突。 - 散热与功耗管理
GPU服务器功耗较高(单卡可达300W以上),需配备冗余电源及液冷/风冷散热系统。
GPU服务器的维护与优化建议
- 定期更新驱动:保持GPU驱动与固件为最新版本,以修复破绽并提升性能。
- 监控资源使用率:通过NVIDIA DCGM或Prometheus工具实时监测GPU温度、显存占用率。
- 任务调度优化:使用Kubernetes或Slurm集群管理工具,合理分配计算资源。
- 数据安全备份:重要模型与数据需定期备份至异地存储,防止硬件故障导致损失。
未来发展趋势
- GPU技术迭代:NVIDIA的Hopper架构、AMD的CDNA架构持续提升算力与能效。
- 量子计算结合:GPU与量子计算机协同,解决更复杂的优化问题。
- 云化与普惠化:云服务商推出按需付费的GPU实例,降低中小企业使用门槛。
GPU服务器已成为驱动数字化转型的核心基础设施,其应用场景正从科研机构延伸至医疗、金融、制造业等领域,企业需结合自身需求选择硬件配置,并通过持续优化释放GPU的潜力,随着AI与算力的进一步发展,GPU服务器将持续推动技术创新与产业升级。
引用说明
本文数据参考自NVIDIA官方技术文档、IDC全球服务器市场报告(2025)、MLPerf基准测试结果,以及行业案例分析,技术细节已通过公开资料验证,确保内容准确性与权威性。