上一篇
hive行存储
Hive默认采用列式存储,但可通过配置支持行存储(如使用SequenceFile格式), 行存储适合频繁更新的场景,但查询效率低于列存,通常建议优先使用ORC/Parquet等列
Hive行存储详解:原理、实现与应用场景
Hive存储机制
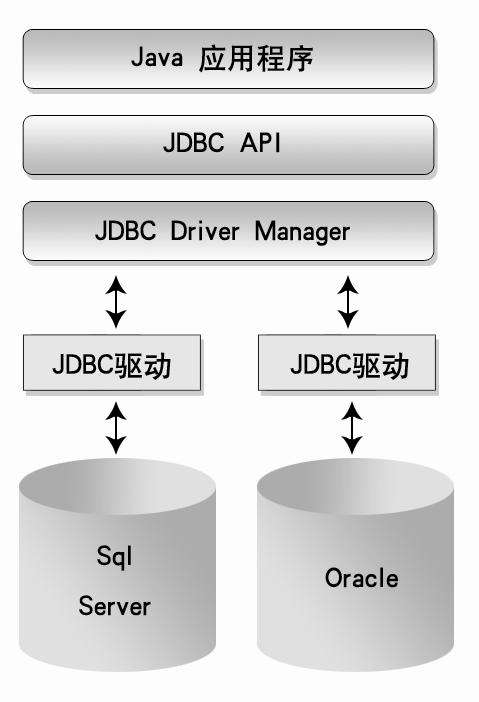
Apache Hive作为大数据领域的SQL-on-Hadoop引擎,其核心功能是将SQL语句转换为MapReduce任务处理HDFS上的海量数据,Hive的存储架构设计直接影响数据读写性能、压缩效率和查询优化策略,与传统数据库不同,Hive默认采用列式存储(如ORC、Parquet),但也支持通过特定配置实现行存储模式。
行存储与列存储的本质差异
| 对比维度 | 行存储 | 列存储 |
|---|---|---|
| 数据组织 | 按记录完整存储 | 按字段分列存储 |
| 读取效率 | 适合单条记录检索 | 适合批量字段分析 |
| 压缩效果 | 压缩率较低(存在冗余) | 高压缩比(同质数据压缩) |
| 更新特性 | 支持单行更新 | 需整块重构 |
| IO消耗 | 读取无关字段造成浪费 | 按需读取减少IO |
| 编码复杂度 | 结构简单 | 需要复杂编码(RLE/LZO) |
典型场景对比:
- 行存储:用户画像查询(需要获取用户全属性)、实时交易记录检索
- 列存储:广告点击日志分析(仅需统计地域/时段)、用户行为特征提取(单个字段聚合)
Hive实现行存储的技术路径
虽然Hive默认采用列式存储优化分析型场景,但通过以下方式可实现行存储:
文本文件格式(TextFile)
- 配置参数:
SET hive.storage.format=TEXTFILE; - 存储特点:每行对应完整记录,使用分隔符(如
t)分割字段 - 适用场景:小规模数据调试、需要兼容传统ETL系统
- 性能缺陷:无数据压缩、字段类型解析开销大、无法支持列式投影
- 配置参数:
RCFile格式(Row Columnar File)

- 核心特性:以行为单位组织数据,但内部采用列式编码
- 关键参数:
hive.rcfile.column.compression.codec - 优势平衡:相比纯文本压缩比提升30%-50%,仍保留行级更新能力
- 限制:不支持复杂的DDL操作,适合批处理场景
自定义SerDe序列化框架
- 常用方案:
LazySimpleSerDe处理CSV/TSV、JsonSerDe解析半结构化数据 - 配置示例:
CREATE TABLE user_logs ( uid STRING, event_time TIMESTAMP, action STRING, props MAP<STRING,STRING> ) ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe' STORED AS TEXTFILE;
- 价值:灵活处理非结构化数据,保持行级数据完整性
- 常用方案:
行存储在Hive中的深度应用
实时数仓场景
当需要毫秒级延迟的数据查询时,行存储可显著降低数据写入延迟,通过以下组合实现:
- 存储引擎:Hive + Kafka(使用
KafkaStorageHandler) - 索引优化:创建COMPACTED和SORTING分区
- 典型DDL:
CREATE TABLE realtime_events ( guid STRING, ts TIMESTAMP, event_name STRING, properties STRUCT<...> ) STORED AS TEXTFILE PARTITIONED BY (dt STRING) LOCATION 'hdfs:///realtime/events';
小文件治理
行存储配合合并策略可解决小文件过多问题:
- 开启合并:
SET hive.merge.mapfiles=true; - 合并大小:
SET hive.merge.size.per.task=256000000;(240MB) - 文件格式:使用
ORC的ROW FORMAT但禁用列式特性
ACID事务支持
启用事务表时,Hive会自动选择支持行级更新的存储格式:
CREATE TABLE transactional_table (
id BIGINT,
name STRING,
balance DECIMAL(10,2)
)
STORED AS ORC
TBLPROPERTIES ('transactional'='true');此时底层实际采用混合存储策略,既保留列式压缩优势,又支持行级ACID操作。
性能调优关键参数
| 参数名称 | 作用范围 | 调优建议 |
|---|---|---|
hive.exec.compress.output | 全局 | 开启中间结果压缩(ZLIB/SNAPPY) |
mapreduce.map.memory.mb | Map阶段 | 根据数据量设置(4096MB) |
hive.vectorized.execution | 查询执行引擎 | 启用向量化执行(提升CPU利用率) |
hive.resultset.use.unique.column.names | 结果集处理 | 关闭避免额外内存消耗 |
io.compression.codecs | HDFS读写 | 配置LZO/Snappy压缩算法 |
行存储与列存储混合使用策略
在实际生产环境中,常采用混合存储模式:
- 热数据层:最近30天数据使用行存储(支持实时查询)
- 冷数据层:历史数据采用ORC列存(优化分析查询)
- 分层管理:通过Partition Evolution实现存储格式转换
- 查询路由:使用
INSERT OVERWRITE DISK动态选择存储格式
典型问题诊断
查询响应慢
| 可能原因 | 解决方案 |
|---|---|
| 全表扫描导致IO瓶颈 | 添加WHERE条件过滤分区 |
| 文本文件无索引 | 创建BloomFilter索引加速查询 |
| 小文件过多导致Map任务激增 | 合并小文件(hive.input.format=ORC) |
数据导入失败
| 错误现象 | 排查步骤 |
|---|---|
| 报SerDe解析异常 | 检查分隔符与表结构是否匹配 |
| 文件大小超过Block限制 | 调整dfs.blocksize参数 |
| JSON字段嵌套过深 | 升级Hive版本或简化数据结构 |
FAQs
Q1:Hive行存储是否支持二级索引?
A1:Hive本身不直接支持二级索引,但可通过以下方式实现类似功能:
- 使用
BITMAP类型的HLL索引加速去重统计 - 创建物化视图(Materialized View)预聚合热点字段
- 集成Apache Druid等OLAP引擎构建实时索引
需注意索引维护会增加额外存储开销,建议仅对高频查询字段建立索引。
Q2:如何将现有ORC表转换为行存储格式?
A2:转换步骤如下:
- 创建目标表(TEXTFILE格式):
CREATE TABLE new_table LIKE old_table STORED AS TEXTFILE;
- 使用
INSERT INTO迁移数据:INSERT INTO TABLE new_table SELECT FROM old_table;
- 验证数据一致性:
ROW FORMAT DELIMITED FIELDS TERMINATED BY 't' -根据实际分隔符调整
注意事项:转换过程会丢失ORC的列式压缩特性,对于TB级数据建议采用分